A Unified Framework of Online Learning Algorithms for Training Recurrent Neural Networks
We present a framework for compactly summarizing many recent results in efficient and/or biologically plausible online training of recurrent neural networks (RNN). The framework organizes algorithms according to several criteria: (a) past vs. future facing, (b) tensor structure, (c) stochastic vs. deterministic, and (d) closed form vs. numerical. These axes reveal latent conceptual connections among several recent advances in online learning. Furthermore, we provide novel mathematical intuitions for their degree of success. Testing various algorithms on two synthetic tasks shows that performances cluster according to our criteria. Although a similar clustering is also observed for gradient alignment, alignment with exact methods does not alone explain ultimate performance, especially for stochastic algorithms. This suggests the need for better comparison metrics.
💡 Research Summary
This paper presents a unifying framework that systematically categorizes and analyzes a broad spectrum of recent online learning algorithms for recurrent neural networks (RNNs). The authors argue that while back‑propagation through time (BPTT) combined with stochastic gradient descent (SGD) remains the de‑facto standard for training RNNs, it requires unrolling the network over a time horizon T, leading to computational and memory costs that scale with T. In contrast, biological learning appears to operate online, updating synaptic strengths in real time without explicit storage of past states. This motivates the study of online algorithms that can train RNNs as they process data.
The core theoretical contribution is a decomposition of the total gradient ∂L/∂w into two complementary perspectives: past‑facing (PF) and future‑facing (FF). In the PF view, the gradient at the current time step is the sum of influences from all past parameter applications; mathematically this corresponds to the classic Real‑Time Recurrent Learning (RTRL) recursion M(t)=J(t)M(t‑1)+M(t), where M(t)=∂a(t)/∂w captures the influence of parameters on the hidden state. In the FF view, the gradient is expressed as the sum of future losses affected by the current parameter, leading to a recursion on the credit‑assignment vector c(t)=∂L/∂a(t). Both recursions have identical algebraic form, differing only in the direction of time and the object being propagated.
Using these two axes, the authors introduce four orthogonal classification criteria: (a) PF vs. FF, (b) tensor structure of the influence representation (full influence matrix/tensor versus low‑rank decompositions), (c) stochastic versus deterministic update rules, and (d) closed‑form analytical updates versus numerical approximations. Table 1 enumerates a comprehensive list of recent online algorithms—including RTRL, Unbiased Online Recurrent Optimization (UORO), Kronecker‑Factored RTRL (KF‑RTRL), Reverse KF‑RTRL, Kernel RNN Learning (KeRNL), Random Feedback Online Learning (RFLO), and variants of BPTT such as e‑BPTT and f‑BPTT—along these dimensions.
A central insight is that many of these methods can be interpreted as approximations to RTRL obtained by factorizing the influence tensor M(t) into products of lower‑order tensors A(t) and B(t). For example, UORO approximates M(t) as a rank‑1 outer product A(t)B(t), reducing memory from O(n³) to O(n²). KF‑RTRL employs a Kronecker‑product decomposition A(t)⊗B(t), while KeRNL and RFLO use factorizations of the form A(t)ᵏB(t)ᵢⱼ. These factorizations enable online updates with substantially lower computational overhead, at the cost of introducing bias or variance depending on whether the update is deterministic or stochastic.
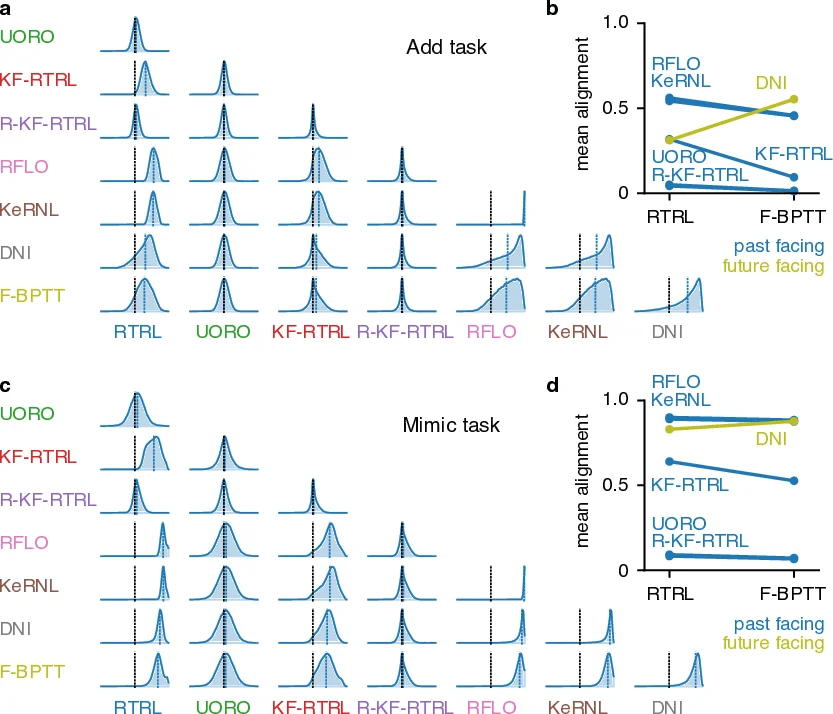
To empirically validate the framework, the authors evaluate all listed algorithms on two synthetic tasks using a vanilla RNN: (1) a delayed‑copy task that requires remembering inputs over a long horizon, and (2) a counter‑based sequence generation task. Across both tasks, performance clusters strongly according to the four criteria. Past‑facing, deterministic, closed‑form methods (e.g., RTRL, KF‑RTRL) achieve stable convergence and low final loss, whereas future‑facing, stochastic, numerical methods (e.g., DNI, stochastic UORO variants) often converge quickly but display higher variance and poorer asymptotic performance.
A notable finding is that gradient alignment—measured as the cosine similarity between an algorithm’s estimated gradient and the exact gradient from BPTT or RTRL—does not reliably predict final performance, especially for stochastic algorithms. High alignment can coexist with unstable learning, suggesting that alignment alone is insufficient as a metric for comparing online methods. The authors therefore advocate for richer evaluation criteria that capture robustness to noise, memory efficiency, and biological plausibility.
Finally, the paper highlights unexplored regions of the classification space, proposing new factorization schemes (e.g., A(t)ᵏB(t)ᵏ) that could balance memory usage, computational cost, and approximation fidelity. By mapping existing algorithms onto a clear, multidimensional taxonomy, the work provides a valuable roadmap for future research, guiding the design of online RNN learning rules that are both computationally efficient and more aligned with biological learning constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment