Understanding Deep Learning Techniques for Image Segmentation
The machine learning community has been overwhelmed by a plethora of deep learning based approaches. Many challenging computer vision tasks such as detection, localization, recognition and segmentation of objects in unconstrained environment are being efficiently addressed by various types of deep neural networks like convolutional neural networks, recurrent networks, adversarial networks, autoencoders and so on. While there have been plenty of analytical studies regarding the object detection or recognition domain, many new deep learning techniques have surfaced with respect to image segmentation techniques. This paper approaches these various deep learning techniques of image segmentation from an analytical perspective. The main goal of this work is to provide an intuitive understanding of the major techniques that has made significant contribution to the image segmentation domain. Starting from some of the traditional image segmentation approaches, the paper progresses describing the effect deep learning had on the image segmentation domain. Thereafter, most of the major segmentation algorithms have been logically categorized with paragraphs dedicated to their unique contribution. With an ample amount of intuitive explanations, the reader is expected to have an improved ability to visualize the internal dynamics of these processes.
💡 Research Summary
The paper “Understanding Deep Learning Techniques for Image Segmentation” offers a broad, narrative‑style survey of image segmentation methods, tracing the evolution from classical, hand‑crafted approaches to the modern deep‑learning era. It begins by defining image segmentation as the pixel‑wise assignment of semantic labels and distinguishes several sub‑tasks such as semantic segmentation, instance segmentation, saliency detection, foreground‑background separation, and temporal (video) segmentation. The authors enumerate a wide variety of traditional techniques—histogram thresholding, region‑growing, edge‑based methods, clustering in feature space, fuzzy logic, physics‑based models, and early neural networks (e.g., Hopfield, SOM)—and point out their reliance on expert‑designed features, which limits their ability to capture abstract or latent patterns.
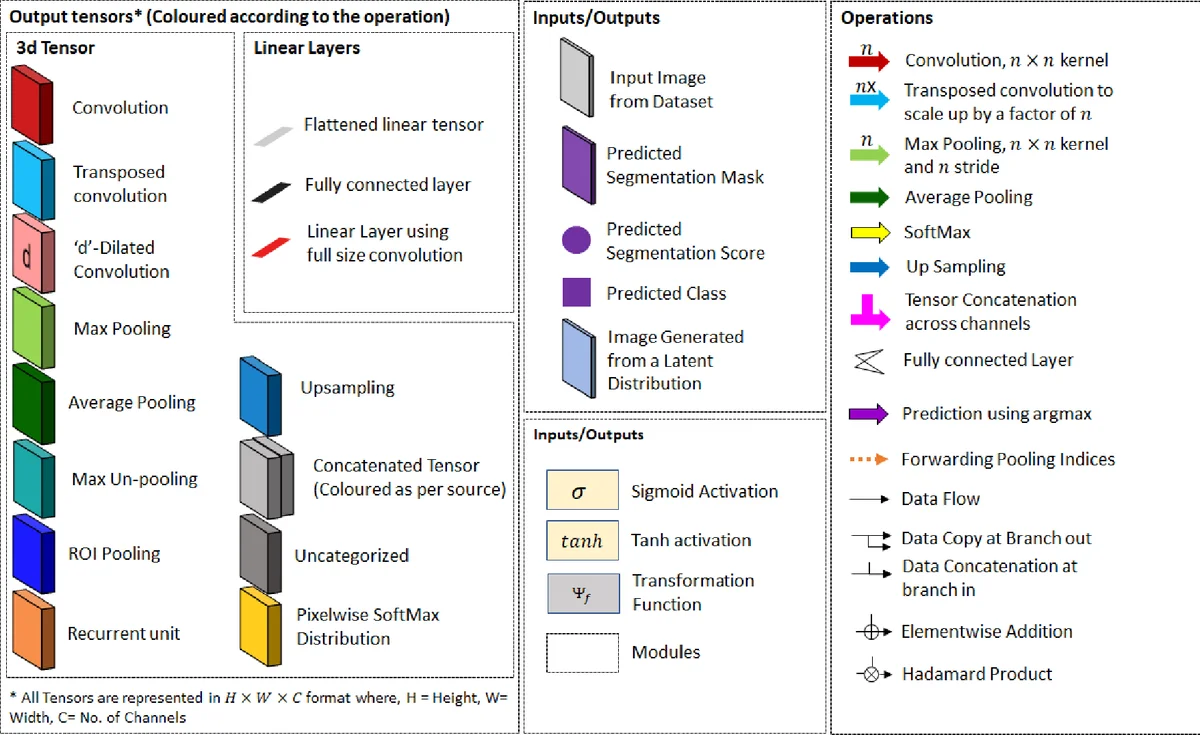
The core of the manuscript is devoted to deep learning. The authors first explain why convolutional neural networks (CNNs) are naturally suited for segmentation: the convolution operation produces activation maps that preserve spatial information, and deeper layers learn increasingly global, semantic cues. They illustrate this with a figure showing early layers responding to edges or small parts and later layers responding to whole objects such as “sky” or “person.” From this foundation, the paper categorizes the major families of deep segmentation architectures that have emerged over roughly the last decade:
-
Fully Convolutional Networks (FCNs) – The seminal FCN replaces fully‑connected layers with 1×1 convolutions, enabling end‑to‑end pixel‑wise classification. The authors cite the original FCN results on PASCAL VOC (≈90 % pixel accuracy, 62.7 % mean IoU).
