Attention based Convolutional Recurrent Neural Network for Environmental Sound Classification
Environmental sound classification (ESC) is a challenging problem due to the complexity of sounds. The ESC performance is heavily dependent on the effectiveness of representative features extracted from the environmental sounds. However, ESC often su…
Authors: Zhichao Zhang, Shugong Xu, Tianhao Qiao
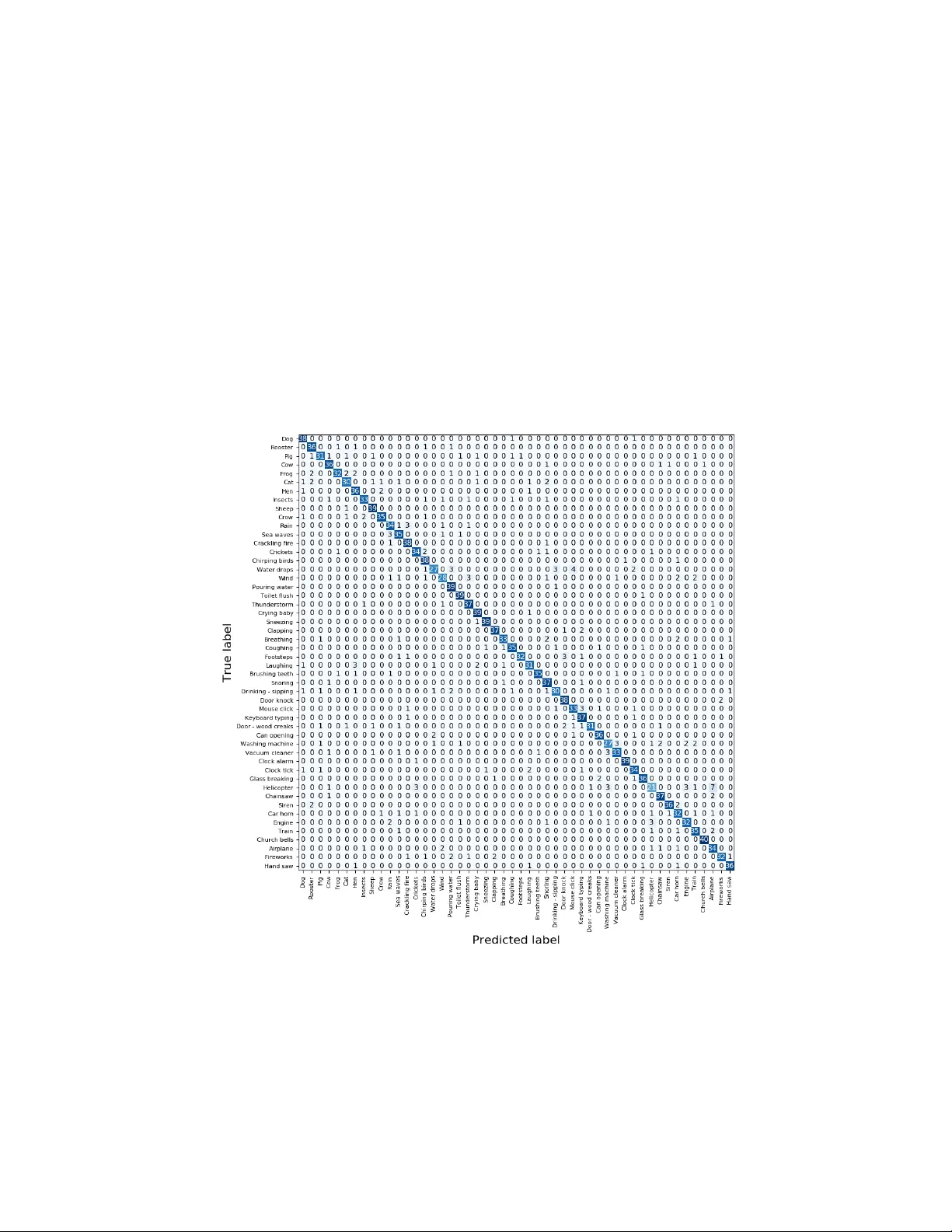
A tten tion based Con v olutional Recurren t Neural Net w ork for En vironmen tal Sound Classification Zhic hao Zhang, Sh ugong Xu ? , Tianhao Qiao, Shunqing Zhang, and Shan Cao Shanghai Institute for Adv anced Comm unication and Data Science, Shanghai Univ ersity , Shanghai, 200444, China { zhichaozhang, shugong, qiaotianhao, shunqing, cshan } @shu.edu.cn Abstract. En vironmental sound classification (ESC) is a c hallenging problem due to the complexity of sounds. The ESC p erformance is heav- ily dependent on the effectiveness of representativ e features extracted from the environmen tal sounds. How ever, ESC often suffers from the se- man tically irrelev ant frames and silen t frames. In order to deal with this, w e employ a frame-lev el atten tion model to focus on the seman tically rel- ev ant frames and salien t frames. Sp ecifically , w e first prop ose an conv o- lutional recurrent neural netw ork to learn sp ectro-temporal features and temp oral correlations. Then, we extend our conv olutional RNN mo del with a frame-lev el atten tion mechanism to learn discriminative feature represen tations for ESC. Exp erimen ts were conducted on ESC-50 and ESC-10 datasets. Exp erimen tal results demonstrated the effectiveness of the prop osed method and achiev ed the state-of-the-art performance in terms of classification accuracy . Keyw ords: Environmen tal Sound Classification · Conv olutional Recur- ren t Neural Netw ork · Atten tion Mec hanism 1 In tro duction En vironmental sound classification (ESC) is an important branch of sound recog- nition and is widely applied in surv eillance [17], home automation [22], scene analysis [4] and machine hearing [13]. Th us far, a v ariet y of signal pro cessing and mac hine learning techniques ha ve b een applied for ESC, including dictionary learning [7], matrix factorization [5], gaussian mixture mo del (GMM) [8] and recently , deep neural netw orks [19, 27]. F or traditional mac hine learning classifiers, selecting prop er features is k ey to effectiv e p erformance. F or instance, audio signals ha v e b een traditionally c harac- terized b y Mel-frequency cepstral co efficien ts (MFCCs) as features and classified using a GMM classifier. In recent years, deep neural netw orks (DNNs) hav e shown outstanding p erfor- mance in feature extraction for ESC. Compared to hand-crafted feature, DNNs ? Corresp onding author. Shanghai Institute for Adv anced Communication and Data Science, Shanghai Universit y , Shanghai, China(email: shugong@shu.edu.cn ). ha ve the ability to extract discriminativ e feature represen tations from large quan- tities of training data and generalize well on unseen data. McLoughlin et al. [14] prop osed a deep belief net work to extract high-lev el feature represen tations from magnitude sp ectrum which yielded b etter results than the traditional metho ds. Piczak [15] first ev aluated the p oten tial of con volutional neural netw ork (CNN) in classifying short audio clips of environmen tal sounds and sho wed excellent p erformance on several public datasets. T ak ahashi et al. [20] created a three- c hannel feature as the input to a CNN b y com bining log mel sp ectrogram and its delta and delta-delta