Hierarchical Deep Multiagent Reinforcement Learning with Temporal Abstraction
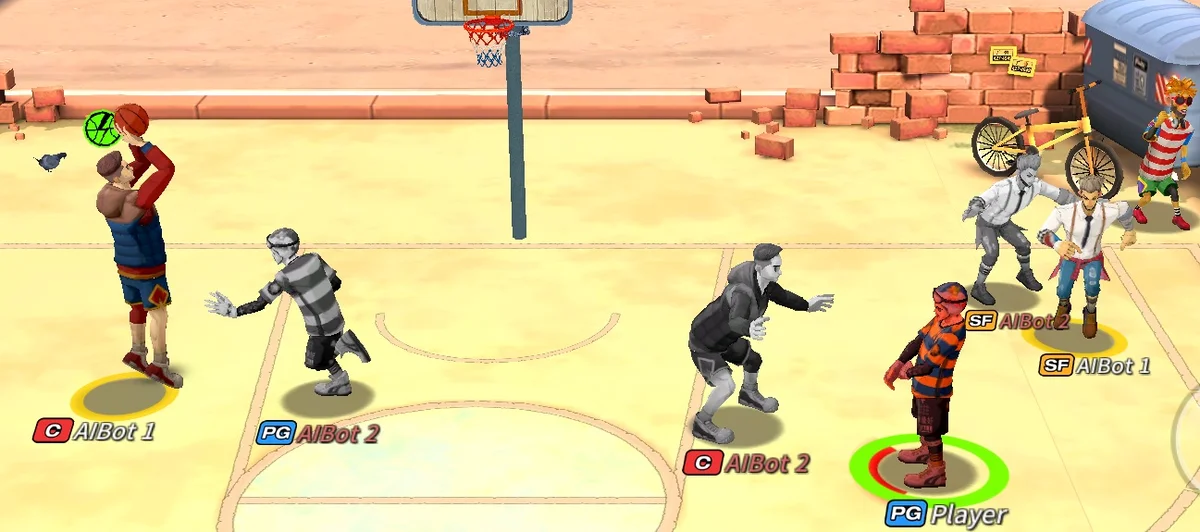
Multiagent reinforcement learning (MARL) is commonly considered to suffer from non-stationary environments and exponentially increasing policy space. It would be even more challenging when rewards are sparse and delayed over long trajectories. In this paper, we study hierarchical deep MARL in cooperative multiagent problems with sparse and delayed reward. With temporal abstraction, we decompose the problem into a hierarchy of different time scales and investigate how agents can learn high-level coordination based on the independent skills learned at the low level. Three hierarchical deep MARL architectures are proposed to learn hierarchical policies under different MARL paradigms. Besides, we propose a new experience replay mechanism to alleviate the issue of the sparse transitions at the high level of abstraction and the non-stationarity of multiagent learning. We empirically demonstrate the effectiveness of our approaches in two domains with extremely sparse feedback: (1) a variety of Multiagent Trash Collection tasks, and (2) a challenging online mobile game, i.e., Fever Basketball Defense.
💡 Research Summary
This paper tackles the challenging setting of cooperative multi‑agent reinforcement learning (MARL) where rewards are both sparse and delayed. The authors introduce temporal abstraction to decompose the problem into two hierarchical levels: a high‑level “goal‑selection” layer that operates on a semi‑Markov decision process and a low‑level “skill‑execution” layer that behaves as a standard MDP conditioned on the current goal. The high‑level policy chooses intrinsic goals that may span multiple time steps; the low‑level policy executes primitive actions to achieve each goal, receiving an intrinsic reward (e.g., +1 on goal completion).
Three hierarchical deep MARL architectures are built on this framework, each corresponding to a different MARL paradigm:
-
Hierarchical Independent Learner (h‑IL) – each agent learns its high‑ and low‑level policies completely independently using DQN‑based Semi‑MDP Q‑learning. This baseline is simple, works with both synchronous and asynchronous termination models, but does not exploit any global information for coordination.
-
Hierarchical Communication Network (h‑Comm) – inspired by CommNet, agents exchange hidden states at the high‑level. Each agent’s hidden representation is averaged with those of its peers, producing a communication vector that is fed into the next network layer. This enables sparse, learned communication that can improve coordination while still allowing asynchronous goal selection.
-
Hierarchical Qmix Network (h‑Qmix) – extends the popular Qmix architecture to the hierarchical setting. Individual high‑level Q‑values are mixed through a monotonic mixing network whose weights are generated by hyper‑networks conditioned on the global state. The resulting joint Q‑value can be optimized centrally during training, yet during execution each agent acts only on its own Q‑value, preserving decentralised execution. This design naturally fits synchronous termination; asynchronous cases require a trimming step to align transitions.
A major bottleneck in hierarchical MARL is the scarcity of high‑level transitions, which leads to inefficient experience replay and exacerbates non‑stationarity because replayed experiences may be outdated. To address this, the authors propose Augmented Concurrent Experience Replay (ACER), consisting of:
-
Experience Augmentation – each high‑level transition (state, goal, cumulative reward, next state) is broken down into a set of sub‑transitions that include intermediate states. This densifies the replay buffer, allowing the high‑level policy to be updated more frequently.
-
Concurrent Sampling – experiences from multiple agents are sampled together in a single minibatch, reducing the bias introduced by non‑stationary policies and encouraging coordinated updates.
The paper validates the approach on two domains with extremely sparse feedback.
-
Multi‑agent Trash Collection – agents must pick up trash and deliver it to designated locations; reward is given only upon successful delivery. Experiments show that h‑Comm and h‑Qmix converge faster and achieve higher success rates than h‑IL, and that ACER further accelerates learning.
-
Fever Basketball Defense – a real‑time online mobile game where several defensive agents must cooperate to block opponent shots. Rewards are only provided at the end of a match, making the problem highly delayed. Conventional MARL methods (independent Q‑learning, VDN, QMIX) fail to learn effective policies, whereas the hierarchical architectures combined with ACER learn stable defensive strategies and substantially improve win rates.
Key contributions are: (1) the first hierarchical deep MARL framework that leverages temporal abstraction to handle sparse and delayed rewards; (2) three concrete architectures (h‑IL, h‑Comm, h‑Qmix) that cover independent learning, communication‑based coordination, and centralized‑training‑decentralized‑execution paradigms; (3) the ACER replay mechanism that mitigates both transition sparsity and non‑stationarity; and (4) empirical evidence that the proposed methods outperform state‑of‑the‑art MARL on both synthetic and real‑world‑scale tasks. The work opens avenues for applying hierarchical MARL to complex real‑world systems such as multi‑robot teams, large‑scale game AI, and smart‑city coordination where rewards are naturally sparse and delayed.
Comments & Academic Discussion
Loading comments...
Leave a Comment