A Corpus for Modeling Word Importance in Spoken Dialogue Transcripts
Motivated by a project to create a system for people who are deaf or hard-of-hearing that would use automatic speech recognition (ASR) to produce real-time text captions of spoken English during in-person meetings with hearing individuals, we have augmented a transcript of the Switchboard conversational dialogue corpus with an overlay of word-importance annotations, with a numeric score for each word, to indicate its importance to the meaning of each dialogue turn. Further, we demonstrate the utility of this corpus by training an automatic word importance labeling model; our best performing model has an F-score of 0.60 in an ordinal 6-class word-importance classification task with an agreement (concordance correlation coefficient) of 0.839 with the human annotators (agreement score between annotators is 0.89). Finally, we discuss our intended future applications of this resource, particularly for the task of evaluating ASR performance, i.e. creating metrics that predict ASR-output caption text usability for DHH users better thanWord Error Rate (WER).
💡 Research Summary
The paper presents a newly annotated corpus that adds word‑importance scores to the Switchboard conversational speech transcripts, aiming to support the development of real‑time captioning systems for deaf and hard‑of‑hearing (DHH) users. Word importance is defined as the degree to which the omission of a word would impede a reader’s understanding of the utterance’s overall meaning. Annotators assigned a continuous score between 0.0 and 1.0 (in 0.05 increments) to each token, guided by a three‑range rubric (low, medium, high importance). To ensure consistency, two annotators independently labeled 3,100 overlapping tokens, achieving a concordance correlation coefficient (ρc) of 0.89, indicating strong agreement despite the subjective nature of the task.
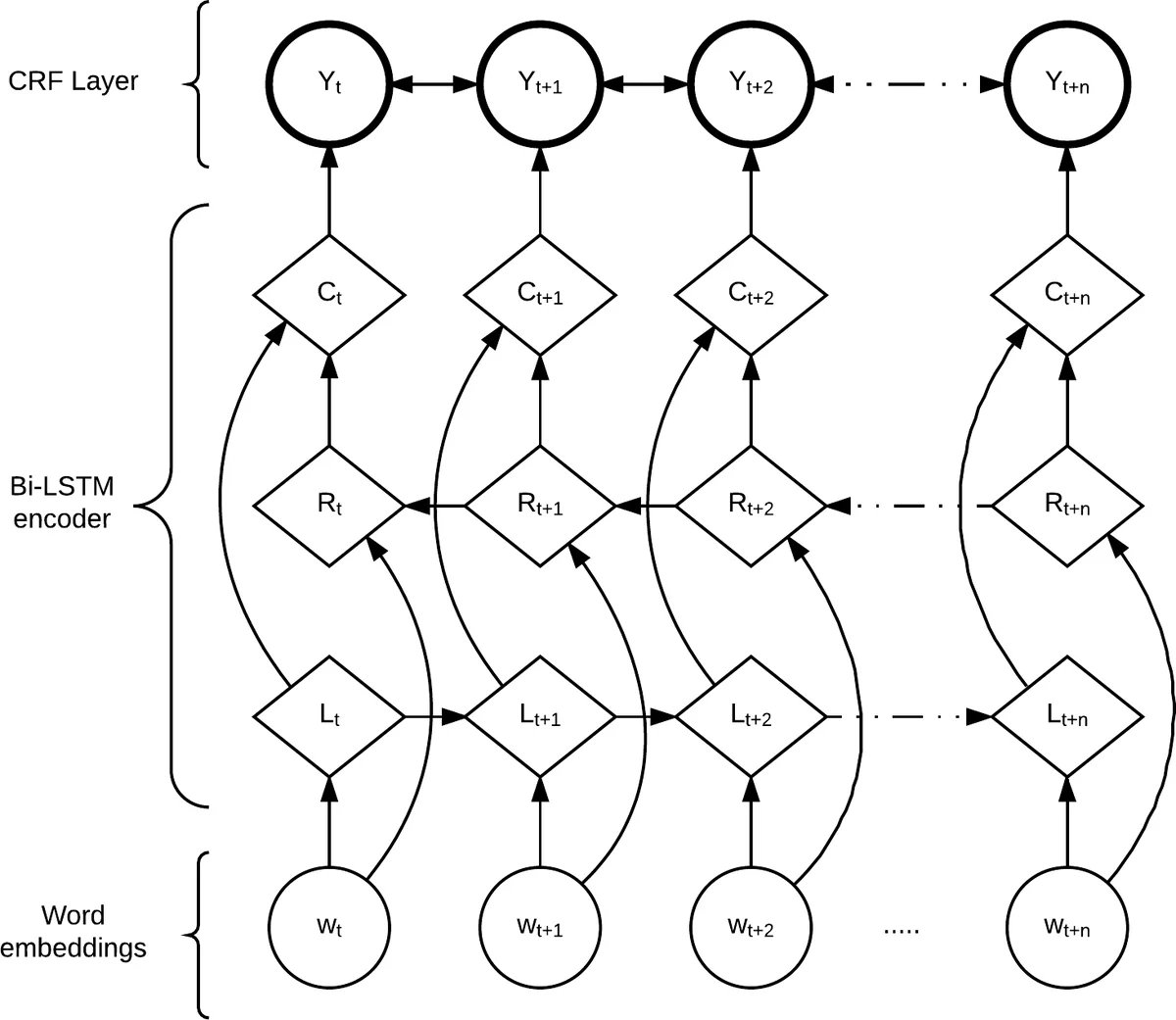
The authors released the first 25,000 annotated tokens (≈3,100 overlapped) aligned with the ISIP transcripts and plan to extend the annotation to the entire Switchboard corpus. Using this resource, they trained two neural models: (i) a bidirectional LSTM with a Conditional Random Field (CRF) output layer (LSTM‑CRF) that treats importance as a six‑class ordinal classification problem, and (ii) a bidirectional LSTM with a sigmoid output layer (LSTM‑SIG) that directly regresses the continuous importance score. Both models use pre‑trained GloVe word embeddings combined with character‑level representations. Training employed an 80/10/10 split, Adam optimization (lr = 0.001, decay = 0.9), and dropout on embeddings.
Evaluation was performed with two metrics: root‑mean‑square error (RMS) for continuous prediction and macro‑averaged F1 for classification. LSTM‑CRF achieved the higher classification performance (F1 = 0.60) but a larger RMS (0.154). LSTM‑SIG yielded a lower RMS (0.120) but a lower F1 (0.519). Concordance correlation between model predictions and human annotations was 0.839 for LSTM‑CRF and 0.826 for LSTM‑SIG, both approaching the inter‑annotator agreement of 0.89. Confusion matrices revealed that both models struggled most with the middle importance range (0.3–0.7), reflecting the inherent ambiguity in human judgments for those scores.
The study’s contributions are threefold: (1) it provides the first large‑scale, continuous‑score word‑importance annotation for spoken dialogue, enabling research on importance‑aware language processing; (2) it demonstrates that neural models can approximate human importance judgments with high correlation, offering practical tools for downstream tasks; and (3) it lays the groundwork for new ASR evaluation metrics that weight errors by word importance, potentially outperforming traditional Word Error Rate (WER) in predicting caption usability for DHH users. Future work includes expanding the annotated corpus, exploring additional model architectures, and integrating the importance scores into an “Importance‑Weighted Error Rate” metric to better reflect real‑world caption quality.
Comments & Academic Discussion
Loading comments...
Leave a Comment