information in a manner similar to the R GB input of im- age. In order to mo del the sequential dynamics of environmen tal sound signals, V u et al. [24] applied a recurrent neural netw ork (RNN) to learn temp oral rela- tionships. Moreov er, there is a growing trend to combine CNN and RNN mo dels in to a single arc hitecture. Bae et al. [2] prop osed to train the RNN and CNN in parallel in order to learn sequen tial correlation and lo cal sp ectro-temporal information. In addition, atten tion mechanism-based models hav e sho wn outstanding p er- formance in learning relev an t feature representations for sequence data [6]. Re- cen tly , atten tion mec hanism-based RNNs ha ve b een successfully applied to a wide v ariet y of tasks, including sp eec h recognition [6], machine translation [3] and do cumen t classification [25]. In principle, attention mechanism-based RNNs are well suited to ESC tasks. First, environmen tal sound is essen tially the se- quence data whic h con tains correlation information b et ween adjacen t frames. Second, not all frame-level features contribute equally to the representations of en vironmental sounds. Usually , in public ESC datasets, signals contains man y p eriods of silence, with only a few intermitten t frames asso ciated with the sound class. Thus, it is important to select seman tically relev ant frames for sp ecific class. Similar to attention mec hanism-based RNN, we can also compute the frame-lev el atten tion map from CNN features, fo cusing on the seman tically rel- ev ant frames. In the field of ESC, several works [9, 11, 12, 18] hav e studied the effectiv eness of atten tion mec hanisms and ha v e obtained promising results in sev- eral datasets. Differen t from previous w orks, w e explored b oth the p erformance of frame-level attention mec hanism for CNN la yers and RNN la yers. In this pap er, we prop ose an attention mechanism-based conv olutional RNN arc hitecture (A CRNN) in order to fo cus on seman tically relev ant frames and pro duce discriminative features for ESC. The main contributions of this pap er are summarized as follows. – T o deal with silent frames and semantically irrelev ant frames, W e employ an atten tion mo del to automatically fo cus on the semantically relev ant frames and pro duce discriminative features for ESC. W e explore b oth the p erfor- mance of frame-lev el atten tion mec hanism for CNN la yers and RNN lay ers. – T o analyze temporal relations, W e propose a nov el con v olutional RNN mo del whic h first uses CNN to extract high level feature representations and then inputs the features to bidirectional GRUs. W e combine the con volutional RNN and atten tion mo del in a unified architecture. – T o indicate the effectiveness of the prop osed metho d and achiev e current state-of-the-art p erformance, we conduct exp eriments on ESC-10 and ESC- 50 datasets. C o n v 1 C o n v 2 M a x P o o l i n g … … C o n v 7 C o n v 8 M a x P o o l i n g G R U , B i - D i r e c t i o n a l G R U , B i - D i r e c t i o n a l F u l l y C o n n e c t e d L a y e r f r e q u e n c y t i m e L o g G a m m a t o n e S p e c t r o g r a m C o n v o l u t i o n a l R e c u r r e n t N e t w o r k P r e d i c t i o n P r o b a b i l i t y D i s t r i b u t i o n s s t a t i c d e l t a d o g s i r e n r a i n 0 . 7 0 . 2 0 . 1 Fig. 1: Architecture of conv olutional recurren t neural netw ork for environmen tal sound classification 2 Metho ds In this section, we in tro duce the proposed method for ESC. First, w e generate Log Gammatone sp etrogram (Log-GTs) features from en vironmental sounds as the input of A CRNN, as shown in Fig. 1. Then, we introduce the arc hitecture of A CRNN, which combines conv olutional RNN and a frame-level attention mech- anism. F or the architecture of con volutional RNN and atten tion mechanism, w e will giv e a detailed description, resp ectiv ely . Finally , the data augmentation metho ds w e used are in tro duced. 