Multi-layer Attention Mechanism for Speech Keyword Recognition
As an important part of speech recognition technology, automatic speech keyword recognition has been intensively studied in recent years. Such technology becomes especially pivotal under situations with limited infrastructures and computational resources, such as voice command recognition in vehicles and robot interaction. At present, the mainstream methods in automatic speech keyword recognition are based on long short-term memory (LSTM) networks with attention mechanism. However, due to inevitable information losses for the LSTM layer caused during feature extraction, the calculated attention weights are biased. In this paper, a novel approach, namely Multi-layer Attention Mechanism, is proposed to handle the inaccurate attention weights problem. The key idea is that, in addition to the conventional attention mechanism, information of layers prior to feature extraction and LSTM are introduced into attention weights calculations. Therefore, the attention weights are more accurate because the overall model can have more precise and focused areas. We conduct a comprehensive comparison and analysis on the keyword spotting performances on convolution neural network, bi-directional LSTM cyclic neural network, and cyclic neural network with the proposed attention mechanism on Google Speech Command datasets V2 datasets. Experimental results indicate favorable results for the proposed method and demonstrate the validity of the proposed method. The proposed multi-layer attention methods can be useful for other researches related to object spotting.
💡 Research Summary
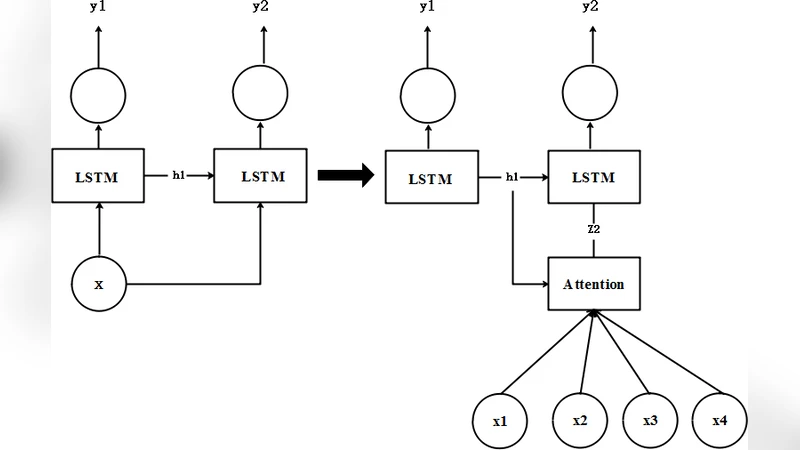
The paper addresses the challenge of accurate and computationally efficient keyword spotting (KWS) for speech interfaces that must operate on devices with limited resources, such as in‑vehicle assistants or robots. While recent KWS systems have largely relied on long short‑term memory (LSTM) networks augmented with a single‑layer attention mechanism, the authors argue that this design suffers from two fundamental problems. First, the convolutional front‑end that extracts low‑level acoustic features inevitably discards information that could be useful for attention weighting. Second, because attention is computed only on the LSTM hidden states, the resulting weights become biased toward patterns that survive the LSTM’s temporal compression, potentially overlooking salient phonetic cues.
To remedy these issues, the authors propose a Multi‑layer Attention Mechanism (MAM). The core idea is to compute attention scores at three distinct stages of the model: (1) the raw convolutional feature map, (2) the bidirectional LSTM hidden representations, and (3) the final classification layer. Each stage passes through a lightweight linear projection followed by a sigmoid activation, yielding a per‑time‑step relevance score in the range
Comments & Academic Discussion
Loading comments...
Leave a Comment