Identifying Algorithm Names in Code Comments
For recent machine-learning-based tasks like API sequence generation, comment generation, and document generation, large amount of data is needed. When software developers implement algorithms in code, we find that they often mention algorithm names in code comments. Code annotated with such algorithm names can be valuable data sources. In this paper, we propose an automatic method of algorithm name identification. The key idea is extracting important N-gram words containing the word `algorithm’ in the last. We also consider part of speech patterns to derive rules for appropriate algorithm name identification. The result of our rule evaluation produced high precision and recall values (more than 0.70). We apply our rules to extract algorithm names in a large amount of comments from active FLOSS projects written in seven programming languages, C, C++, Java, JavaScript, Python, PHP, and Ruby, and report commonly mentioned algorithm names in code comments.
💡 Research Summary
The paper addresses the growing need for large‑scale annotated data in machine‑learning tasks such as API sequence generation, comment generation, and document generation. The authors observe that developers frequently mention algorithm names directly in source‑code comments, for example “Insertion Sort algorithm”. These mentions can serve as a valuable source of weakly labeled data. The study proposes an automatic method to identify algorithm names within code comments across seven popular programming languages (C, C++, Java, JavaScript, Python, PHP, and Ruby).
Methodology
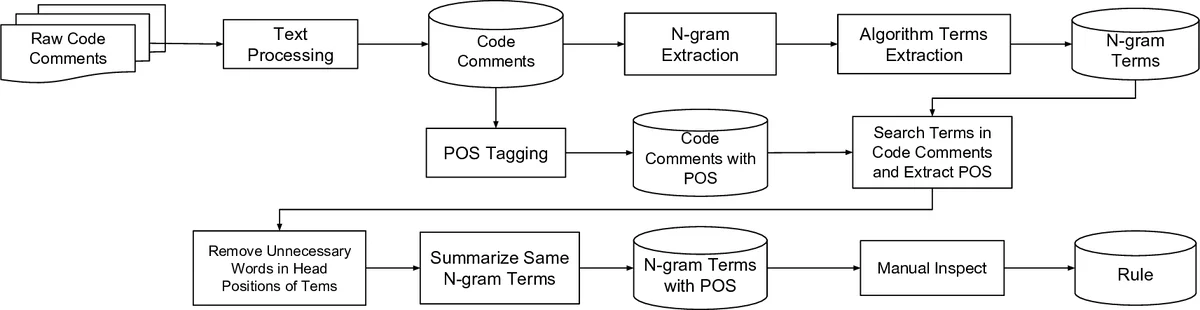
The approach consists of four main stages:
-
Data collection and preprocessing – The authors harvested code comments from thousands of FLOSS repositories on GitHub that satisfy activity thresholds (≥500 total commits and ≥100 commits in the last two years). Special characters (e.g., ‘*’, ‘#’, ‘/’) are stripped, and the remaining comment text is tokenized and part‑of‑speech (POS) tagged using the spaCy library.
-
N‑gram extraction with N‑gram IDF – Inspired by Shirakawa’s N‑gram IDF (an extension of classic TF‑IDF), the pipeline extracts all N‑grams that end with the literal word “algorithm”. This yields candidate phrases such as “quick sort algorithm”, “search algorithm”, or “blur algorithm”. The IDF weighting helps surface relatively rare but informative N‑grams.
-
Head‑word pruning – The authors define a set of “unnecessary head words” (verbs, prepositions, numbers, determiners, etc.) that cannot be part of a legitimate algorithm name. Using POS tags, they recursively remove these leading tokens from each candidate N‑gram. When multiple overlapping candidates exist (e.g., “quick sort algorithm” vs. “sort algorithm”), the longest remaining phrase is retained.
-
Rule generation (Inclusive vs. Exclusive) – For each pruned N‑gram, the majority POS pattern among its occurrences is computed. The authors manually label a subset of candidates as valid or invalid, then derive two rule families:
- Inclusive rules – If the majority of occurrences are labeled valid, any unlabeled instance matching the same POS pattern is automatically accepted as a valid algorithm name.
- Exclusive rules – If the majority are invalid, matching unlabeled instances are rejected.
Algorithm 1 in the paper codifies these decisions, handling patterns such as “NOUN NOUN”, “ADJ NOUN”, “ADV ADP NOUN”, etc. The rule set does not rely on a predefined list of algorithm names, making it language‑agnostic and robust to emerging terminology.
Evaluation
A preliminary dataset comprising 1,581 N‑gram candidates (458 distinct after deduplication) was manually annotated to serve as an oracle. Applying the generated rules yielded:
- Precision = 0.76
- Recall = 0.70
- F‑measure = 0.73
These figures exceed the 0.70 threshold set by the authors and demonstrate that the combination of N‑gram IDF and POS‑based filtering can reliably separate true algorithm mentions from noise (e.g., “learning algorithm”, “legacy algorithm”).
Large‑Scale Application
The method was run on the full FLOSS corpus, extracting algorithm mentions from:
- C (2,771 repositories)
- C++ (3,563)
- Java (4,995)
- JavaScript (7,130)
- Python (5,263)
- Ruby (2,233)
- PHP (3,279)
The top‑10 most frequent algorithm names per language were reported (Table 5). Common themes include:
- Search‑related algorithms – Dominant in Java, Ruby, PHP, C, and JavaScript.
- Encryption/Hash algorithms – Prominent in Java, Ruby, Python, PHP, and C.
- Sorting and parsing – Appear across most languages.
The authors also present concrete comment excerpts (Table 6) illustrating real‑world usage, e.g., “/* Encryption Algorithm for Unicast Packet */” in a C file, or “# Enable Nagle’s algorithm for proxies” in Python. These examples confirm that the extracted algorithm names can be linked back to actual implementation code, opening the door to automated dataset creation for downstream ML tasks.
Related Work & Threats to Validity
The paper situates itself among prior studies on code comment usefulness, comment quality assessment, and automatic comment generation. It highlights that, unlike earlier work focusing on comment classification, this study specifically mines algorithm terminology. Threats to internal validity stem from rule creation based on a limited preliminary dataset, which might not capture all linguistic variations. External validity is limited by the exclusive focus on GitHub FLOSS projects; results may not generalize to proprietary or industry codebases. The authors mitigate these concerns by demonstrating consistent precision on the large‑scale run.
Contributions
- A novel, language‑independent pipeline for algorithm name identification in source‑code comments.
- Empirical evidence that N‑gram IDF combined with POS‑based inclusive/exclusive rules achieves >0.70 precision, recall, and F‑measure.
- A comprehensive, cross‑language analysis of algorithm usage patterns in millions of FLOSS comments, revealing practical trends (security‑focused algorithms in C, web‑related algorithms in JavaScript/PHP, etc.).
Future Directions
Potential extensions include:
- Building a curated taxonomy of algorithm names to further improve recall.
- Adapting the pipeline to multilingual comments (e.g., Japanese, Chinese).
- Leveraging the extracted pairs (algorithm name ↔ code snippet) to train models for automatic comment generation, code search, or educational tools.
In summary, the paper delivers a practical, empirically validated method for harvesting algorithm names from code comments, thereby providing a scalable source of weak supervision for various software‑engineering machine‑learning applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment