Bi-objective Optimisation of Data-parallel Applications on Heterogeneous Platforms for Performance and Energy via Workload Distribution
Performance and energy are the two most important objectives for optimisation on modern parallel platforms. Latest research demonstrated the importance of workload distribution as a decision variable in the bi-objective optimisation for performance and energy on homogeneous multicore clusters. We show in this work that bi-objective optimisation for performance and energy on heterogeneous processors results in a large number of Pareto-optimal optimal solutions (workload distributions) even in the simple case of linear performance and energy profiles. We then study performance and energy profiles of real-life data-parallel applications and find that their shapes are non-linear, complex and non-smooth. We, therefore, propose an efficient and exact global optimisation algorithm, which takes as an input most general discrete performance and dynamic energy profiles of the heterogeneous processors and solves the bi-objective optimisation problem. The algorithm is also used as a building block to solve the bi-objective optimisation problem for performance and total energy. We also propose a novel methodology to build discrete dynamic energy profiles of individual computing devices, which are input to the algorithm. The methodology is based purely on system-level measurements and addresses the fundamental challenge of accurate component-level energy modelling of a hybrid data-parallel application running on a heterogeneous platform integrating CPUs and accelerators. We experimentally validate the proposed method using two data-parallel applications, matrix multiplication and 2D fast Fourier transform (2D-FFT).
💡 Research Summary
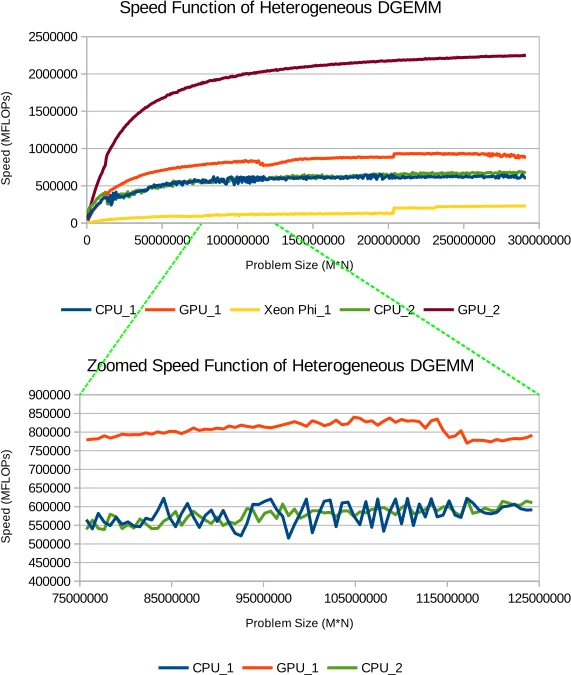
The paper addresses the simultaneous minimization of execution time and dynamic energy consumption for data‑parallel applications running on heterogeneous platforms that combine CPUs, GPUs, and Xeon Phi accelerators. While prior work has largely focused on system‑level knobs such as DVFS or on single‑objective optimization, this study treats workload distribution across the heterogeneous devices as the primary decision variable in a true bi‑objective formulation. The authors first prove that even with simple linear performance and energy models, the Pareto front becomes a straight line containing infinitely many optimal solutions, most of which are load‑imbalanced. This theoretical insight motivates a deeper investigation of real applications whose performance and energy curves are highly non‑linear and non‑smooth.
Two heterogeneous testbeds are used: HCLServer01 (Haswell CPU, Nvidia K40c GPU, Xeon Phi 3120P) and HCLServer02 (Skylake CPU, Nvidia P100 GPU). Each device group is abstracted as a single “processor” to capture resource contention while keeping kernels loosely coupled. The authors devise a system‑level methodology that measures total power with external meters, subtracts static power, and builds discrete dynamic‑energy functions for each abstract processor. No on‑chip sensors are required, yet the resulting profiles are accurate enough for optimization.
With these discrete speed and energy profiles, the authors introduce HEPOPT‑A, an exact global optimization algorithm that enumerates all feasible workload partitions and constructs the full Pareto front for the two objectives. Experiments on a dense matrix multiplication (DGEMM) and a 2‑D FFT reveal rich Pareto sets: 68 solutions for a DGEMM workload and 18 for the FFT. The best‑performance solutions achieve the lowest execution times but consume substantially more energy, while the minimum‑energy solutions increase runtime by up to 92 %. Importantly, the load‑balanced point appears as just one of many Pareto points; the majority of optimal solutions are deliberately load‑imbalanced, demonstrating that traditional load‑balancing heuristics miss a large portion of the optimal trade‑off space.
The paper also shows that the same algorithm can be extended to optimize total energy (dynamic + static) without modification. Overall, the contributions are: (1) a theoretical and empirical demonstration that workload distribution dramatically expands the Pareto frontier on heterogeneous systems, (2) an exact, efficient algorithm that works with arbitrary discrete performance and energy profiles, and (3) a practical, measurement‑only method for constructing those profiles. These results have immediate relevance for energy‑aware schedulers, heterogeneous cluster managers, and future power‑conscious HPC and cloud runtimes.
Comments & Academic Discussion
Loading comments...
Leave a Comment