Patterns of Effort Contribution and Demand and User Classification based on Participation Patterns in NPM Ecosystem
Background: Open source requires participation of volunteer and commercial developers (users) in order to deliver functional high-quality components. Developers both contribute effort in the form of patches and demand effort from the component maintainers to resolve issues reported against it. Aim: Identify and characterize patterns of effort contribution and demand throughout the open source supply chain and investigate if and how these patterns vary with developer activity; identify different groups of developers; and predict developers’ company affiliation based on their participation patterns. Method: 1,376,946 issues and pull-requests created for 4433 NPM packages with over 10,000 monthly downloads and full (public) commit activity data of the 272,142 issue creators is obtained and analyzed and dependencies on NPM packages are identified. Fuzzy c-means clustering algorithm is used to find the groups among the users based on their effort contribution and demand patterns, and Random Forest is used as the predictive modeling technique to identify their company affiliations. Result: Users contribute and demand effort primarily from packages that they depend on directly with only a tiny fraction of contributions and demand going to transitive dependencies. A significant portion of demand goes into packages outside the users’ respective supply chains (constructed based on publicly visible version control data). Three and two different groups of users are observed based on the effort demand and effort contribution patterns respectively. The Random Forest model used for identifying the company affiliation of the users gives a AUC-ROC value of 0.68. Conclusion: Our results give new insights into effort demand and supply at different parts of the supply chain of the NPM ecosystem and its users and suggests the need to increase visibility further upstream.
💡 Research Summary
The paper investigates how developers in the Node Package Manager (NPM) ecosystem contribute effort (through pull‑requests) and demand effort (through issues) across different layers of their software supply chains, and whether these participation patterns can be used to classify users and predict their commercial affiliation. The authors formulate four research questions: (RQ1) where in a user’s supply chain do contributions and demands occur; (RQ2) can users be grouped based on these patterns; (RQ3) does the behavior change for “prolific” users (those who have filed at least ten issues); and (RQ4) can participation patterns predict whether a user works for a company.
Data collection focuses on 4,433 popular NPM packages (each with more than 10,000 monthly downloads since January 2018) that have active GitHub repositories. Using the GitHub API, the authors retrieve every issue and pull‑request ever filed against these packages, totaling 1,376,946 items, of which 39 % are pull‑requests. They also collect the public activity of the 272,142 distinct users who created these items. To model a user’s supply chain, the authors define four hierarchical levels: Level 0 – packages the user directly commits to; Level 1 – packages that are direct dependencies of any repository the user has committed to (including forks); Level 2+ – transitive dependencies of Level 1 packages; and Level X – all other NPM packages that do not appear in the user’s publicly visible dependency graph. Issues are treated as “effort demand” and pull‑requests as “effort contribution.”
Descriptive analysis shows that the overwhelming majority of both issues and pull‑requests are directed at Level 0 and Level 1 packages. Contributions to Level 2+ (transitive) and Level X (outside the visible supply chain) account for less than 5 % of all activity, indicating that developers have limited visibility beyond their immediate dependencies.
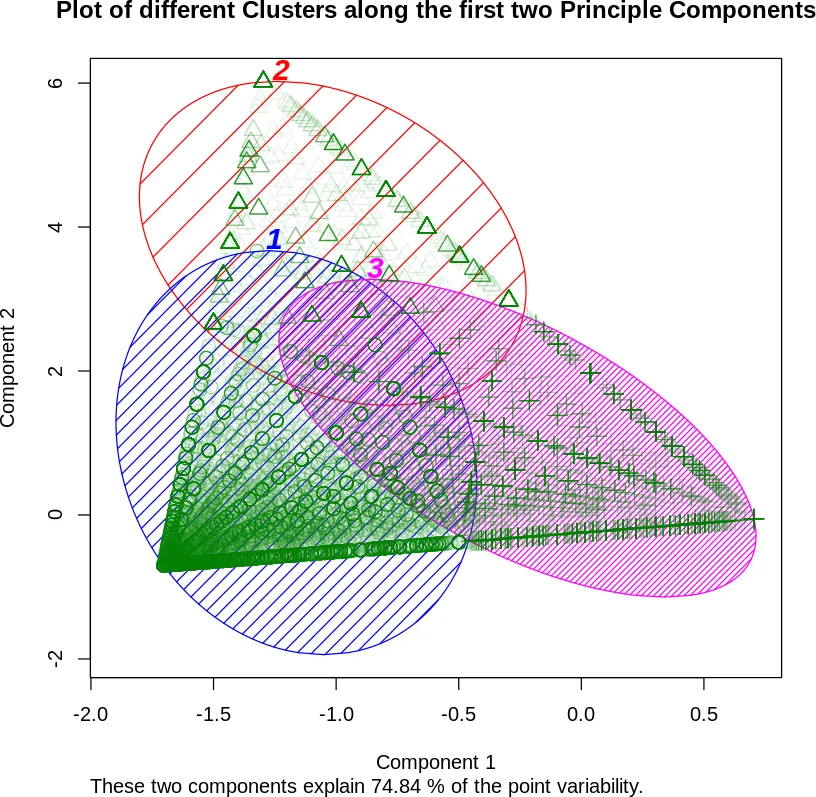
For clustering, the authors apply fuzzy C‑means to the normalized fractions of effort demand and effort contribution across the four levels. The demand‑based clustering yields three distinct user groups: (1) users who mainly file issues against their direct dependencies; (2) users who file issues against packages outside their supply chain; and (3) a small group that creates cross‑project issues (i.e., issues in Level 2+). The contribution‑based clustering produces two groups that mirror the first two demand groups (direct‑dependency contributors and outside‑supply‑chain contributors). When the analysis is restricted to prolific users, the same patterns become more pronounced: prolific users are even more concentrated on Level 0/1 activity and even less likely to engage with Level X packages.
To address RQ4, the authors train a Random Forest classifier using features derived from the participation patterns (e.g., proportion of issues/pull‑requests per level, total activity count, prolific flag). The model is evaluated with ten‑fold cross‑validation, achieving an average accuracy of 70 % (95 % confidence interval 69.9 %–70.5 %) and an area under the ROC curve (AUC) of 0.68. This demonstrates that while participation patterns provide a signal for commercial affiliation, they are not sufficient for high‑precision classification on their own.
The paper discusses several limitations. First, GitHub profiles are optional for declaring employer information, so many users may be mis‑labelled as non‑commercial. Second, the Level X definition relies on publicly visible repositories; private or internal dependencies are invisible, potentially biasing the analysis. Third, the study is confined to NPM and does not consider other JavaScript package managers (e.g., Yarn, pnpm) or other language ecosystems, limiting generalizability. Finally, the Random Forest model, while effective, offers limited interpretability regarding which specific behavioral cues drive the prediction.
In conclusion, the study provides a quantitative view of effort flow in a large OSS ecosystem, revealing that most developer activity stays within the immediate dependency graph, that distinct user groups can be identified based on where they request or provide effort, and that these patterns can modestly predict corporate affiliation. The findings have practical implications: improving tooling to increase visibility of transitive dependencies could encourage broader community involvement and reduce supply‑chain risk; understanding user groups can help maintainers prioritize outreach; and predictive models could assist platforms lacking explicit employer data to infer commercial participation. Future work is suggested in (a) developing visualization and recommendation tools to raise awareness of upstream packages, (b) extending the analysis to security‑related metrics in transitive dependencies, and (c) integrating additional data sources (e.g., commit messages, network centrality) to enhance the accuracy of commercial affiliation prediction.
Comments & Academic Discussion
Loading comments...
Leave a Comment