2.1 F eature Extraction and Prepro cessing Giv en a signal, W e first use short-time F ourier T ransform (STFT) with hamming windo w size of 23 ms (1024 samples at 44.1kHz) and 50% ov erlap to extract the energy sp ectrogram. Then, we apply a 1 28-band Gammatone filter bank [23] to the energy spectrogram and the resulting sp ectrogram is conv erted in to loga- rithmic scale. In order to mak e efficient use of limited data, the spectrogram is split into 128 frames (appro ximately 1.5s in length) with 50% ov erlap. The delta information of the original sp ectrogram is calculated, whic h is the first temp oral deriv ative of the static sp ectrogram. Afterw ards, we concatenate the log gam- matone sp ectrogram and its delta information to a 3-D feature representation X ∈ R 128 × 128 × 2 (Log-GTs) as the input of the net work. 2.2 Arc hitecture of Con v olutional RNN In this section, we prop ose an conv olutional RNN to analyze Log-GTs for ESC. W e first use CNN to learn high lev el feature represen tations on the Log-GTs. Then, the CNN-learned features are fed into bidirectional gated recurrent unit (GR U) lay ers which are used to learn the temp oral correlation information. Fi- nally , these features are fed in to a fully conn ected la yer with a softmax activ ation function to output the probabilit y distribution of different classes. In this pap er, the conv olutional RNN is comprised of eight conv olutional lay ers ( l 1 - l 8 ) and tw o bidirectional GRU la y ers ( l 9 - l 10 ). The architecture and parameters of netw ork are as follo ws: – l 1 - l 2 : The first t wo stac k ed conv olutional la y ers use 32 filters with a receptiv e field of (3,5) and stride of (1,1). This is follow ed by a max-p o oling with a (4,3) stride to reduce the dimensions of feature maps. ReLU activ ation function is used. – l 3 - l 4 : The next tw o conv olutional lay ers use 64 filters with a receptive field of (3,1) and stride of (1,1), and is used to learn lo cal patterns along the frequency dimension. This is follow ed b y a max-po oling with a (4,1) stride. ReLU activ ation function is used. – l 5 - l 6 : The following pair of con volutional lay ers uses 128 filters with a recep- tiv e field of (1,5) and stride of (1,1), and is used to learn lo cal patterns along the time dimension. This is follow ed b y a max-p ooling with a (1,3) stride. ReLU activ ation function is used. – l 7 - l 8 : The subsequen t t wo con volutional la yers use 256 filters with a receptiv e field of (3,3) and stride of (1,1) to learn joint time-frequency characteristics. This is follow ed by a max-po oling of a (2,2) stride. ReLU activ ation function is used. – l 9 - l 10 : Tw o bidirectional GRU la yers with 256 cells are used for temp oral summarization, and tanh activ ation function is used. Drop out with proba- bilit y of 0 . 5 is used for each GRU la yer to av oid ov erfitting. Batc h normalization [10] is applied to the output of the conv olutional la yers to sp eed up training. L2-regularization is applied to the weigh ts of eac h la yer with a co efficien t 0 . 0001. 