-
Encoder‑Decoder (U‑Net, SegNet, ENet, etc.) – These models downsample to capture high‑level context and then upsample, often using skip connections, to recover fine‑grained details. U‑Net’s symmetric skip connections are highlighted for biomedical segmentation, while ENet is praised for real‑time performance.
-
Multi‑Scale and Attention‑Based Designs – PSPNet’s pyramid pooling, DeepLab’s atrous spatial pyramid pooling (ASPP), and “Attention‑to‑Scale” are discussed as ways to aggregate context at multiple receptive fields. The “Large Kernel Matters” paper is mentioned for demonstrating that bigger kernels can learn more complex patterns.
-
Instance‑Aware and Region‑Proposal Methods – Techniques such as DeepMask, SharpMask, Mask RCNN, and Instance‑aware segmentation are described. They combine object detection pipelines (region proposal networks) with mask prediction, enabling simultaneous detection and instance segmentation.
-
Hybrid and Advanced Modules – The survey lists CRF‑RNN (learning Conditional Random Fields as recurrent layers), Spatial Propagation Networks (linear label propagation), Capsule Networks for segmentation (SegCaps), adversarial training (Conditional GANs for image‑to‑segmentation translation), and interactive methods (Extreme Cut, Superpixel Supervision). Each is briefly characterized by its supervision type (fully supervised, weakly supervised, unsupervised, interactive), optimization strategy (single‑objective, multi‑objective, adversarial), and target segmentation type (semantic, class‑specific, instance).
A comprehensive table (Table 2) maps each method to its year, supervision level, learning type, key modules, and a one‑sentence description, providing a quick reference for researchers.
The paper also compiles an extensive list of benchmark datasets (Table 1), covering natural scenes (PASCAL VOC, MS‑COCO, Cityscapes, Mapillary Vistas), medical imaging (DRIVE, LITS, BACH), aerial and satellite imagery (Inria Aerial, ISPRS, DeepGlobe), and saliency datasets (MSRA, ECSSD). This underscores the data‑driven nature of modern segmentation research and the importance of domain‑specific challenges.
In the discussion, the authors argue that deep learning has fundamentally altered segmentation by (a) learning hierarchical features automatically, (b) leveraging massive annotated corpora, and (c) inspiring a proliferation of architectural variants. They also note that many methods reuse the same underlying components (convolutions, atrous convolutions, skip connections, CRFs) but differ in how they combine them, the loss functions employed, and the degree of supervision.
Critical appraisal: While the survey is thorough in breadth, it lacks quantitative comparisons under a unified evaluation protocol; performance numbers are quoted from original papers, making it hard to assess relative merits. The review stops at 2019 and omits recent transformer‑based segmentation models (e.g., Vision Transformer‑Seg, Segmenter) and newer lightweight real‑time networks (e.g., HRNet, DeepLab v3+). Moreover, the “why” of each design choice is explained mostly at an intuitive level without mathematical justification or ablation studies, limiting its utility for researchers aiming to design novel architectures. The paper also does not discuss training tricks such as mixed‑precision, large‑scale pre‑training, or self‑supervised pre‑training, which have become pivotal in recent years.
Conclusion: The manuscript serves as an accessible entry point for newcomers to deep learning‑based image segmentation, offering a clear taxonomy, visual intuition, and a handy reference of datasets and methods. However, for advanced researchers, the lack of up‑to‑date coverage, detailed empirical analysis, and rigorous design rationale means the survey should be complemented with more recent literature and hands‑on experiments.
Comments & Academic Discussion
Loading comments...
Leave a Comment