Learning from Past Mistakes: Improving Automatic Speech Recognition Output via Noisy-Clean Phrase Context Modeling
Automatic speech recognition (ASR) systems often make unrecoverable errors due to subsystem pruning (acoustic, language and pronunciation models); for example pruning words due to acoustics using short-term context, prior to rescoring with long-term …
Authors: Prashanth Gurunath Shivakumar, Haoqi Li, Kevin Knight
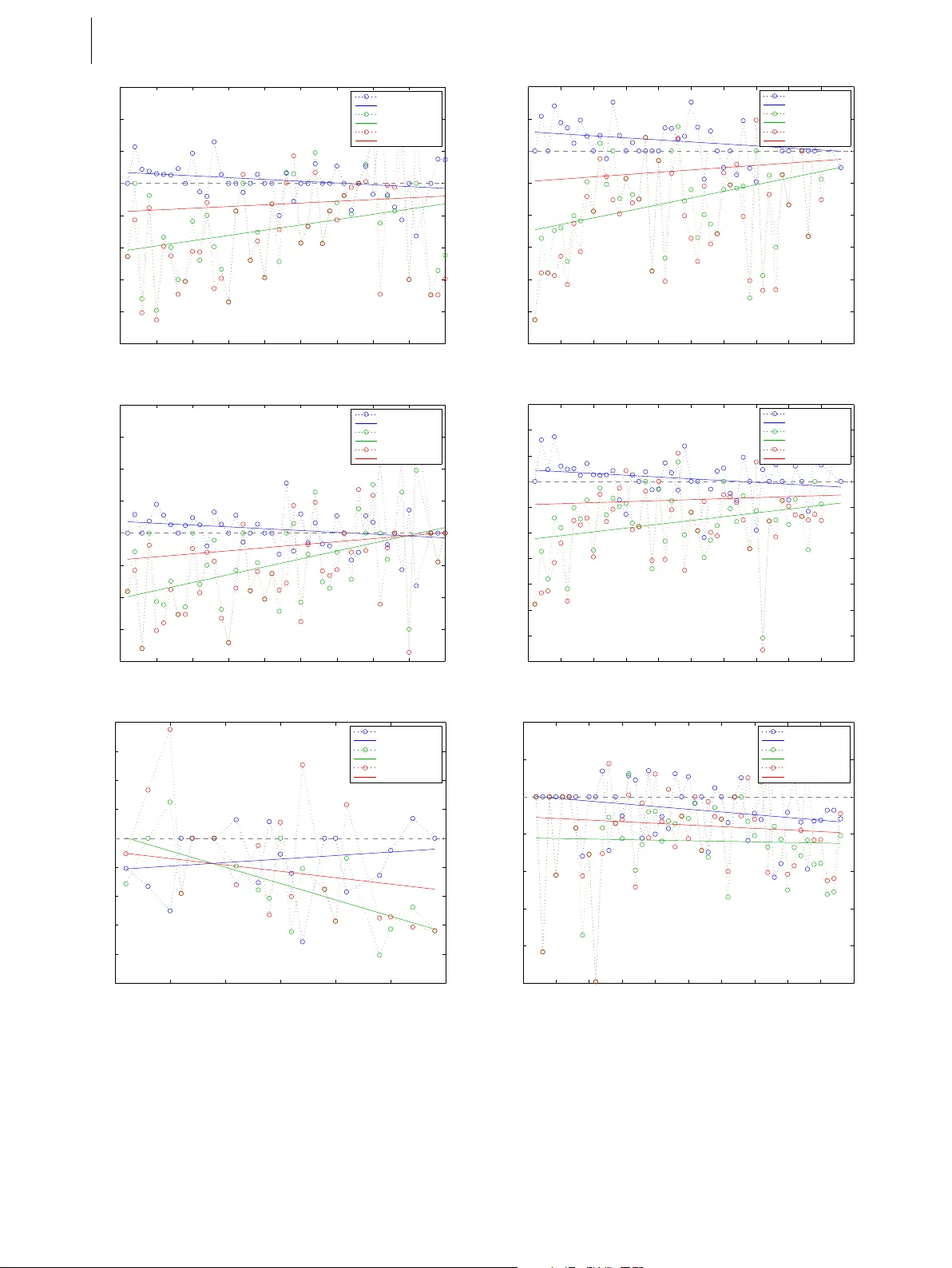
L E A R N I N G F RO M PA S T M I S T A K E S 1 Lear ning fr om P ast Mistakes: Impr oving A utomatic Speech Recognition Output via Noisy-Clean Phrase Context Modeling P R A S H A N T H G U RU N A T H S H I V A K U M A R 1 , H AO Q I L I 1 , K E V I N K N I G H T 2 A N D P A N A Y I OT I S G E O R G I O U 1 Automatic speech r ecognition (ASR) systems often make unr ecoverable err ors due to subsystem pruning (acoustic, lan- guage and pronunciation models); for e xample pruning words due to acoustics using short-term context, prior to r escoring with long-term context based on linguistics. In this work we model ASR as a phr ase-based noisy transformation c hannel and pr opose an err or corr ection system that can learn fr om the aggr egate err ors of all the independent modules consti- tuting the ASR and attempt to in vert those. The pr oposed system can exploit long-term context using a neural network language model and can better choose between existing ASR output possibilities as well as r e-introduce pr eviously pruned or unseen (out-of-vocabulary) phrases. It pr ovides corrections under poorly performing ASR conditions without de grading any accurate transcriptions; such corrections ar e greater on top of out-of-domain and mismatched data ASR. Our system consistently pr ovides impr ovements over the baseline ASR, even when baseline is further optimized thr ough r ecurrent neu- ral network langua ge model r escoring. This demonstrates that any ASR impr ovements can be exploited independently and that our pr oposed system can potentially still pr ovide benefits on highly optimized ASR. F inally, we present an e xtensive analysis of the type of err ors corr ected by our system. Keyw ords: Error correction, Speech recognition, Phrase-based context modeling, Noise channel estimation, Neural Network Language Model I. INTR ODUCTION Due to the complexity of human language and quality of speech signals, improving performance of automatic speech recognition (ASR) is still a challenging task. The traditional ASR comprises of three conceptually distinct modules: acoustic modeling, dictionary and language mod- eling. Three modules are fairly independent of each other in research and operation. In terms of acoustic modeling, Gaussian Mixture Model (GMM) based Hidden Markov Model (HMM) systems [1, 2] were a standard for ASR for a long time and are still used in some of the current ASR systems. Lately , advances in Deep Neural Netw ork (DNN) led to the adv ent of Deep Belief Networks (DBN) and Hybrid DNN-HMM [3, 4], which basically replaced the GMM with a DNN and employed a HMM for alignments. Deep Recurrent Neural Networks (RNN), particularly Long Short T erm Memory (LSTM) Networks replaced the traditional DNN and DBN systems [5]. Connectionist T emporal Classifica- tion (CTC) [6] pro ved to be ef fective with the ability to 1 Signal Processing for Communication Understanding and Behavior Analysis Lab- oratory (SCUBA), Uni versity of Southern California, Los Angeles, USA 2 Information Sciences Institute, University of Southern California, Los Angeles, USA Corresponding author: P anayiotis Georgiou Email: georgiou@sipi.usc.edu compute the alignments implicitly under the DNN architec- ture, thereby eliminating the need of GMM-HMM systems for computing alignments. The research efforts for dev eloping efficient dictionar- ies or lexicons hav e been mainly in terms of pronunci- ation modeling. Pronunciation modeling was introduced to handle the intra-speaker variations [7, 8], non-native accent v ariations [7, 8], speaking rate variations found in conv ersational speech [8] and increased pronunciation variations found in children’ s speech [9]. V arious linguis- tic knowledge and data-deriv ed phonological rules were incorporated to augment the lexicon. Research efforts in language modeling share those of the Natural Language Processing (NLP) community . By estimating the distribution of words, statistical language modeling (SLM), such as n-gram, decision tree models [10], linguistically motiv ated models [11] amount to cal- culating the probability distribution of different linguistic units, such as words, phrases [12], sentences, and whole documents [13]. Recently , Deep Neural Network based lan- guage models [14 – 16] hav e also sho wn success in terms of both perplexity and word error rate. V ery recently , state-of-the-art ASR systems are employ- ing end-to-end neural network models, such as sequence- to-sequence [17] in an encoder-decoder architecture. The systems are trained end-to-end from acoustic features as input to predict the phonemes or characters [18, 19]. Such systems can be viewed as an integration of acous- tic and lexicon pronunciation models. The state-of-the-art 1 2 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . performance can be attributed towards the joint training (optimization) between the acoustic model and the lexi- con models (end-to-end) enabling them to overcome the short-comings of the former independently trained models. Sev eral research efforts were carried out for error correc- tion using post-processing techniques. Much of the effort in volves user input used as a feedback mechanism to learn the error patterns [20, 21]. Other work employs multi- modal signals to correct the ASR errors [21, 22]. W ord co-occurrence information based error correction systems hav e proven quite successful [23]. In [24], a word-based error correction technique was proposed. The technique demonstrated the ability to model the ASR as a noisy chan- nel. In [25], similar technique was applied to a syllable- to-syllable channel model along with maximum entropy based language modeling. In [26], a phrase-based machine translation system was used to adapt a generic ASR to a domain specific grammar and vocab ulary . The system trained on words and phonemes, was used to re-rank the n-best hypotheses of the ASR. In [27], a phrase based machine translation system was used to adapt the mod- els to the domain-specific data obtained by manual user- corrected transcriptions. In [28], an RNN was trained on various text-based features to e xploit long-term context for error correction. Confusion networks from the ASR have also been used for error correction. In [29], a bi-directional LSTM based language model was used to re-score the confusion network. In [30], a two step process for error correction was proposed in which words in the confu- sion network are re-ranked. Errors present in the confusion network are detected by conditional random fields (CRF) trained on n-gram features and subsequently long-distance context scores are used to model the long contextual infor- mation and re-rank the words in the confusion network. [31, 32] also makes use of confusion networks along with semantic similarity information for training CRFs for error correction. Our Contribution: The scope of this paper is to ev alu- ate whether subsequent transcription corrections can take place, on top of a highly optimized ASR. W e hypothesize that our system can correct the errors by (i) re-scoring lat- tices, (ii) reco vering pruned lattices, (iii) recovering unseen phrases, (iv) providing better recovery during poor recog- nitions, (v) providing improv ements under all acoustic conditions, (vi) handling mismatched train-test conditions, (vii) exploiting longer contextual information and (viii) text regularization. W e target to satisfy the above hypothe- ses by proposing a Noisy-Clean Phrase Context Model (NCPCM). W e introduce context of past errors of an ASR system, that consider all the automated system noisy trans- formations. These errors may come from any of the ASR modules or ev en from the noise characteristics of the sig- nal. Using these errors we learn a noisy channel model, and apply it for error correction of the ASR output. Compared to the above efforts, our work differs in the following aspects: • Error corrections take place on the output of a state-of- the-art Lar ge V ocabulary Continuous Speech Recogni- tion (L VCSR) system trained on matched data. This dif- fers from adapting to constrained domains (e.g. [26, 27]) that exploit domain mismatch. This provides additional challenges both due to the larger error-correcting space (spanning larger vocab ulary) and the already highly optimized ASR output. • W e e valuate on a standard L VCSR task thus establishing the ef fectiveness, reproducibility and generalizability of the proposed correction system. This differs from past work where speech recognition was on a large- vocab ulary task but subsequent error corrections were ev aluated on a much smaller vocab ulary . • W e analyze and ev aluate multiple type of error correc- tions (including but not restricted to Out-Of-V ocabulary (OO V) words). Most prior work is directed towards recov ery of OO V words. • In addition to ev aluating a large-vocab ulary correction system on in-domain (Fisher , 42k words) we ev aluate on an out-of-domain, larger vocab ulary task (TED-LIUM, 150k w ords), thus assessing the ef fecti veness of our sys- tem on challenging scenarios. In this case the adaptation is to an even bigger v ocabulary , a much more challeng- ing task to past work that only considered adaptation from large to small v ocabulary tasks. • W e employ multiple hypotheses of ASR to train our noisy channel model. • W e employ state-of-the-art neural network based lan- guage models under the noisy-channel modeling frame- work which enable exploitation of longer conte xt. Additionally , our proposed system comes with several advantages: (1) the system could potentially be trained without an ASR by creating a phonetic model of corruption and emulating an ASR decoder on generic text corpora, (2) the system can rapidly adapt to new linguistic patterns, e.g., can adapt to unseen words during training via contextual transformations of erroneous L VCSR outputs. Further , our work is different from discriminati ve train- ing of acoustic [33] models and discriminative language models (DLM) [34], which are trained directly to optimize the word error rate using the reference transcripts. DLMs in particular inv olve optimizing, tuning, the weights of the language model with respect to the reference transcripts and are often utilized in re-ranking n-best ASR hypothe- ses [34 – 38]. The main distinction and adv antage with our method is the NCPCM can potentially re-introduce unseen or pruned-out phrases. Our method can also operate when there is no access to lattices or n-best lists. The NCPCM can also operate on the output of a DLM system. The rest of the paper is organized as follows: Section II presents v arious hypotheses and discusses the different types of errors we expect to model. Section III elabo- rates on the proposed technique and Section IV describes the experimental setup and the databases employed in this work. Results and discussion are presented in Section V L E A R N I N G F RO M PA S T M I S T A K E S 3 and we finally conclude and present future research direc- tions in Section VI. II. HYPO THESES In this section we analytically present cases that we hypoth- esize the proposed system could help with. In all of these the errors of the ASR may stem from realistic constraints of the decoding system and pruning structure, while the pro- posed system could exploit very long context to improve the ASR output. Note that the vocab ulary of an ASR doesn’t always match the one of the error correction system. Lets consider for example, an ASR that does not have le xicon entries for “Prashanth” or “Shi vakumar” but it has the entries “Shiv a” and “Kumar”. Lets also assume that this ASR consistently makes the error “Pression” when it hears “Prashanth”. Giv en training data for the NCPCM, it will learn the transformation “Pression Shiv a Kumar” into “Prashanth Shiv akumar”, thus it will hav e a larger v ocabulary than the ASR and learn to recover such errors. This demonstrates the ability to learn out-of-vocab ulary entries and to rapidly adapt to new domains. A) Re-scoring Lattices 1. “I was born in nineteen ninety thr ee in Iraq” 2. “I was born in nineteen ninety thr ee in eye r ack” 3. “I was born in nineteen ninety thr ee in I rack” Phonetic T ranscription: “ ay . w aa z . b ao r n . ih n . n ay n t iy n . n ay n t iy . th r iy . ih n . ay . r ae k ” Example 1 In Example 1, all the three samples hav e the same pho- netic transcription. Let us assume sample 1 is the correct transcription. Since all the three examples hav e the same phonetic transcription, this makes them indistinguishable by the acoustic model. The language model is likely to down-score the sample 3. It is possible that sample 2 will score higher than sample 1 by a short context LM (e.g. bi-gram or 3-gram) i.e., “in” might be followed by “eye” more frequently than “Iraq” in the training corpora. This will likely result in an ASR error . Thus, although the ora- cle WER can be zero, the output WER is likely going to be higher due to LM choices. Hypothesis A: An ideal error correction system can select correct options from the existing lattice. B) Recovering Pruned Lattices A more sev ere case of Example 1 would be that the word “Iraq” was pruned out of the output lattice during decod- ing. This is often the case when there are memory and complexity constraints in decoding large acoustic and lan- guage models, where the decoding beam is a restricting parameter . In such cases, the word nev er ends up in the out- put lattice. Since the ASR is constrained to pick over the only existing possible paths through the decoding lattice, an error is inevitable in the final output. Hypothesis B: An ideal error correction system can generate words or phrases that were erroneously pruned during the decoding process. C) Recovery of Unseen Phrases On the other hand, an extreme case of Example 1 would be that the word “Iraq” was never seen in the training data (or is out-of-vocab ulary), thereby not appearing in the ASR lattice. This would mean the ASR is forced to select among the other hypotheses ev en with a lo w confidence (or output an unknown, < unk > , symbol) resulting in a similar error as before. This is often the case due to the constant ev o- lution of human language or in the case of a ne w domain. For example, names such as “ Al Qaeda” or “ISIS” were non-existent in our v ocabularies a fe w years ago. Hypothesis C: An ideal error correction system can generate words or phrases that are out of vocab- ulary (OO V) and thus not in the ASR output. D) Better Recovery during P oor Recognitions An ideal error correction system would provide more improv ements for poor recognitions from an ASR. Such a system could potentially offset for the ASR’ s low per- formance providing consistent performance over v ary- ing audio and recognition conditions. In real-life condi- tions, the ASR often has to deal with varying level of “mismatched train-test” conditions, where relativ ely poor recognition results are commonplace. Hypothesis D: An ideal error correction system can provide more corrections when the ASR performs poorly , thereby offsetting ASR’ s performance drop (e.g. during mismatched train-test conditions). E) Improv ements under all Acoustic Conditions An error correction system which performs well during tough recognition conditions, as per Hypothesis D is no good if it degrades good recognizer output. Thus, in addi- tion to our Hypothesis D, an ideal system would cause no degradation on good ASR output. Such a system can be hypothesized to consistently improve upon and pro- vide benefits ov er any ASR system including state-of-the- art recognition systems. An ideal system would provide 4 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . improv ements ov er the entire spectrum of ASR perfor - mance (WER). Hypothesis E: An ideal error correction system can not only provide improvements during poor recog- nitions, but also preserves good speech recognition. F) Adaptation W e hypothesize that the proposed system would help in adaptation ov er mismatched conditions. The mismatch could manifest in terms of acoustic conditions and lexical constructs. The adaptation can be seen as a consequence of Hypothesis D & E. In addition, the proposed model is capable of capturing patterns of language use manifest- ing in specific speaker(s) and domain(s). Such a system could eliminate the need of retraining the ASR model for mismatched en vironments. Hypothesis F: An ideal error correction system can aid in mismatched train-test conditions. G) Exploit Longer Context • “ Eyes melted, when he placed his hand on her shoulder s.” • “ Ice melted, when he placed it on the table .” Example 2 The complex construct of human language and under- standing enables recovery of lost or corrupted information ov er different temporal resolutions. For instance, in the abov e Example 2, both the phrases, “Eyes melted, when he placed” and “Ice melted, when he placed” are valid when viewed within its shorter context and hav e identical pho- netic transcriptions. The succeeding phrases, underlined, help in discerning whether the first word is “Eyes” or “Ice”. W e hypothesize that an error correction model capable of utilizing such longer contexts is beneficial. As new models for phrase based mapping, such as sequence to sequence models [17], become applicable this becomes even more possible and desirable. Hypothesis G: An ideal error correction system can exploit longer context than the ASR for better corrections. H) Regularization 1. • “I guess ’cause I went on a I went on a ... ” • “I guess because I went on a I went on a ... ” 2. • “i was born in nineteen ninety two” • “i was born in 1992” 3. • “i was born on nineteen twelve” • “i was born on 19/12” Example 3 As per the 3 cases shown in Example 3, although both the hypotheses for each of them are correct, there are some irregularities present in the language syntax. Normalization of such surface form representation can increase readabil- ity and usability of output. Unlike traditional ASR, where