2.3 F rame-level Atten tion Mechanism Not all frame-level features con tribute equally to representations of environmen- tal sounds. As shown in Fig. 2, except for the semantically relev ant frames( f 1), the features usually contain silent or noisy frames( f 2), whic h reduce the robust- ness of mo del and increase misclassification. Hence, w e apply frame-level atten- tion mechanisms to fo cus on the parts that are most vital to the meaning of the sound and to pro duce discriminativ e representations for ESC. In this pap er, we emplo y atten tion mec hanism for CNN la yers and RNN lay ers, resp ectiv ely . Fig. 2: Visualization of Log-GTs of differen t classes with semantically relev ant frame( f 1) and silent or noisy frame( f 2). F rom left to right, the class is do g b ark , b aby cry and clo ck tick . A ttention for CNN lay ers: As sho wn in Fig.3(a), given CNN features M ∈ R F × T × C , w e first use a 3x3 conv olution filter to learn a hidden representation. This is follow ed by a a verage-po ol with ( F, 1) size in order to reduce the fre- quency dimension to one. Then, w e use softmax function to form a normalized atten tion map A ∈ R 1 × T × 1 , which holds the frame-lev el attention w eights for CNN features. With atten tion map A , the attention weigh ted CNN features are obtained as M 0 = M · A (1) The atten tion is applied b y m ultiplying the attention vector A to eac h feature v ector of M along frequency dimension and channel dimension. A ttention for RNN lay ers: As shown in Fig.3(b), w e first feed the GRU output h t = [ − → h t , ← − h t ] through a one-lay er MLP to obtain a hidden represen tation of h t , then we calculate the normalized imp ortance weigh t β t b y a softmax function (2). After that, w e compute the feature vector v through a weigh ted sum of the frame-lev el con v olutional RNN feautues based on the weigh ts (3). The feature v ector v is forw arded in to the fully connected lay er for final classification. β t = exp ( W ∗ h t ) P T t =1 exp ( W ∗ h t ) (2) v = T X t =1 β t h t (3) 2.4 Data Augmen tation Limited data easily leads mo del tow ards ov erfitting. In this pap er, we use time stretc h with a factor randomly selected from [0.8, 1.3] and pitc h shift with a Fig. 3: F rame-level atten tion for (a) CNN la yers and (b) RNN lay ers. F or CNN la yers, we use frame-level attention to obtain attention map, which is multiplied in frame-wise of CNN features, resulting the atten tion weigh ted features. F or RNN la yers, we utilize frame-lev el attention to obtain attention weigh ts, which is multiplied in frame-wise of input features. Then, we aggregate these atten tion w eighted representations to form a feature vector, which can b e seen as a high- lev el represen tation of a sound like ”dog bark”. factor randomly selected from [-3.5, 3.5] to increase raw training data size. In addition, an efficient mixup [26] augmentation metho d is used to construct vir- tual training data and extend the training distribution. In mixup, a feature and a target (ˆ x, ˆ y) are generated by mixing tw o feature-target examples, which are determined by ( ˆ x = λx i + (1 − λ ) x j ˆ y = λy i + (1 − λ ) y j (4) where x i and x j are tw o features randomly selected from the training Log- GTs, and y i and y j are their one-hot lab els. The mix factor λ is decided b y a h yp er-parameter α and λ ∼ Beta( α , α ). 3 Exp erimen ts and Results 3.1 Exp erimen t Setup T o ev aluate the p erformance of our prop osed methods, we carry out experi- men ts on tw o publicly av ailable datasets: ESC-50 and ESC-10 [16]. ESC-50 is a collection of 2000 en vironmental recordings containing 50 classes in 5 ma jor cat- egories, including animals, natur al soundsc ap es and water sounds, human non- sp e e ch sounds, interior/domestic sounds , and exterior/urb an noises . All audio samples are 5 seconds in duration with a 44.1 kHz sampling frequency . ESC-10 is a subset of 10 classes (400 samples) selected from the ESC-50 dataset ( do g b ark, r ain, se a waves, b aby cry, clo ck tick, p erson sne eze, helic opter, chainsaw, r o oster, fir e cr ackling ). In this paper, w e use a sampling rate of 44.1 kHz for all samples in order to use ric h high-frequency information. F or training, all mo dels optimize cross-entrop y loss using mini-batch stochastic gradien t descen t with Nesterov momen tum of 0.9. Eac h batc h consists of 64 segments randomly selected from the training set without rep etition. All mo dels are trained for 300 ep o c hs by beginning with an initial learning rate of 0.01, and then divided the learning rate by 10 ev ery 100 epo chs. W e initialize the netw ork weigh ts to zero mean Gaussian noise with a standard deviation of 0.05. In the test phase, w e ev aluate the whole sample prediction with the highest a verage prediction probabilit y of eac h segment. Both the training and testing features are normalized b y the global mean and s tardard deviation of the training set. All mo dels are trained using Keras library with T ensorFlow back end on a Nvidia P100 GPU with 12GB memory . 3.2 Exp erimen t Results T able 1: Comparison of A CRNN and existing metho ds. W e p erform 5-fold cross v alidation (CV) by using the official fold s ettings. The av erage results of CV are recorded. Mo del ESC-10 ESC-50 PiczakCNN [15] 80.5% 64.9% SoundNet [1] 92.1% 74.2% W a veMsNet [28] 93.7% 79.1% En vNet-v2 [21] 91.4% 84.9% Multi-Stream CNN [12] 93.7% 83.5% A CRNN 93.7% 86.1% W e compare our mo del with existing netw orks reported as PiczakCNN [15], SoundNet [1], W av eMsNet [28], En vNet-v2 [21] and Multi-Stream CNN [12]. According to [15], PiczakCNN consists of t wo conv olutional la yers and three fully connected la yers. The input features of CNN are generated by combining log mel spectrogram and its delta information. W e refer PiczakCNN as a baseline metho d. The results are summarized in T able 1. W e see that ACRNN outp erforms PiczakCNN and obtains an absolute improv emen t of 13.2% and 21.2% on ESC- 10 and ESC-50 datasets, resp ectiv ely . Then, we compare our mo del with sev eral state-of-the-art methods: SoundNet8 [1], W av eMsNet [28], EnvNet-v2 [21] and Multi-Stream CNN [12]. W e observ e that on b oth ESC-10 and ESC-50 datasets, A CRNN obtains the highest classification accuracy . Note that W av eMsNet [28] and Multi-Stream CNN [12] achiev e same classification accuracy as ACRNN on ESC-10 but using feature fusion (raw data and sp ectrogram features), whereas A CRNN only utilizes sp ectrogram features. In Fig.4, we provide the confusion matrix generated b y A CRNN for ESC- 50 dataset. W e see that most classes achiev e higher accuracy than 80%(32/40). P articularly , Chur ch b el ls obtains a 100% recognition rate. Ho wev er, w e ob- serv e that only 52.5%(21/40) Helic opter samples are correctly recognized, with 17.5%(7/40) samples misclassified as A irplane . W e attribute this mistakes to the similar characteristics b et ween the tw o environmen tal sounds. Fig. 4: Confusion matrix of A CRNN with an av erage classification accuracy 86.1% on ESC-50 dataset. 3.3 Effects of attention mechanism T able 2: Classification accuracy of proposed con volutional RNN with and with- out the attention mec hanism. ’augmen t’ denotes a combination of time stretch, pitc h shift and mixup. Mo del Settings ESC-10 ESC-50 con volutional RNN 89.2% 79.9% con volutional RNN-attention 91.7% 81.3% con volutional RNN-augment 93.0% 84.6% con volutional RNN-attention-augmen t 93.7% 86.1% T o inv estigate the effects of the atten tion mechanism, w e compare the results of prop osed conv olutional RNN with and without the atten tion mechanism. In T able 2, the results sho w that the atten tion mec hanism delivers a significan tly impro ved accuracy ev en when we use a data augmentation scheme. In addition, data augmen tation b oasts an impro vemen t of 2.0% and 4.8% on ESC-10 and ESC-50 datasets, resp ectiv ely . 3.4 Where to apply attention T able 3: Classification accuracy of applying the attention mechanism to the output of differen t la yers of the prop osed conv olutional RNN. Mo del Settings ESC-10 ESC-50 no attention 93.0% 84.6% atten tion at l 2 93.5% 85.2% atten tion at l 4 92.7% 83.8% atten tion at l 6 92.7% 84.4% atten tion at l 8 92.5% 84.9% atten tion at l 10 93.7% 86.1% In this section, w e in vestigate the classification p erformance when applying frame-lev el atten tion mec hanism to the different lay ers of CNN and RNN. As sho wn in T able 3, w e obtained the highest classification accuracy and b oosted an absolutely impro v ement of 0.7% and 1.5% when applying the atten tion mec h- anism at l 10 on b oth ESC-10 and ESC-50 datasets, resp ectively . On the ESC-50 dataset, the classification accuracy obtained a slight impro vemen t when the at- ten tion mechanism w as applied at l 2 and l 8 , while for other CNN la yers, the classification accuracy decreased. On the ESC-10 dataset, we obtained an im- pro vemen t of 0.5% when only applying attention at l 2 for CNN lay ers. F urther- more, we found that on both ESC-10 and ESC-50 datasets, the classification accuracy is impro ved than standard con volutional RNN when applying atten- tion at l 2 for CNN la yers. 4 Conclusion In this pap er, we prop osed an atten tion mec hanism-based con volutional recur- ren t neural netw ork (ACRNN) for ESC. W e explored the frame-level atten tion mec hanism and gav e a detailed description for CNN lay ers and RNN lay ers, re- sp ectiv ely . Exp erimen tal results on ESC-10 and ESC-50 datasets demonstrated the effectiveness of the prop osed method and achiev ed state-of-the-art p erfor- mance in terms of classification accuracy . In addition, we compared the classifi- cation accuracy when applying different la yers, including CNN la yers and RNN la yers. The exp erimental results show ed that applying atten tion for RNN lay ers obtained highest accuracy . Ho wev er, we found when applying atten tion for CNN la yers, the p erformance is not alwa ys improv ed. W e plan to explore this in our future work. References 1. Aytar, Y., V ondrick, C., T orralba, A.: Soundnet: Learning sound representations from unlabeled video. In: Proc. Int. Conf. Neural Inf. Process. Syst. pp. 892–900 (2016) 2. Bae, S.H., Choi, I., Kim, N.S.: Acoustic scene classification using parallel combi- nation of lstm and cnn. DCASE2016 Challenge, T ech. Rep. (2016) 3. Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation b y jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014) 4. Barc hiesi, D., Giannoulis, D., Stow ell, D., Plumbley , M.D.: Acoustic scene clas- sification: Classifying environmen ts from the sounds they pro duce. IEEE Signal Pro cess. Magazine 32 (3), 16–34 (2015) 5. Bisot, V., Serizel, R., Essid, S., Richard, G.: F eature learning with matrix factor- ization applied to acoustic scene classification. IEEE/A CM T rans. Audio, Sp eech, Language Pro cess. 25 (6), 1216–1229 (2017) 6. Choro wski, J.K., Bahdanau, D., Serdyuk, D., Cho, K., Bengio, Y.: A ttention-based mo dels for sp eech recognition. In: Pro c. Int. Conf. Neural Inf. Process. Syst. pp. 577–585 (2015) 7. Ch u, S., Naray anan, S., Kuo, C.C.J.: En vironmental sound recognition with time– frequency audio features. IEEE T rans. Audio, Sp eech, Language Pro cess. 17 (6), 1142–1158 (2009) 8. Dhanalakshmi, P ., P alanivel, S., Ramalingam, V.: Classification of audio signals using aann and gmm. Applied Soft Computing 11 (1), 716–723 (2011) 9. Guo, J., Xu, N., Li, L.J., Alwan, A.: A ttention based cldnns for short-duration acoustic scene classification. In: Proc. Interspeech. pp. 469–473 (2017) 10. Ioffe, S., Szegedy , C.: Batch normalization: Accelerating deep net work training by reducing internal cov ariate shift. arXiv preprin t arXiv:1502.03167 (2015) 11. Jun, W., Shengc hen, L.: Self-attention mec hanism based system for dcase2018 chal- lenge task1 and task4. DCASE2018 Challenge, T ech. Rep. (2018) 12. Li, X., Chebiyy am, V., Kirchhoff, K.: Multi-stream netw ork with temp oral atten- tion for en vironmental sound classification. arXiv preprin t arXiv:1901.08608 (2019) 13. Ly on, R.F.: Machine hearing: An emerging field [exploratory dsp]. IEEE Signal Pro cess. Magazine 27 (5), 131–139 (2010) 14. McLoughlin, I., Zhang, H., Xie, Z., Song, Y., Xiao, W.: Robust sound even t classi- fication using deep neural netw orks. IEEE/ACM T rans. Audio, Sp eec h, Language Pro cess. 23 (3), 540–552 (2015) 15. Piczak, K.J.: Environmen tal sound classification with con volutional neural net- w orks. In: Proc. 25th In t. W orkshop Mac h. Learning Signal Pro cess. pp. 1–6 (2015) 16. Piczak, K.J.: Esc: Dataset for en vironmental sound classification. In: Proc. 23rd A CM Int. Conf. Multimedia. pp. 1015–1018 (2015) 17. Radhakrishnan, R., Div ak aran, A., Smaragdis, A.: Audio analysis for surveillance applications. In: Proc. IEEE W orkshop Appl. Signal Pro cess. Audio Acoust. pp. 158–161 (2005) 18. Ren, Z., et. al.: Atten tion-based con volutional neural netw orks for acoustic scene classification. DCASE2018 Challenge, T ech. Rep. (2018) 19. Salamon, J., Bello, J.P .: Deep conv olutional neural netw orks and data augmenta- tion for en vironmental sound classification. IEEE Signal Process. Letters 24 (3), 279–283 (2017) 20. T ak ahashi, N., Gygli, M., Pfister, B., V an Gool, L.: Deep conv olutional neu- ral netw orks and data augmentation for acoustic even t detection. arXiv preprin t arXiv:1604.07160 (2016) 21. T ok ozume, Y., Ushiku, Y., Harada, T.: Learning from b etw een-class examples for deep sound recognition. arXiv preprin t arXiv:1711.10282 (2017) 22. V ac her, M., Serignat, J.F., Chaillol, S.: Sound classification in a smart ro om en- vironmen t: an approac h using gmm and hmm methods. In: Pro c. 4th IEEE Conf. Sp eec h T echnique, Human-Computer Dialogue. vol. 1, pp. 135–146 (2007) 23. V alero, X., Alias, F.: Gammatone cepstral coefficients: Biologically inspired fea- tures for non-speech audio classification. IEEE T rans. Multimedia 14 (6), 1684– 1689 (2012) 24. V u, T.H., W ang, J.C.: Acoustic scene and even t recognition using recurrent neural net works. DCASE2016 Challenge, T ec h. Rep. (2016) 25. Y ang, Z., Y ang, D., Dyer, C., He, X., Smola, A., Ho vy , E.: Hierarchical attention net works for do cumen t classification. In: Pro c. NAA CL-HL T. pp. 1480–1489 (2016) 26. Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: Mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 (2017) 27. Zhang, Z., Xu, S., Cao, S., Zhang, S.: Deep con volutional neural netw ork with mixup for environmen tal sound classification. In: Pro c. Chinese Conf. P attern Recognit. Comput. Vision. pp. 356–367 (2018) 28. Zh u, B., W ang, C., Liu, F., Lei, J., Lu, Z., Peng, Y.: Learning environmen tal sounds with multi-scale conv olutional neural net work. arXiv preprin t (2018)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment