Joint Speech Recognition and Speaker Diarization via Sequence Transduction
Speech applications dealing with conversations require not only recognizing the spoken words, but also determining who spoke when. The task of assigning words to speakers is typically addressed by merging the outputs of two separate systems, namely, an automatic speech recognition (ASR) system and a speaker diarization (SD) system. The two systems are trained independently with different objective functions. Often the SD systems operate directly on the acoustics and are not constrained to respect word boundaries and this deficiency is overcome in an ad hoc manner. Motivated by recent advances in sequence to sequence learning, we propose a novel approach to tackle the two tasks by a joint ASR and SD system using a recurrent neural network transducer. Our approach utilizes both linguistic and acoustic cues to infer speaker roles, as opposed to typical SD systems, which only use acoustic cues. We evaluated the performance of our approach on a large corpus of medical conversations between physicians and patients. Compared to a competitive conventional baseline, our approach improves word-level diarization error rate from 15.8% to 2.2%.
💡 Research Summary
The paper addresses the long‑standing problem of jointly recognizing spoken words and assigning them to the correct speakers in multi‑speaker conversations, a task traditionally tackled by cascading separate automatic speech recognition (ASR) and speaker diarization (SD) systems. The conventional pipeline consists of three stages: (1) ASR produces a transcript, (2) an independent SD module partitions the audio into speaker‑labeled segments, and (3) a post‑processing step aligns the two outputs. This separation leads to several inefficiencies: the ASR and SD models are trained with different objectives, the SD component typically relies solely on acoustic cues and ignores word boundaries, and the reconciliation step introduces additional errors, especially when speaker changes occur inside a word.
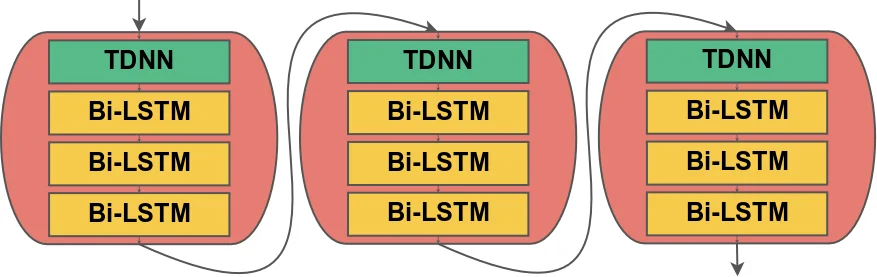
Motivated by recent advances in end‑to‑end sequence transduction, the authors propose a unified model that simultaneously performs ASR and SD using a Recurrent Neural Network Transducer (RNN‑T). The key idea is to augment the output vocabulary with special speaker‑role tokens (e.g., spk:dr for doctor, spk:pt for patient). During inference the model emits a sequence that interleaves spoken words (represented as morphemes) and speaker‑role markers, thereby directly producing a “speaker‑decorated transcript”. This formulation eliminates the need for a separate diarization front‑end, allows the model to exploit both acoustic and linguistic information, and guarantees that speaker labels are aligned with word boundaries.
Technical implementation details are as follows. Audio is represented by 80‑dimensional log‑mel filterbank features. The encoder (transcription network) consists of three blocks, each containing a 1‑D convolution (512 filters, kernel size 5, stride 2) followed by three bidirectional LSTM layers (512 units each). This architecture reduces the time resolution from 10 ms to 80 ms, making training more efficient. The prediction network embeds the morpheme vocabulary (≈4 K tokens) into a 512‑dimensional space, processes it with a unidirectional LSTM (1024 units) and a fully‑connected layer (512 units). The joint network combines encoder and predictor representations, and a softmax layer yields probabilities over the extended output set (words, punctuation, and speaker tokens). Training uses the RNN‑T loss, computed via a forward‑backward dynamic programming algorithm that marginalizes over all possible alignments; the authors employ a TPU‑friendly implementation that recasts the computation as matrix multiplications. Optimization is performed with Adam on 128 TPUs, converging within two days.
The experimental corpus comprises roughly 100 K manually transcribed medical conversations (≈15 000 hours) between physicians and patients, with an average duration of ten minutes per session. Each turn in the reference transcription is labeled with a speaker role; for speakers other than doctor or patient, the authors map them to the nearest role (e.g., nurses → doctor). The data is split into training, development (508 conversations), and test (404 conversations) sets, ensuring no physician overlap across splits. Audio quality varies widely (different microphones, codecs, 8 kHz/16 kHz sampling).
Evaluation introduces a novel metric, Word Diarization Error Rate (WDER), which measures the proportion of words whose associated speaker token is incorrect, accounting separately for ASR substitution errors and speaker‑label errors. WDER is defined as (S_IS + C_IS) / (S + C), where S_IS and C_IS denote ASR substitution and correct‑word counts with wrong speaker tags, respectively, while S and C are total substitution and correct‑word counts. This metric directly reflects the performance of an end‑to‑end system, unlike the traditional time‑based Diarization Error Rate (DER) that requires aligning speaker segments with word timestamps.
For baseline comparison, the authors construct two systems. The first is an RNN‑T ASR model identical in architecture to the proposed model but without speaker tokens, representing a strong end‑to‑end ASR baseline. The second is a conventional five‑stage SD pipeline: (a) an LSTM‑based voice activity detector, (b) a sliding‑window LSTM speaker‑embedding extractor (trained with VoxCeleb2 augmentation), (c) cosine‑distance based speaker‑change detection, (d) k‑means clustering (k = 2) to assign speaker IDs, and (e) a heuristic alignment of ASR word timestamps with speaker turn boundaries. The baseline’s speaker IDs are generic (spk:0, spk:1) and are mapped back to doctor/patient roles per conversation to minimize diarization errors, giving the baseline an advantage.
Results show a dramatic reduction in WDER: the baseline achieves 15.8 % while the joint RNN‑T model attains 2.2 %, an 86 % relative improvement. The joint model incurs only a modest 0.6 % increase in word error rate (WER) compared to the ASR‑only RNN‑T baseline, indicating that the added speaker‑role prediction does not substantially degrade transcription quality. The authors attribute the WDER gain to the elimination of separate speaker‑turn boundary estimation and the direct use of linguistic cues (e.g., doctors tend to ask questions, patients provide answers), which are unavailable to acoustic‑only diarization systems.
In discussion, the paper highlights several advantages of the proposed approach: (1) unified training aligns acoustic and linguistic objectives, (2) no need for post‑processing alignment or clustering, (3) real‑time inference is feasible because the model is a single neural network, and (4) the method naturally extends to domains where speaker roles are strongly correlated with language patterns. Limitations include the focus on binary‑role conversations; extending to more than two speakers or to settings where roles are ambiguous will require richer token sets and possibly hierarchical role modeling. Future work suggested includes incorporating additional non‑verbal cues (prosody, energy), exploring multi‑task learning for emotion or intent detection, and evaluating on other domains such as meetings, broadcast news, or legal proceedings.
Overall, the paper demonstrates that end‑to‑end sequence transduction with role‑aware output vocabularies can substantially improve speaker‑aware transcription, offering a compelling alternative to the traditional ASR + SD pipeline, especially in applications where speaker roles are semantically meaningful.
Comments & Academic Discussion
Loading comments...
Leave a Comment