there is a need to explicitly program such regularizations, our system is expected to learn, gi ven appropriate training data, and incorporate regularization into the model. Hypothesis H: An ideal error correction system can be deployed as an automated text re gularizer . III. METHODOLOGY The overvie w of the proposed model is shown in Figure 1. In our paper , the ASR is viewed as a noisy channel (with transfer function H ), and we learn a model of this channel, b H − 1 (estimate of in verse transfer function H − 1 ) by using the corrupted ASR outputs (equiv alent to signal corrupted by H ) and their reference transcripts. Later on, we use this model to correct the errors of the ASR. The noisy channel modeling mainly can be divided into word-based and phrase-based channel modeling. W e will first introduce pre vious related work, and then our proposed NCPCM. A) Pre vious related work 1) W ord-based Noisy Channel Modeling In [24], the authors adopt w ord-based noisy channel model borrowing ideas from a word-based statistical machine translation dev eloped by IBM [39]. It is used as a post- processor module to correct the mistakes made by the ASR. The word-based noisy channel modeling can be presented as: ˆ W = argmax W clean P ( W clean | W noisy ) = argmax W clean P ( W noisy | W clean ) P LM ( W clean ) where ˆ W is the corrected output word sequence, P ( W clean | W noisy ) is the posterior probability , P ( W noisy | W clean ) is the channel model and P LM ( W clean ) is the language model. In [24], authors hypothesized that introducing L E A R N I N G F RO M PA S T M I S T A K E S 5 many-to-one and one-to-man y word-based channel model- ing (referred to as fertility model) could be more effecti ve, but w as not implemented in their work. 2) Phrase-based Noisy Channel Modeling Phrase-based systems were introduced in application to phrase-based statistical translation system [40] and were shown to be superior to the word-based systems. Phrase based transformations are similar to word-based models with the exception that the fundamental unit of observa- tion and transformation is a phrase (one or more words). It can be viewed as a super-set of the word-based [39] and the fertility [24] modeling systems. B) Noisy-Clean Phrase Context Modeling W e e xtend the ideas by proposing a complete phrase-based channel modeling for error correction which incorporates the many-to-one and one-to-many as well as many-to-many words (phrase) channel modeling for error -correction. This also allows the model to better capture errors of varying resolutions made by the ASR. As an extension, it uses a distortion modeling to capture any re-ordering of phrases during error-correction. Even though we do not expect big benefits from the distortion model (i.e., the order of the ASR output is usually in agreement with the audio rep- resentation), we include it in our study for examination. It also uses a word penalty to control the length of the output. The phrase-based noisy channel modeling can be represented as: ˆ p = argmax p clean P ( p clean | p noisy ) (1) = argmax p clean P ( p noisy | p clean ) P LM ( p clean ) w length ( p clean ) where ˆ p is the corrected sentence, p clean and p noisy are the reference and noisy sentence respectively . w length ( p clean ) is the output word sequence length penalty , used to control the output sentence length, and P ( p noisy | p clean ) is decom- posed into: P ( p I noisy | p I clean ) = I Y i =1 φ ( p i noisy | p i clean ) D ( start i − end i − 1 ) (2) where φ ( p i noisy | p i clean ) is the phrase channel model or phrase translation table, p I noisy and p I clean are the sequences of I phrases in noisy and reference sentences respectiv ely and i refers to the i th phrase in the sequence. D ( star t i − end i − 1 ) is the distortion model. star t i is the start posi- tion of the noisy phrase that was corrected to the i th clean phrase, and end i − 1 is the end position of the noisy phrase corrected to be the i − 1 th clean phrase. C) Our Other Enhancements In order to effecti vely demonstrate our idea, we employ (i) neural language models, to introduce long term context and justify that the longer contextual information is bene- ficial for error corrections; (ii) minimum error rate training (MER T) to tune and optimize the model parameters using dev elopment data. 1) Neural Language Models Neural network based language models hav e been shown to be able to model higher order n-grams more efficiently [14 – 16]. In [25], a more efficient language modeling using maximum entropy was shown to help in noisy-channel modeling of a syllable-based ASR error correction system. Incorporating such language models would aid the error- correction by exploiting the longer context information. Hence, we adopt two types of neural network language models in this work. (i) Feed-forward neural network which is trained using a sequence of one-hot word repre- sentation along with the specified context [41]. (ii) Neural Dictionary Model Acoustic Model Language Model Lattice ASR Language Model (ARPA/Neural) Noisy-Clean Phrase Context Model Noisy-Clean Phrase Transition Model Corrected ASR Output Reference Signal H Corrupted Signal H -1 T raining Viterbi 1-best path k-best path Audio Input Audio Input ^ H -1 Corrected Signal Eval ^ Fig. 1.: Overvie w of NCPCM 6 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . network joint model (NNJM) language model [42]. This is trained in a similar way as in (i), but the context is aug- mented with noisy ASR observations with a specified con- text windo w . Both the models employed are feed-forward neural networks since they can be incorporated directly into the noisy channel modeling. The recurrent neural network LM could potentially be used during phrase-based decod- ing by employing certain caching and approximation tricks [43]. Noise Contrastiv e Estimation was used to handle the large v ocabulary size output. 2) Minimum Error Rate T raining (MER T) One of the downsides of the noisy channel modeling is that the model is trained to maximize the likelihood of the seen data and there is no direct optimization to the end criteria of WER. MER T optimizes the model parameters (in our case weights for language, phrase, length and distortion models) with respect to the desired end ev aluation crite- rion. MER T was first introduced in application to statistical machine translation providing significantly better results [44]. W e apply MER T to tune the model on a small set of dev elopment data. IV . EXPERIMENT AL SETUP A) Database For training, de velopment, and e valuation, we employ Fisher English T raining Part 1, Speech (LDC2004S13) and Fisher English T raining Part 2, Speech (LDC2005S13) corpora [45]. The Fisher English Training Part 1, is a col- lection of con versation telephone speech with 5850 speech samples of up to 10 minutes, approximately 900 hours of speech data. The Fisher English Training Part 2, contains an addition of 5849 speech samples, approximately 900 hours of telephone conv ersational speech. The corpora is split into training, de velopment and test sets for experimen- tal purposes as sho wn in T able 1. The splits of the data-sets are consistent over both the ASR and the subsequent noisy- clean phrase context model. The dev elopment dataset was used for tuning the phrase-based system using MER T . W e also test the system under mismatched training- usage conditions on TED-LIUM. TED-LIUM is a dedi- cated ASR corpus consisting of 207 hours of TED talks [46]. The data-set was chosen as it is significantly different to Fisher Corpus. Mismatch conditions include: (i) varia- tions in channel characteristics, Fisher, being a telephone con versations corpus, is sampled at 8kHz where-as the TED-LIUM is originally 16kHz, (ii) noise conditions, the Fisher recordings are significantly noisier , (iii) utterance lengths, TED-LIUM has longer con versations since they are extracted from TED talks, (iv) lexicon sizes, vocab u- lary size of TED-LIUM is much larger with 150,000 w ords where-as Fisher has 42,150 unique words, (v) speaking intonation, Fisher being telephone conv ersations is spon- taneous speech, whereas the TED talks are more org anized and well articulated. Factors (i) and (ii) mostly affect the performance of ASR due to acoustic differences while (iii) and (iv) affect the language aspects, (v) affects both the acoustic and linguistic aspects of the ASR. B) System Setup 1) A utomatic Speech Recognition System W e used the Kaldi Speech Recognition T oolkit [47] to train the ASR system. In this paper , the acoustic model was trained as a DNN-HMM hybrid system. A tri-gram max- imum likelihood estimation (MLE) language model was trained on the transcripts of the training dataset. The CMU pronunciation dictionary [48] was adopted as the lexicon. The resulting ASR is state-of-the-art both in architecture and performance and as such additional gains on top of this ASR are challenging. 2) Pre-pr ocessing The reference outputs of ASR corpus contain non-verbal signs, such as [laughter], [noise] etc. These event signs might corrupt the phrase context model since there is lit- tle contextual information between them. Thus, in this paper , we cleaned our data by removing all these non- verbal signs from dataset. The text data is subjected to traditional tokenization to handle special symbols. Also, to prev ent data sparsity issues, we restricted all of the sam- ple sequences to a maximum length of 100 tokens (giv en that the database consisted of only 3 sentences having more than the limit). The NCPCM has two distinct vocabular - ies, one associated with the ASR transcripts and the other one pertaining to the ground-truth transcripts. The ASR dictionary is often smaller than the ground-truth transcript mainly because of not having a pronunciation-phonetic transcriptions for certain words, which usually is the case for names, proper-nouns, out-of-language words, broken words etc. 3) NCPCM W e use the Moses toolkit [49] for phrase based noisy chan- nel modeling and MER T optimization. The first step in the training process of NCPCM is the estimation of the word alignments. IBM models are used to obtain the word align- ments in both the directions (reference-ASR and ASR- reference). The final alignments are obtained using heuris- tics (starting with the intersection of the two alignments and then adding the additional alignment points from the Database T rain Dev elopment T est Hours Utterances W ords Hours Utterances W ords Hours Utterances W ords Fisher English 1,890.5 1,833,088 20,724,957 4.7 4906 50,245 4.7 4914 51,230 TED-LIUM - - - 1.6 507 17,792 2.6 1155 27,512 T able 1. Database split and statistics L E A R N I N G F RO M PA S T M I S T A K E S 7 union of two alignments). For computing the alignments “mgiza”, a multi-threaded version of GIZA++ toolkit [50] was employed. Once the alignments are obtained, the lexi- cal translation table is estimated in the maximum likelihood sense. Then on, all the possible phrases along with their word alignments are generated . A max phrase length of 7 was set for this work. The generated phrases are scored to obtain a phrase translation table with estimates of phrase translation probabilities. Along with the phrase translation probabilities, word penalty scores (to control the transla- tion length) and re-ordering/distortion costs (to account for possible re-ordering) are estimated. Finally , the NCPCM model is obtained as in the equation 2. During decoding equation 1 is utilized. For training the MLE n-gram models, SRILM toolkit [51] was adopted. Further we employ the Neural Proba- bilistic Language Model T oolkit [41] to train the neural language models. The neural network was trained for 10 epochs with an input embedding dimension of 150 and output embedding dimension of 750, with a single hid- den layer . The weighted average of all input embeddings was computed for padding the lower -order estimates as suggested in [41]. The NCPCM is an ensemble of phrase translation model, language model, translation length penalty , re- ordering models. Thus the tuning of the weights associated with each model is crucial in the case of proposed phrase based model. W e adopt the line-search based method of MER T [52]. W e try two optimization criteria with MER T , i.e., using BLEU(B) and WER(W). C) Baseline Systems W e adopt four different baseline systems because of their relev ance to this work: Baseline-1: ASR Output : The ra w performance of the ASR system, because of its relev ance to the application of the proposed model. Baseline-2: Re-scoring lattices using RNN-LM : In order to ev aluate the performance of the system with more recent re-scoring techniques, we train a recurrent-neural network with an embedding dimension of 400 and sigmoid activ a- tion units. Noise contrastive estimation is used for training the network and is optimized on the dev elopment data set which is used as a stop criterion. Faster-RNNLM 1 toolkit is used to train the recurrent-neural network. For re-scoring, 1000-best ASR hypotheses are decoded and the old LM (MLE) scores are remov ed. The RNN-LM scores are com- puted from the trained model and interpolated with the old LM. Finally , the 1000-best hypotheses are re-constructed into lattices, scored with new interpolated LM and decoded to get the new best path hypothesis. Baseline-3: W or d- based noisy channel model : In order to compare to a prior work described in Section 1 which is based on [24]. The word-based noisy channel model is created in a similar way as the NCPCM model with three specific exceptions: (i) the 1 https://github .com/yandex/faster-rnnlm max-phrase length is set to 1, which essentially conv erts the phrase based model into word based, (ii) a bi-gram LM is used instead of a tri-gram or neural language model, as suggested in [24], (iii) no re-ordering/distortion model and word penalties are used. Baseline-4: Discriminative Languag e Modeling (DLM) : Similar to the proposed work, DLM makes use of the refer - ence transcripts to tune language model weights based on specified feature sets in order to re-rank the n-best hypoth- esis. Specifically , we employ the perceptron algorithm [34] for training DLMs. The baseline system is trained using unigrams, bigrams and trigrams (as in [35 – 37]) for a fair comparison with the proposed NCPCM model. W e also provide results with an extended feature set comprising of rank-based features and ASR LM and AM scores. Refr (Reranker framew ork) is used for training the DLMs [53] following most recommendations from [37]. 100-best ASR hypotheses are used for training and re-ranking purposes. D) Evaluation Criteria The final goal of our work is to show improv ements in terms of the transcription accuracy of the ov erall system. Thus, we provide word error rate as it is a standard in the ASR community . Moreover , Bilingual Evaluation Under- study (BLEU) score [54] is used for ev aluating our work, since our model can be also treated as a transfer-function (“translation”) system from ASR output to NCPCM output. V . RESUL TS AND DISCUSSION In this section we demonstrate the ability of our pro- posed NCPCM in validating our hypotheses A-H from Section II along with the experimental results. The exper - imental results are presented in three different tasks: (i) ov erall WER experiments, highlighting the improvements of the proposed system, presented in T ables 3, 4 & 5, (ii) detailed analysis of WERs over subsets of data, presented in Figures 3 & 2, and (iii) analysis of the error corrections, presented in T able 2. The assessment and discussions of each task is structured similar to Section II to support their respectiv e claims. A) Re-scoring Lattices T able 2 sho ws selected samples through the process of the proposed error correction system. In addition to the ref- erence, ASR output and the proposed system output, we provide the ORA CLE transcripts to assess the presence of the correct phrase in the lattice. Cases 4-6 from T able 2 hav e the correct phrase in the lattice, but get down-scored in the ASR final output which is then recovered by our system as hypothesized in Hypothesis A. B) Recovering Pruned Lattices In the cases 1 and 2 from T able 2, we see the correct phrases are not present in the ASR lattice, although they were seen 8 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . 1. REF: oysters clams and mushrooms i think ASR: wasters clams and mushrooms they think ORA CLE: wasters clams and mushrooms i think NCPCM: oysters clams and mushrooms they think Example of hypotheses B 2. REF: yeah we had this awful month this winter where it was lik e a good day if it got up to thirty it was ridiculously cold ASR: yeah we had this awful month uh this winter where it was like a good day if i got up to thirty w as ridiculous lee cold ORA CLE: yeah we had this a wful month this winter where it w as like a good day if it got up to thirty it w as ridiculous the cold NCPCM: yeah we had this awful month uh this winter where it was lik e a good day if i got up to thirty it was ridiculously cold Example of hypotheses A, B, G 3. REF: oh well it depends on whether you agree that al qaeda came right out of afghanistan ASR: oh well it depends on whether you agree that al < unk > to came right out of afghanistan ORA CLE: oh well it depends on whether you agree that al < unk > to came right out of afghanistan NCPCM: oh well it depends on whether you agree that al qaeda to came right out of afghanistan Example of hypotheses C 4. REF: they laugh because ev erybody else is laughing and not because it’ s really funny ASR: they laughed because ev erybody else is laughing and not because it’ s really funny ORA CLE: they laugh because ev erybody else is laughing and not because it’ s really funny NCPCM: they laugh because e verybody else is laughing and not because it’ s really funny Example of hypotheses A, G 5. REF: yeah especially like if you go out for ice cream or something ASR: yeah it specially like if you go out for ice cream or something ORA CLE: yeah it’ s especially lik e if you go out for ice cream or something NCPCM: yeah especially like if you go out for ice cream or something Example of hypotheses A 6. REF: we don’t ha ve a lot of that around we kind of live in a nicer area ASR: we don’t ha ve a lot of that around we kinda live in a nicer area ORA CLE: we don’t ha ve a lot of that around we kind of live in a nicer area NCPCM: we don’ t hav e a lot of that around we kind of li ve in a nicer area Example of hypotheses A, H T able 2. Analysis of selected sentences. REF: Reference ground-truth transcripts; ASR: Output ASR transcriptions; ORA CLE: Best path through output lattice given the ground-truth transcript; NCPCM: T ranscripts after NCPCM error-correction Green color highlights correct phrases. Orange color highlights incorrect phrases. L E A R N I N G F RO M PA S T M I S T A K E S 9 0 5 10 15 20 25 30 35 40 45 0 5 10 15 20 25 30 35 40 45 Utterance Length WER % ASR Top−Good and Bottom−Bad vs. WER Top−Good WER Bottom−Bad WER (a) In Domain (Fisher) 15 20 25 30 35 40 45 5 10 15 20 25 30 35 40 45 50 55 Utterance Length WER % ASR Top−Good and Bottom−Bad vs. WER Top−Good WER Bottom−Bad WER (b) Out of Domain (TEDLIUM) Fig. 2.: T op-Good, Bottom-Bad WER Splits. As we can see the WER for top-good is often 0%, which leaves no margin for improv ement. W e will see the impact of this later, as in Fig. 3 in the training and are present in the vocabulary . Howe ver , the proposed system manages to recov er the phrases as discussed in Hypothesis B. Moreov er, Case 2 also demon- strates an instance where the confusion occurs due to same phonetic transcriptions (“ridiculously” versus “ridiculous lee”) again supporting Hypothesis A. C) Recovery of Unseen Phrases Case 3 of T able 2, demonstrates an instance where the word “qaeda” is absent from the ASR lexicon (vocabulary) and hence absent in the decoding lattice. This forces the ASR to output an unknown-w ord token ( < unk > ). W e see that the system recovers an out-of-vocab ulary word “qaeda” successfully as claimed in Hypothesis C. D) Better Recovery during P oor Recognitions T o justify the claim that our system can offset for the per- formance deficit of the ASR at tougher conditions (as per Hypothesis D), we formulate a sub-problem as follows: Problem Formulation: W e divide equally , per sentence length, our development and test datasets into good recog- nition results (top-good) and poor recognition results (bottom-bad) subsets based on the WER of the ASR and analyze the improv ements and any degradation caused by our system. Figure 3 shows the plots of the above mentioned anal- ysis for dif ferent systems as captioned. The blue lines are representativ e of the impro vements provided by our system for top-good subset over different utterance lengths, i.e., it indicates the difference between our system and the orig- inal WER of the ASR (negati ve values indicate improve- ment and positive values indicate degradation resulting from our system). The green lines indicate the same for bottom-bad subset of the database. The red indicates the difference between the bottom-bad WERs and the top-good WERs, i.e., negati ve values of red indicate that the sys- tem provides more improv ements to the bottom-bad subset relativ e to the top-good subset. The solid lines represent their respecti ve trends which is obtained by a simple linear regression (line-fitting). For poor recognitions, we are concerned about the bottom-bad subset, i.e., the green lines in Figure 3. Firstly , we see that the solid green line is always below zero, which indicates there is always improv ements for bottom- bad i.e., poor recognition results. Second, we observe that the solid red line usually stays below zero, indicating that the performance gains made by the system add more for the bottom-bad poor recognition results compared to the top-good subset (good recognitions). Further , more justifi- cations are provided later in the context of out-of-domain task (Section V F) where high mismatch results in tougher recognition task are discussed. E) Improv ements under all Acoustic Conditions T o justify the claim that our system can consistently pro- vide benefits over any ASR system ( Hypothesis E), we need to sho w that the proposed system: (i) does not degrade the performance of the good recognition, (ii) pro- vides improv ements to poor recognition instances, of the ASR. The latter has been discussed and confirmed in the previous Section V D. For the former , we provide ev alu- ations from two point of views: (1) assessment of WER trends of top-good and bottom-bad subsets (as in the pre- vious Section V D), and (2) ov erall absolute WER of the proposed systems. 10 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . 0 5 10 15 20 25 30 35 40 45 −2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 Utterance Length Absolute WER Change Top−Good Top−Good Trend Bottom−Bad Bottom−Bad Trend Diff Diff Trend (a) Dev: NCPCM + MER T(W) 0 5 10 15 20 25 30 35 40 45 50 −3 −2.5 −2 −1.5 −1 −0.5 0 0.5 1 Utterance Length Absolute WER Change Top−Good Top−Good Trend Bottom−Bad Bottom−Bad Trend Diff Diff Trend (b) T est: NCPCM + MER T(W) 0 5 10 15 20 25 30 35 40 45 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 Utterance Length Absolute WER Change Top−Good Top−Good Trend Bottom−Bad Bottom−Bad Trend Diff Diff Trend (c) Dev: NCPCM + 5gram NNLM + MER T(W) 0 5 10 15 20 25 30 35 40 45 50 −3.5 −3 −2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 Utterance Length Absolute WER Change Top−Good Top−Good Trend Bottom−Bad Bottom−Bad Trend Diff Diff Trend (d) T est: NCPCM + 5gram NNLM + MER T(W) 15 20 25 30 35 40 45 −5 −4 −3 −2 −1 0 1 2 3 4 Utterance Length Absolute WER Change Top−Good Top−Good Trend Bottom−Bad Bottom−Bad Trend Diff Diff Trend (e) Out-of-Domain Dev: NCPCM + generic LM + MER T(W) 0 5 10 15 20 25 30 35 40 45 50 −5 −4 −3 −2 −1 0 1 2 Utterance Length Absolute WER Change Top−Good Top−Good Trend Bottom−Bad Bottom−Bad Trend Diff Diff Trend (f) Out-of-Domain T est: NCPCM + generic LM + MER T(W) Fig. 3.: Length of hypotheses through our NCPCM models versus absolute WER change. Blue & Green lines represent difference between WER of our system and the baseline ASR, for top-good and bottom-bad hypotheses, respecti vely . In an ideal scenario, all these lines would be belo w 0, thus all pro viding a change in WER tow ards improving the system. Howe ver we see in some cases that the WER increases, especially when the hypotheses length is short and when the performance is good. This is as expected since from Fig. 2 some cases are at 0% WER due to the already highly-optimized nature of our ASR. The red line represents the aggregate error o ver all data for each word length and as we can see in all cases the trend is one of impro ving the WER.This matches Hypotheses D, E, F , G L E A R N I N G F RO M PA S T M I S TA K E S 11 In domain testing on Fisher Data Method Dev T est WER BLEU WER BLEU ASR output (Baseline-1) 15.46% 75.71 17.41% 72.99 ASR + RNNLM re-scoring (Baseline-2) 16.17% 74.39 18.39% 71.24 W ord based + bigram LM (Baseline-3) 16.23% 74.28 18.10% 71.76 W ord based + bigram LM + MER T(B) 15.46% 75.70 17.40% 72.99 W ord based + bigram LM + MER T(W) 15.39% 75.65 17.40% 72.77 W ord based + trigram LM + MER T(B) 15.48% 75.59 17.47% 72.81 W ord based + trigram LM + MER T(W) 15.46% 75.46 17.52% 72.46 DLM (Baseline-4) 23.65% 63.35 25.36% 61.19 DLM w/ extended feats 24.48% 62.92 26.12% 60.98 Proposed NCPCM 20.33% 66.70 22.32% 63.81 NCPCM + MER T(B) 15.11% 76.06 17.18% 73.00 NCPCM + MER T(W) 15.10% 76.08 17.15% 73.05 NCPCM + MER T(B) w/o re-ordering 15.27% 76.02 17.11% 73.33 NCPCM + MER T(W) w/o re-ordering 15.19% 75.90 17.18% 73.04 NCPCM + 10best + MER T(B) 15.19% 76.12 17.17% 73.22 NCPCM + 10best + MER T(W) 15.16% 75.91 17.21% 73.03 T able 3. Noisy-Clean Phrase Context Model (NCPCM) results (uses exactly same LM as ASR) Firstly , examining Figure 3, we are mainly con- cerned about the top-good subset pertaining to de gra- dation/improv ement of good recognition instances. W e observe that the solid blue line is close to zero in all the cases, which implies that the degradation of good recogni- tion is extremely minimal. Moreover , we observe that the slope of the line is almost zero in all the cases, which indi- cates that the degradation is minimal and mostly consistent ov er different utterance lengths. Moreover , assessing the degradation from the absolute WER perspectiv e, Figure 2a shows the WER over utterance lengths for the top-good and bottom-bad subsets for the in-domain case. The top- good WER is small, at times ev en 0% (perfect recognition) thereby allo wing very small margin for improvement. In such a case, we see minimal degradation. Although we lose a bit on very good recognitions which is extremely mini- mal, we gain significantly in the case of ‘bad’ recognitions. Thus to summarize, the damage that this system can make, under the best ASR conditions, is minimal and offset by the potential significant gains present when the ASR hits some tough recognition conditions. WER experiments: Secondly , examining the overall WER, T able 3 gives the results of the baseline systems and the proposed tech- nique. Note that we use the same language model as the ASR. This helps us ev aluate a system that does not include additional information. W e provide the perfor - mance measures on both the dev elopment and held out test data. The development data is used for MER T tuning. Baseline results: The output of the ASR (Baseline-1) suggests that the development data is less complex com- pared to the held out test set. In our case, the RNN-LM based lattice re-scoring (Baseline-2) doesn’t help. This results shows that ev en with a higher order context, the RNN-LM is unable to recover the errors present in the lat- tice, suggesting that the errors stem from pruning during decoding. W e note that the word-based system (Baseline- 3) doesn’t provide any impro vements. Even when we increase context (trigram LM) and use MER T optimiza- tion, the performance is just on par with the original ASR output. Further, DLM re-ranking (Baseline-4) fails to provide any improvements in our case. This result is in conjunction with the finding in [37], where the DLM provides improvements only when used in combination with ASR baseline scores. Howe ver , we believe introduc- tion of ASR scores into NCPCM can be beneficial as would be in the case of DLMs. Thus, to demonstrate the independent contribution of NCPCM vs DLM’ s, rather than in vestigate fusion methods, we don’t utilize base- line ASR scores for either of the two methods. W e plan to in vestigate the benefits of multi-method fusion in our future work. When using the extended feature set for training the DLM, we don’t observe improvements. W ith our setup, none of the baseline systems provide notice- able significant improvements over the ASR output. W e believ e this is due to the highly optimized ASR setup, and the nature of the database itself being noisy tele- phone con versational speech. Overall, the results of base- line highlights: (i) the dif ficulty of the problem for our setup, (ii) re-scoring is insufficient and emphasizes the need for recovering pruned out words in the output lattice. NCPCM results: The NCPCM is an ensemble of phrase translation model, language model, word penalty model and re-ordering models. Thus the tuning of the weights associated with each model is crucial in the case of the phrase based models [55]. The NCPCM without tuning, i.e., assigning random weights to the various models, per- forms very poorly as expected. The word-based model lacks re-ordering/distortion modeling and word penalty 12 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . Cross domain testing on TED-LIUM Data Method Dev T est WER BLEU WER ∆ 1 ∆ 2 BLEU Baseline-1 (ASR) 26.92% 62.00 23.04% 0% -10.9% 65.71 ASR + RNNLM re-scoring (Baseline-2) 24.05% 64.74 20.78% 9.8% 0% 67.93 Baseline-3 (W ord-based) 29.86% 57.55 25.51% -10.7% -22.8% 61.79 Baseline-4 (DLM) 33.34% 53.12 28.02% -21.6% -34.8% 58.50 DLM w/ extended feats 30.51% 57.14 29.33% -27.3% -41.1% 57.60 NCPCM + MER T(B) 26.06% 63.30 22.51% 2.3% -8.3% 66.67 NCPCM + MER T(W) 26.15% 63.10 22.74% 1.3% -9.4% 66.36 NCPCM + generic LM + MER T(B) 25.57% 63.98 22.38% 2.9% -7.7% 66.97 NCPCM + generic LM + MER T(W) 25.56% 63.83 22.33% 3.1% -7.5% 66.96 RNNLM re-scoring + NCPCM + MER T(B) 23.36% 65.88 20.40% 11.5% 1.8% 68.39 RNNLM re-scoring + NCPCM + MER T(W) 23.32% 65.76 20.57 10.7% 1% 68.07 RNNLM re-scoring + NCPCM + generic LM + MER T(B) 23.00% 66.48 20.31% 11.8% 2.3% 68.52 RNNLM re-scoring + NCPCM + generic LM + MER T(W) 22.80% 66.19 20.23% 12.2% 2.6% 68.49 T able 4. Results for out-of-domain adaptation using Noisy-Clean Phrase Context Models (NCPCM) ∆ 1 :Relativ e % improvement w .r.t baseline-1; ∆ 2 :Relativ e % improvement w .r.t baseline-2; models and hence are less sensitive to weight tuning. Thus it is unfair to compare the un-tuned phrase based models with the baseline or word-based counterpart. Hence, for all our subsequent experiments, we only include results with MER T . When employing MER T , all of the proposed NCPCM systems significantly outperform the baseline (statistically significant with p < 0 . 001 for both word error and sentence error rates [56] with 51,230 word tokens and 4,914 sentences as part of the test data). W e find that MER T optimized for WER consistently outperforms that with optimization criteria of BLEU score. W e also perform tri- als by disabling the distortion modeling and see that results remain relatively unchanged. This is as expected since the ASR preserves the sequence of words with respect to the audio and there is no reordering effect over the errors. The phrase based context modeling provides a relativ e improv e- ment of 1.72% (See T able 3) over the baseline-3 and the ASR output. Using multiple hypotheses (10-best) from the ASR, we hope to capture more rele v ant error patterns of the ASR model, thereby enriching the noisy channel mod- eling capabilities. Howe ver , we find that the 10-best giv es about the same performance as the 1-best. In this case we considered 10 best as 10 separate training pairs for training the system. In the future we want to exploit the inter-dependenc y of this ambiguity (the fact that all the 10- best hypotheses represent a single utterance) for training and error correction at test time. F) Adaptation WER experiments: T o assess the adaptation capabilities, we ev aluate the performance of the proposed noisy-clean phrase context model on an out-of-domain task, TED-LIUM data-base, shown in T able 4. Baseline Results: The baseline-1 (ASR performance) con- firms of the heightened mismatched conditions between the training Fisher Corpus and the TED-LIUM data-base. Unlike in matched in-domain ev aluation, the RNNLM re-scoring provides drastic improvements (9.8% relative improv ement with WER) when tuned with out-of-domain dev elopment data set. The mismatch in cross domain ev al- uation reflects in considerably worse performance for the word-based and DLM baselines (compared to matched conditions). NCPCM Results: Howe ver , we see that the phrase con- text modeling provides modest improvements over the baseline-1 of approximately 2.3% (See T able 4) relati ve on the held-out test set. W e note that the improvements are consistent compared to the earlier in-domain experiments in T able 3. Moreover , since the previous LM was trained on Fisher Corpus, we adopt a more generic English LM which provides further improvements of up to 3.1% (See T able 4). W e also experiment with NCPCM ov er the re-scored RNNLM output. W e find the NCPCM to always yield con- sistent improvements over the RNNLM output (See ∆ 1 & ∆ 2 in T able 4). An overall gains of 2.6% relativ e is obtained over the RNNLM re-scored output (baseline-2) i.e., 12.2% ov er ASR (baseline-1) is observed. This con- firms that the NCPCM is able to provide improv ements parallel, in conjunction to the RNNLM or any other system that may improve ASR performance and therefore sup- ports the Hypothesis E in yielding improvements in the highly optimized ASR en vironments. This also confirms the robustness of the proposed approach and its appli- cation to the out-of-domain data. More importantly , the result confirms Hypothesis F, i.e., our claim of rapid adapt- ability of the system to varying mismatched acoustic and linguistic conditions. The extreme mismatched conditions in volved in our experiments supports the possibility of going one step further and training our system on artifi- cially generated data of noisy transformations of phrases as in [35, 36, 38, 57 – 59]. Thus possibly eliminating the need for an ASR for training purposes. L E A R N I N G F RO M PA S T M I S TA K E S 13 In domain testing on Fisher Data Method Dev T est WER BLEU WER BLEU Baseline-1 (ASR output) 15.46% 75.71 17.41% 72.99 Baseline-2 (ASR + RNNLM re-scoring) 16.17% 74.39 18.39% 71.24 Baseline-3 (W ord based + 5gram NNLM) 15.47% 75.63 17.41% 72.92 W ord based + 5gram NNLM + MER T(B) 15.46% 75.69 17.40% 72.99 W ord based + 5gram NNLM + MER T(W) 15.42% 75.58 17.38% 72.75 NCPCM + 3gram NNLM + MER T(B) 15.46% 75.91 17.37% 73.24 NCPCM + 3gram NNLM + MER T(W) 15.28% 75.94 17.11% 73.31 NCPCM + 5gram NNLM + MER T(B) 15.35% 75.99 17.20% 73.34 NCPCM + 5gram NNLM + MER T(W) 15.20% 75.96 17.08% 73.25 NCPCM + NNJM-LM (5,4) + MER T(B) 15.29% 75.93 17.13% 73.26 NCPCM + NNJM-LM (5,4) + MER T(W) 15.28% 75.94 17.13% 73.29 T able 5. Results for Noisy-Clean Phrase Context Models (NCPCM) with Neural Network Language Models (NNLM) and Neural Network Joint Models (NNJM) Further , comparing the WER trends from the in-domain task (Figure 3b) to the out-of-domain task (Figure 3f), we firstly find that the improvements in the out-of-domain task are obtained for both top-good (good recognition) and bottom-bad (bad recognition), i.e., both the solid blue line and the solid green line are always below zero. Secondly , we observe that the improv ements are more consistent throughout all the utterance lengths, i.e., all the lines have near zero slopes compared to the in-domain task results. Third, comparing Figure 2a with Figure 2b, we observe more room for improvement, both for top-good portion as well as the bottom-bad WER subset of data set. The three findings are fairly meaningful considering the high mismatch of the out-of-domain data. G) Exploit Longer Context Firstly , inspecting the error correction results from T able 2, cases 2 and 4 hint at the ability of the system to select appropriate word-suf fixes using long term conte xt informa- tion. Second, from detailed WER analysis in Figure 3, we see that the bottom-bad (solid green line) improve- ments decrease with increase in length in most cases, hinting at potential improvements to be found by using higher contextual information for error correction system as future research directions. Moreover , closer inspection across different models, comparing the trigram MLE model (Figure 3b) with the 5gram NNLM (Figure 3d), we find that the NNLM provides minimal degradation and better improv ements especially for longer utterances by exploit- ing more context (the blue solid line for NNLM has smaller intercept v alue as well as higher negati ve slope). W e also find that for the bottom-bad poor recognition results (green solid-line), the NNLM gives consistent (smaller positiv e slope) and better improvements especially for the higher length utterances (smaller intercept value). Thus emphasiz- ing the gains provided by higher conte xt NNLM. WER experiments: Third, T able 5 sho ws the results obtained using a neural network language model of higher orders (also trained only on the in-domain data). For a fair comparison, we adopt a higher order (5gram) NNLM for the baseline-3 word based noise channel modeling system. Even with a higher order NNLM, the baseline-3 fails to improv e upon the ASR. W e don’t include the baseline- 4 results under this section, since DLM doesn’t include a neural network model. Comparing results from T able 3 with T able 5, we note the benefits of higher order LMs, with the 5-gram neural network language model giving the best results (a relative improvement of 1.9% over the baseline- 1), outperforming the earlier MLE n-gram models as per Hypothesis G. Moreov er, experimental comparisons with baseline-3 (word-based) and NCPCM models, both incorporating identical 5-gram neural network language models con- firms the adv antages of NCPCM (a relativ e improv ement of 1.7%). Howe ver , the neural network joint model LM with target context of 5 and source context of 4 did not show significant improvements ov er the traditional neural LMs. W e expect the neural network models to provide further improv ements with more training data. H) Regularization Finally , the last case in T able 2 is of text regularization as described in Section II, Hypothesis H. Overall, in our experiments, we found that approximately 20% were cases of te xt re gularization and the rest were a case of the former hypotheses. VI. CONCLUSIONS & FUTURE WORK In this work, we proposed a noisy channel model for error correction based on phrases. The system post-processes the output of an automated speech recognition system and as such any contributions in improving ASR are in con- junction of NCPCM. W e presented and validated a range of hypotheses. Later on, we supported our claims with apt problem formulation and their respective results. W e showed that our system can improve the performance of the 14 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . ASR by (i) re-scoring the lattices ( Hypothesis A), (ii recov- ering words pruned from the lattices ( Hypothesis B), (iii) recov ering words ne ver seen in the vocab ulary and training data ( Hypothesis C), (iv) e xploiting longer context informa- tion ( Hypothesis G), and (v) by regularization of language syntax ( Hypothesis H). Moreover , we also claimed and jus- tified that our system can provide more improvement in low-performing ASR cases ( Hypothesis D), while keeping the degradation to minimum in cases when the ASR per- forms well ( Hypothesis E). In doing so, our system could effecti vely adapt ( Hypothesis F) to changing recognition en vironments and provide improvements over any ASR systems. In our future work, the output of the noisy-clean phrase context model will be fused with the ASR beliefs to obtain a ne w hypothesis. W e also intend to introduce ASR confidence scores and signal SNR estimates, to improve the channel model. W e are inv estigating introducing the probabilistic ambiguity of the ASR in the form of lattice or confusion networks as inputs to the channel-in version model. Further , we will utilize sequence-to-sequence (Seq2seq) translation modeling [17] to map ASR outputs to refer- ence transcripts. The Seq2seq model has been shown to hav e benefits especially in cases where training sequences are of variable length [60]. W e intend to employ Seq2seq model to encode ASR output to a fixed-size embedding and decode this embedding to generate the corrected tran- scripts. FINANCIAL SUPPOR T The U.S. Army Medical Research Acquisition Activity , 820 Chandler Street, Fort Detrick MD 21702- 5014 is the awarding and administering acquisition office. This work was supported by the Office of the Assistant Secretary of Defense for Health Aff airs through the Psychologi- cal Health and T raumatic Brain Injury Research Program under A ward No. W81XWH-15-1-0632. Opinions, inter- pretations, conclusions and recommendations are those of the author and are not necessarily endorsed by the Department of Defense. R E F E R E N C E S [1] Lawrence R Rabiner, “ A tutorial on hidden Marko v models and selected applications in speech recognition, ” Proceedings of the IEEE , vol. 77, no. 2, pp. 257–286, 1989. [2] Lawrence Rabiner and Biing-Hwang Juang, Fundamentals of Speech Recognition , Prentice-Hall, Inc., Upper Saddle River , NJ, USA, 1993. [3] Geoffrey Hinton, Li Deng, Dong Y u, Geor ge E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly , Andrew Senior, V incent V anhoucke, Patrick Nguyen, T ara N Sainath, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal Processing Magazine , v ol. 29, no. 6, pp. 82–97, 2012. [4] George E Dahl, Dong Y u, Li Deng, and Alex Acero, “Context- dependent pre-trained deep neural networks for large-vocab ulary speech recognition, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 20, no. 1, pp. 30–42, 2012. [5] Alex Grav es, Abdel-rahman Mohamed, and Geoffre y Hinton, “Speech recognition with deep recurrent neural networks, ” in Pr o- ceedings of Acoustics, speech and signal pr ocessing (ICASSP), 2013 IEEE international confer ence on . IEEE, 2013, pp. 6645–6649. [6] Alex Grav es, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber , “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks, ” in Pr o- ceedings of the 23rd international conference on Machine learning . A CM, 2006, pp. 369–376. [7] Helmer Strik and Catia Cucchiarini, “Modeling pronunciation vari- ation for ASR: A survey of the literature, ” Speech Communication , vol. 29, no. 2, pp. 225–246, 1999. [8] Mirjam W ester , “Pronunciation modeling for ASR–knowledge- based and data-deriv ed methods, ” Computer Speech & Language , vol. 17, no. 1, pp. 69–85, 2003. [9] Prashanth Gurunath Shiv akumar, Alexandros Potamianos, Sungbok Lee, and Shrikanth Narayanan, “Improving speech recognition for children using acoustic adaptation and pronunciation modeling., ” in WOCCI , 2014, pp. 15–19. [10] Lalit R Bahl, Peter F Brown, Peter V de Souza, and Robert L Mercer, “ A tree-based statistical language model for natural language speech recognition, ” IEEE Tr ansactions on Acoustics, Speech, and Signal Pr ocessing , vol. 37, no. 7, pp. 1001–1008, 1989. [11] Robert Moore, Douglas Appelt, John Dowding, J Mark Gawron, and Douglas Moran, “Combining linguistic and statistical knowledge sources in natural-language processing for A TIS, ” in Pr oc. ARP A Spoken Language Systems T echnology W orkshop , 1995. [12] Hong-Kwang Jeff Kuo and W olfgang Reichl, “Phrase-based lan- guage models for speech recognition, ” in Sixth Eur opean Confer ence on Speech Communication and T echnolo gy , 1999. [13] Ronald Rosenfeld, “T wo decades of statistical language modeling: Where do we go from here?, ” Pr oceedings of the IEEE , vol. 88, no. 8, pp. 1270–1278, 2000. [14] Ebru Arisoy , T ara N Sainath, Brian Kingsbury , and Bhuvana Ram- abhadran, “Deep neural network language models, ” in Proceedings of the NAA CL-HLT 2012 W orkshop: Will W e Ever Really Replace the N-gram Model? On the Futur e of Language Modeling for HLT . Association for Computational Linguistics, 2012, pp. 20–28. [15] T omas Mikolov , Martin Karafiát, Lukas Burget, Jan Cernock ` y, and Sanjeev Khudanpur, “Recurrent neural network based language model., ” in Pr oceedings of Interspeech , 2010, v ol. 2, p. 3. [16] Martin Sunderme yer, Ralf Schlüter , and Hermann Ney , “LSTM neu- ral networks for language modeling., ” in Pr oceedings of Interspeech , 2012, pp. 194–197. [17] Ilya Sutskever , Oriol V inyals, and Quoc V Le, “Sequence to sequence learning with neural networks, ” in Advances in neural information pr ocessing systems , 2014, pp. 3104–3112. [18] Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk, Philemon Brakel, and Y oshua Bengio, “End-to-end attention-based large vocab ulary speech recognition, ” in Pr oceedings of Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Confer- ence on . IEEE, 2016, pp. 4945–4949. [19] William Chan, Navdeep Jaitly , Quoc Le, and Oriol Vin yals, “Listen, attend and spell: A neural network for large vocabulary conv ersa- tional speech recognition, ” in Pr oceedings of Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE International Confer ence on . IEEE, 2016, pp. 4960–4964. L E A R N I N G F RO M PA S T M I S TA K E S 15 [20] William A Ainsworth and SR Pratt, “Feedback strategies for error correction in speech recognition systems, ” International Journal of Man-Machine Studies , v ol. 36, no. 6, pp. 833–842, 1992. [21] JM Noyes and CR Frankish, “Errors and error correction in auto- matic speech recognition systems, ” Er gonomics , vol. 37, no. 11, pp. 1943–1957, 1994. [22] Bernhard Suhm, Brad Myers, and Alex W aibel, “Multimodal error correction for speech user interfaces, ” ACM transactions on computer-human interaction (TOCHI) , vol. 8, no. 1, pp. 60–98, 2001. [23] Arup Sarma and David D Palmer , “Context-based speech recogni- tion error detection and correction, ” in Proceedings of HLT -NAA CL 2004: Short P apers . Association for Computational Linguistics, 2004, pp. 85–88. [24] Eric K Ringger and James F Allen, “Error correction via a post- processor for continuous speech recognition, ” in Acoustics, Speech, and Signal Pr ocessing, 1996. ICASSP-96. Conference Pr oceedings., 1996 IEEE International Confer ence on . IEEE, 1996, vol. 1, pp. 427–430. [25] Minwoo Jeong, Sangkeun Jung, and Gary Geunbae Lee, “Speech recognition error correction using maximum entropy language model, ” in Pr oc. of INTERSPEECH , 2004, pp. 2137–2140. [26] Luis Fernando Dâ ˘ A ´ ZHaro and Rafael E Banchs, “ Automatic cor- rection of ASR outputs by using machine translation, ” Interspeech, 2016. [27] Horia Cucu, Andi Buzo, Laurent Besacier, and Corneliu Burileanu, “Statistical error correction methods for domain-specific ASR sys- tems, ” in International Conference on Statistical Language and Speech Pr ocessing . Springer , 2013, pp. 83–92. [28] Y ik-Cheung T am, Y un Lei, Jing Zheng, and W en W ang, “ Asr error detection using recurrent neural network language model and com- plementary ASR, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Conference on . IEEE, 2014, pp. 2312–2316. [29] D. Zheng, Z. Chen, Y . W u, and K. Y u, “Directed automatic speech transcription error correction using bidirectional LSTM, ” in 2016 10th International Symposium on Chinese Spoken Language Pr ocessing (ISCSLP) , Oct 2016, pp. 1–5. [30] Ryohei Nakatani, T etsuya T akiguchi, and Y asuo Ariki, “T wo-step correction of speech recognition errors based on n-gram and long contextual information., ” in INTERSPEECH , 2013, pp. 3747–3750. [31] E Byambakhishig, Katsuyuki T anaka, Ryo Aihara, T oru Nakashika, T etsuya T akiguchi, and Y asuo Ariki, “Error correction of automatic speech recognition based on normalized web distance, ” in F ifteenth Annual Conference of the International Speech Communication Association , 2014. [32] Y ohei Fusayasu, Katsuyuki T anaka, T etsuya T akiguchi, and Y asuo Ariki, “W ord-error correction of continuous speech recognition based on normalized relev ance distance., ” in IJCAI , 2015, pp. 1257–1262. [33] P .C. W oodland and D. Pov ey , “Large scale discriminative training of hidden Markov models for speech recognition, ” Computer Speech & Language , v ol. 16, no. 1, pp. 25 – 47, 2002. [34] Brian Roark, Murat Saraclar, and Michael Collins, “Discriminativ e n-gram language modeling, ” Computer Speec h & Language , vol. 21, no. 2, pp. 373–392, 2007. [35] Kenji Sagae, Maider Lehr , E Prud’hommeaux, Puyang Xu, Nathan Glenn, Damianos Karak os, Sanjeev Khudanpur , Brian Roark, Murat Saraclar , Izhak Shafran, et al., “Hallucinated n-best lists for discrim- inativ e language modeling, ” in Acoustics, Speech and Signal Pro- cessing (ICASSP), 2012 IEEE International Conference on . IEEE, 2012, pp. 5001–5004. [36] Puyang Xu, Brian Roark, and Sanjeev Khudanpur, “Phrasal cohort based unsupervised discriminativ e language modeling, ” in Thir- teenth Annual Confer ence of the International Speech Communica- tion Association , 2012. [37] Dan Bikelf, Chris Callison-Burchc, Y uan Caoc, Nathan Glennd, Keith Hallf, Eva Haslerg, Damianos Karakosc, Sanjeev Khudanpurc, Philipp Koehng, Maider Lehrb, et al., “Confusion-based statistical language modeling for machine translation and speech recognition, ” 2012. [38] Arda Celebi, Hasim Sak, Erinç Dikici, Murat Saraçlar , Maider Lehr , E Prud’hommeaux, Puyang Xu, Nathan Glenn, Damianos Karakos, Sanjeev Khudanpur, et al., “Semi-supervised discriminative lan- guage modeling for Turkish ASR, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2012 IEEE International Confer ence on . IEEE, 2012, pp. 5025–5028. [39] Peter F Bro wn, John Cocke, Stephen A Della Pietra, V incent J Della Pietra, Fredrick Jelinek, John D Lafferty , Robert L Mercer , and Paul S Roossin, “ A statistical approach to machine translation, ” Computational linguistics , vol. 16, no. 2, pp. 79–85, 1990. [40] Philipp Koehn, Franz Josef Och, and Daniel Marcu, “Statistical phrase-based translation, ” in Proceedings of the 2003 Confer ence of the North American Chapter of the Association for Computational Linguistics on Human Language T echnology-V olume 1 . ACL, 2003, pp. 48–54. [41] Ashish V aswani, Y inggong Zhao, V ictoria Fossum, and David Chi- ang, “Decoding with large-scale neural language models improves translation., ” in Proceedings of the 2013 Conference on Empiri- cal Methods in Natural Language Pr ocessing . EMNLP , 2013, pp. 1387–1392. [42] Jacob Devlin, Rabih Zbib, Zhongqiang Huang, Thomas Lamar, Richard M Schwartz, and John Makhoul, “Fast and robust neu- ral network joint models for statistical machine translation., ” in Pr oceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, . A CL, 2014, pp. 1370–1380. [43] T amer Alkhouli, Felix Rietig, and Hermann Ney , “Inv estigations on phrase-based decoding with recurrent neural network language and translation models, ” in Proceedings of the T enth W orkshop on Statistical Machine T ranslation , 2015, pp. 294–303. [44] Franz Josef Och, “Minimum error rate training in statistical machine translation, ” in Pr oceedings of the 41st Annual Meeting on Asso- ciation for Computational Linguistics-V olume 1 . ACL, 2003, pp. 160–167. [45] Christopher Cieri, David Miller , and Ke vin W alker, “The Fisher Corpus: a resource for the next generations of speech-to-text., ” in International Conference on Language Resources and Evaluation . LREC, 2004, vol. 4, pp. 69–71. [46] Anthony Rousseau, Paul Deléglise, and Y annick Estève, “Enhanc- ing the TED-LIUM corpus with selected data for language modeling and more TED talks., ” in International Confer ence on Language Resour ces and Evaluation . LREC, 2014, pp. 3935–3939. [47] Daniel Povey , Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, et al., “The Kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech reco gnition and understanding . IEEE Signal Processing Society , 2011, number EPFL-CONF-192584. [48] Robert L W eide, “The CMU pronouncing dictionary , ” URL: http://www . speech. cs. cmu. edu/cgibin/cmudict , 1998. 16 P R A S H A N T H G U R U N A T H S H I VA K U M A R , e t a l . [49] Philipp K oehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, W ade Shen, Christine Moran, Richard Zens, et al., “Moses: Open source toolkit for statistical machine translation, ” in Pr oceedings of the 45th annual meeting of the A CL on interactive poster and demonstra- tion sessions . Association for Computational Linguistics, 2007, pp. 177–180. [50] Franz Josef Och and Hermann Ney , “ A systematic comparison of various statistical alignment models, ” Computational Linguistics , vol. 29, no. 1, pp. 19–51, 2003. [51] Andreas Stolcke, “SRILM-an extensible language modeling toolkit, ” in Seventh international conference on spoken language pr ocessing , 2002. [52] Nicola Bertoldi, Barry Haddo w , and Jean-Baptiste F ouet, “Improved minimum error rate training in Moses, ” The Prague Bulletin of Mathematical Linguistics , vol. 91, pp. 7–16, 2009. [53] Daniel M Bikel and Keith B Hall, “Refr: an open-source reranker framew ork., ” in INTERSPEECH , 2013, pp. 756–758. [54] Kishore Papineni, Salim Roukos, T odd W ard, and W ei-Jing Zhu, “BLEU: a method for automatic evaluation of machine transla- tion, ” in Pr oceedings of the 40th annual meeting on association for computational linguistics . A CL, 2002, pp. 311–318. [55] Graham Neubig and T aro W atanabe, “Optimization for statistical machine translation: A survey , ” Computational Linguistics , vol. 42, no. 1, pp. 1–54, 2016. [56] Laurence Gillick and Stephen J Cox, “Some statistical issues in the comparison of speech recognition algorithms, ” in Pr oceedings of Acoustics, Speech, and Signal Processing ,. ICASSP-89., 1989 International Confer ence on . IEEE, 1989, pp. 532–535. [57] Qun Feng T an, Kartik Audhkhasi, Panayiotis G Geor giou, Emil Ette- laie, and Shrikanth S Narayanan, “ Automatic speech recognition system channel modeling, ” in Eleventh Annual Conference of the International Speech Communication Association , 2010. [58] Gakuto Kurata, Nobuyasu Itoh, and Masafumi Nishimura, “Train- ing of error-corrective model for ASR without using audio data, ” in Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Confer ence on . IEEE, 2011, pp. 5576–5579. [59] Erinç Dikici, Arda Celebi, and Murat Saraçlar , “Performance comparison of training algorithms for semi-supervised discrimina- tiv e language modeling, ” in Thirteenth Annual Conference of the International Speech Communication Association , 2012. [60] Kyunghyun Cho, Bart V an Merriënboer, Dzmitry Bahdanau, and Y oshua Bengio, “On the properties of neural machine translation: Encoder-decoder approaches, ” arXiv preprint , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment