Audio-Based Music Classification with DenseNet And Data Augmentation
In recent years, deep learning technique has received intense attention owing to its great success in image recognition. A tendency of adaption of deep learning in various information processing fields has formed, including music information retrieval (MIR). In this paper, we conduct a comprehensive study on music audio classification with improved convolutional neural networks (CNNs). To the best of our knowledge, this the first work to apply Densely Connected Convolutional Networks (DenseNet) to music audio tagging, which has been demonstrated to perform better than Residual neural network (ResNet). Additionally, two specific data augmentation approaches of time overlapping and pitch shifting have been proposed to address the deficiency of labelled data in the MIR. Moreover, an ensemble learning of stacking is employed based on SVM. We believe that the proposed combination of strong representation of DenseNet and data augmentation can be adapted to other audio processing tasks.
💡 Research Summary
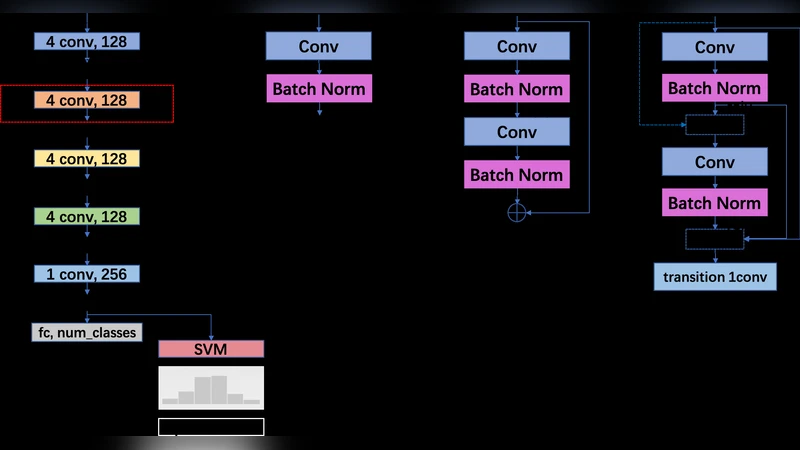
This paper presents a comprehensive study on music audio classification that introduces DenseNet—a densely connected convolutional neural network—into the music information retrieval (MIR) domain for the first time. The authors argue that conventional 2‑D convolutions over spectrograms are not fully aligned with musical semantics, and therefore adopt a 1‑D convolutional backbone that spans the entire frequency axis at each time step. The basic architecture consists of five 1‑D convolutional layers (kernel size 4), each followed by batch normalization, ReLU, and a sequence of max‑pooling layers (sizes 4, 2, 1). Two dense layers (1024 and 8 units) precede the softmax output.
To investigate the impact of modern residual connections, the authors replace the basic block with either a ResNet block (two 1‑D convolutions plus a skip connection) or a DenseNet block (two 1‑D convolutions with dense connectivity, i.e., each layer receives the concatenated feature maps of all preceding layers). A transition layer follows each DenseNet block to control channel growth. Both variants are inserted at the red‑boxed location of the baseline architecture, allowing a direct performance comparison.
Recognizing the chronic shortage of labeled music data, the paper proposes two music‑specific data augmentation techniques applied to the spectrograms:
- Time Overlapping – a 50 % overlap sliding window that creates additional training segments from the same track, effectively tripling the number of samples.
- Pitch Shifting – a half‑tone upward or downward shift performed with SoX, which alters the mel‑scale frequency distribution while preserving the genre label.
When both augmentations are combined, the training set expands to roughly three times its original size, leading to a noticeable boost in classification accuracy (approximately 3–4 % absolute).
During inference, each full audio track is sliced into ten 2.56‑second segments. Instead of a simple majority vote, the authors employ a stacking ensemble: the 1024‑dimensional feature vectors extracted from each segment are averaged, and the resulting vector is fed to a support vector machine (SVM) that produces the final genre prediction. This SVM‑based stacking consistently outperforms voting by 1–2 % absolute, especially on the GTZAN dataset where class imbalance is more pronounced.
The experimental evaluation uses two publicly available datasets:
- FMA‑small – 8,000 tracks (30 s each) across eight genres, with a 128 × 128 grayscale spectrogram representation.
- GTZAN – 1,000 tracks (30 s each) across ten genres, also converted to 128 × 128 spectrograms.
Training employs stochastic gradient descent (learning rate 1e‑2, decay 1e‑6), batch size 128, L2 regularization, and a dropout of 0.5 on the final fully‑connected layer. Zero‑padding preserves spatial dimensions throughout the network.
Results on FMA‑small show that the baseline 1‑D CNN (kernel 4, voting) achieves 59.4 % accuracy, which rises to 63.0 % with SVM and to 64.7 % when data augmentation is added. The ResNet variant placed in the black box (original location) reaches 63.7 %, while moving the ResNet block to the red box improves accuracy to 66.3 % (both with SVM and augmentation). The DenseNet variant attains the highest performance: 68.9 % on FMA‑small and 90.2 % on GTZAN.
When compared with prior state‑of‑the‑art methods—such as transfer‑learning CNNs (78 %–89 % on FMA‑small), MRMR feature selection (87.9 % on FMA‑small), and various SVM‑based classifiers—the proposed DenseNet model surpasses all reported results on FMA‑small and matches or exceeds the best scores on GTZAN, despite not using any external pre‑training data.
The authors attribute DenseNet’s superiority to its dense connectivity, which facilitates gradient flow, encourages feature reuse, and reduces the number of parameters needed for high‑capacity representations. The 1‑D convolutional design respects the temporal nature of music while still exploiting the rich time‑frequency patterns captured in spectrograms. Data augmentation proves essential for mitigating over‑fitting, and the SVM stacking effectively aggregates segment‑level predictions into a robust track‑level decision.
In conclusion, the paper demonstrates that a carefully designed 1‑D DenseNet, combined with music‑specific augmentation and a stacking ensemble, can achieve state‑of‑the‑art music genre classification without relying on large external datasets or transfer learning. Future work is outlined to explore deeper analyses of individual DenseNet layers, experiment with more sophisticated connection schemes, and adapt recent advances from computer vision (e.g., Vision Transformers, ConvNeXt) to audio tasks. Such extensions aim to further alleviate data scarcity and broaden the applicability of the proposed framework to other audio domains such as automatic tagging, emotion recognition, and acoustic scene analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment