Koalja: from Data Plumbing to Smart Workspaces in the Extended Cloud
Koalja describes a generalized data wiring or pipeline' platform, built on top of Kubernetes, for plugin user code. Koalja makes the Kubernetes underlay transparent to users (for a serverless’ experience), and offers a breadboarding experience for development of data sharing circuitry, to commoditize its gradual promotion to a production system, with a minimum of infrastructure knowledge. Enterprise grade metadata are captured as data payloads flow through the circuitry, allowing full tracing of provenance and forensic reconstruction of transactional processes, down to the versions of software that led to each outcome. Koalja attends to optimizations for avoiding unwanted processing and transportation of data, that are rapidly becoming sustainability imperatives. Thus one can minimize energy expenditure and waste, and design with scaling in mind, especially with regard to edge computing, to accommodate an Internet of Things, Network Function Virtualization, and more.
💡 Research Summary
The paper presents Koalja, a generalized data pipeline platform built atop Kubernetes, designed to democratize data processing by abstracting away infrastructure complexity. It positions itself not as another specialized tool, but as a foundational “data circuitry” framework that aims to commoditize data plumbing, enabling a seamless transition from development breadboarding to production systems.
Koalja’s core philosophy is a shift from developer-centric to user-centric cloud abstractions. It completely hides the underlying Kubernetes infrastructure, offering a serverless experience where users only need to supply their business logic in containerized plugins. The platform manages all aspects of resource orchestration, scaling, and interconnection.
A key technical contribution is its unified model for data flow control. It moves beyond the traditional dichotomy of batch vs. streaming or push vs. pull models. Instead, Koalja employs policy-driven adaptation based on factors like data arrival rates, required processing latency, and sampling needs. This “data-aware” platform intelligently schedules work and manages resources, scaling them down to zero when idle.
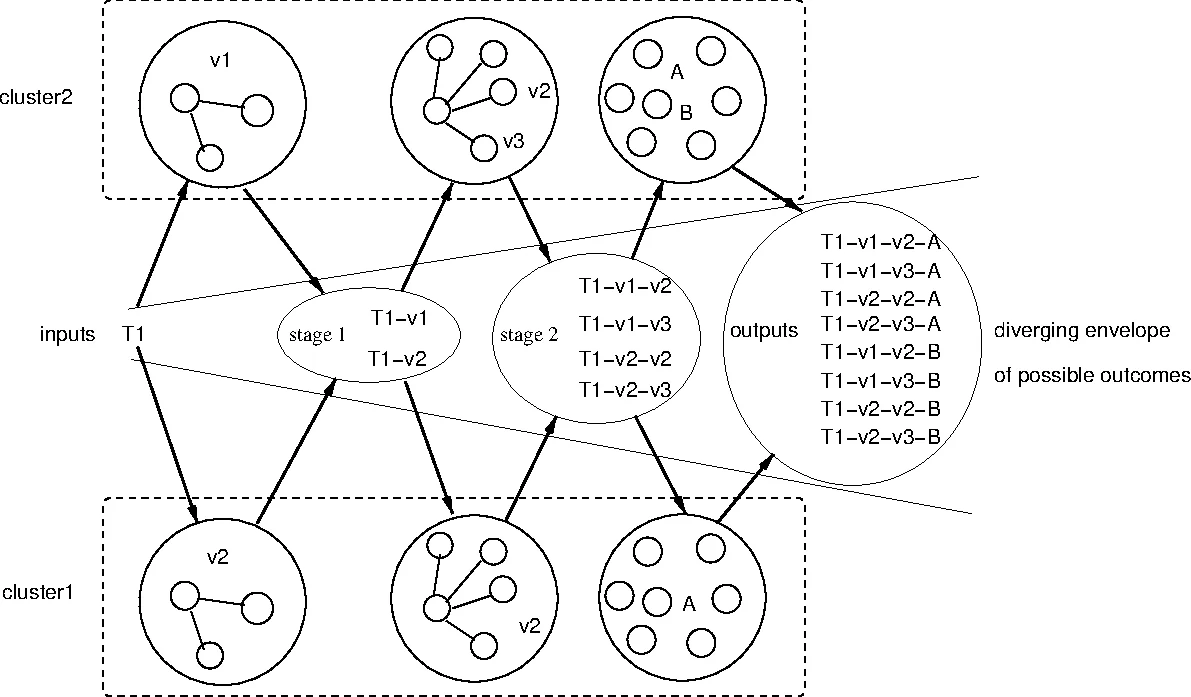
Forensic traceability is a first-class design principle. Koalja automatically captures rich, enterprise-grade metadata as data payloads traverse the pipeline. This enables three distinct forensic views: 1) The “data traveler’s log,” tracing the complete journey of an individual data artifact, including all software versions that processed it. 2) The “checkpoint visitor log,” recording all events and data passing through a specific processing task. 3) The “long-term design map,” documenting the intended topology and business semantics of the entire system. This allows for precise provenance tracking and reconstruction of any outcome.
Architecturally, Koalja consists of Tasks (user code containers), Links (scalable data channels between tasks), Storage (for intermediate data caching), and a Pipeline Manager for orchestration and metadata assembly. To optimize for sustainability and wide-area scaling (e.g., for Edge/IoT scenarios), it advocates for a publish-subscribe (pull) model for bulk data transfer, decoupled from a low-latency push channel for notifications, minimizing unnecessary data movement and replication.
The paper argues that Koalja provides a skeleton that could potentially encapsulate or replace functionalities of vertically-optimized tools like Jenkins, Kafka, or Airflow within a single, policy-managed platform. Its ultimate vision is to enable “Smart Workspaces” within an “Extended Cloud,” seamlessly integrating centralized data centers with edge devices. By making data wiring simple, observable, and efficient, Koalja aims to reduce the accidental complexity and energy waste prevalent in today’s ad-hoc, tool-spaghetti approaches to data processing.
Comments & Academic Discussion
Loading comments...
Leave a Comment