Leveraging Acoustic Cues and Paralinguistic Embeddings to Detect Expression from Voice
Millions of people reach out to digital assistants such as Siri every day, asking for information, making phone calls, seeking assistance, and much more. The expectation is that such assistants should understand the intent of the users query. Detecting the intent of a query from a short, isolated utterance is a difficult task. Intent cannot always be obtained from speech-recognized transcriptions. A transcription driven approach can interpret what has been said but fails to acknowledge how it has been said, and as a consequence, may ignore the expression present in the voice. Our work investigates whether a system can reliably detect vocal expression in queries using acoustic and paralinguistic embedding. Results show that the proposed method offers a relative equal error rate (EER) decrease of 60% compared to a bag-of-word based system, corroborating that expression is significantly represented by vocal attributes, rather than being purely lexical. Addition of emotion embedding helped to reduce the EER by 30% relative to the acoustic embedding, demonstrating the relevance of emotion in expressive voice.
💡 Research Summary
The paper tackles a fundamental limitation of current voice‑assistant intent detection pipelines: they rely almost exclusively on the textual transcription produced by automatic speech recognition (ASR) and thus ignore how a user says something. The authors hypothesize that vocal expression—captured by acoustic and paralinguistic cues—contains valuable information for distinguishing intents that are lexically identical but spoken with different affective tones (e.g., a calm request for a police station versus an urgent call for help).
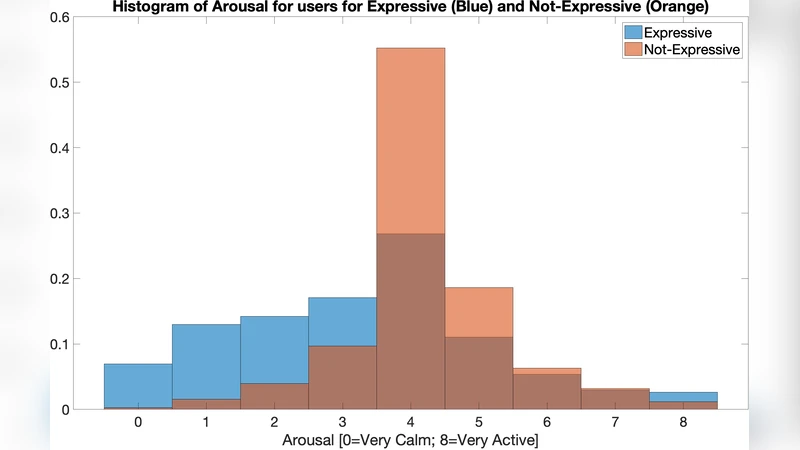
To test this hypothesis, they assembled a proprietary dataset of roughly 100 hours of US‑English speech collected from Siri‑like queries. Each utterance was annotated by four human graders who labeled (1) whether the utterance was expressive (Yes/No/Not Sure) and (2) primitive emotion scores for arousal and valence on a three‑point Likert scale. After discarding utterances with unanimous “Not Sure” responses, about 70 hours of data remained. The final label for each utterance was the average of the four graders, yielding continuous targets for regression. The dataset was split into a 60‑hour pre‑training set, a balanced 30‑hour fine‑tuning set, a 4‑hour development set, and a 3‑hour evaluation set.
Feature engineering explored three families of acoustic descriptors: (a) standard 20‑dimensional MFCCs, (b) 20‑dimensional gamma‑tone cepstral coefficients (GCCs), and (c) 20‑dimensional modulation cepstral coefficients (NMCC). To capture prosodic information, a three‑dimensional pitch/voicing vector (F0‑V) was concatenated to each cepstral set, producing 23‑dimensional composites (e.g., MFCC+F0‑V). In addition, the authors extracted eight vocal‑tract constriction variables (TVs) that describe glottal, velic, lip, and tongue configurations. Because TVs are not directly observable, they trained an LSTM‑based speech‑to‑TV model on 400 hours of synthetic articulatory data, then used this model to infer TV trajectories from the real query recordings.
Modeling proceeded in three stages. First, a single‑layer LSTM (128 hidden units) was trained to predict the expressive label directly from each acoustic feature set, using cross‑entropy loss. To mitigate class imbalance, the authors pre‑trained on the full 60‑hour set and fine‑tuned on the balanced 30‑hour subset, employing a learning‑rate schedule (0.0001 → 0.01) and early‑stopping based on validation loss. Second, separate LSTMs (64 hidden units) were trained to regress arousal and valence from the same acoustic inputs, using mean‑squared error loss; the resulting hidden‑state vectors constitute “emotion embeddings.” Third, the acoustic embedding (AE) from the expression LSTM and the emotion embedding (EE) from the emotion LSTM were concatenated and fed to a shallow feed‑forward network (128 neurons) that outputs the final expression score.
Baseline comparisons included a bag‑of‑words (BoW) neural network trained on ASR transcripts and a random predictor. The BoW model achieved an equal‑error‑rate (EER) of 47.46 % and weighted accuracy (WA) of 52.79 %, essentially chance performance, confirming that lexical information alone cannot capture expressive nuances. The MFCC‑LSTM acoustic model dramatically outperformed the text baseline (EER = 29.05 %, WA = 65.34 %). Adding pitch/voicing (F0‑V) to any cepstral set consistently reduced EER (e.g., MFCC+F0‑V: 28.23 % EER, WA = 73.51 %) and raised F‑score, indicating that prosodic contours are crucial for expression detection.
Emotion modeling yielded concordance correlation coefficients (CCC) of 0.40 for valence and 0.66 for arousal when using the richest feature set (MFCC+F0‑V+TV). These figures demonstrate that the TV‑augmented acoustic representation improves valence estimation, a task traditionally more challenging than arousal detection.
The most striking results emerged from embedding fusion. Using only the acoustic embedding from the NMCC+F0‑V model gave an EER of 27.26 %. When the emotion embedding derived from MFCC+F0‑V+TV was concatenated (AE + EE), EER dropped to 20.01 % (≈26 % relative improvement). Combining two acoustic embeddings (MFCC+F0‑V and NMCC+F0‑V) with the emotion embedding (AE2 + EE) achieved the lowest EER of 18.84 %, a 59 % relative reduction compared with the text‑only system and a 34 % reduction versus the MFCC baseline. ROC curves corroborated these gains, with the fused model exhibiting the highest true‑positive rate across operating points.
Key insights distilled from the study are: (1) low‑level acoustic and prosodic cues encode expressive intent far better than lexical cues; (2) primitive emotion scores (arousal, valence) are strongly correlated with perceived expression and can be leveraged as auxiliary supervision; (3) articulatory information, captured via TV trajectories, enhances valence prediction and thus indirectly benefits expression detection; (4) multi‑modal embedding fusion—combining acoustic and emotion representations—yields the most robust performance.
In conclusion, the authors demonstrate that vocal expression can be reliably detected from short, isolated queries using a combination of robust acoustic features, emotion embeddings, and articulatory cues. The reported 60 % relative EER reduction over a bag‑of‑words baseline suggests that integrating such paralinguistic signals into real‑world voice assistants could substantially improve intent classification, especially for ambiguous or emotionally charged requests. Future work is suggested to explore multilingual datasets, real‑time lightweight architectures, and end‑to‑end integration of expression detection into downstream SLU pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment