Policy Learning for Fairness in Ranking
Conventional Learning-to-Rank (LTR) methods optimize the utility of the rankings to the users, but they are oblivious to their impact on the ranked items. However, there has been a growing understanding that the latter is important to consider for a wide range of ranking applications (e.g. online marketplaces, job placement, admissions). To address this need, we propose a general LTR framework that can optimize a wide range of utility metrics (e.g. NDCG) while satisfying fairness of exposure constraints with respect to the items. This framework expands the class of learnable ranking functions to stochastic ranking policies, which provides a language for rigorously expressing fairness specifications. Furthermore, we provide a new LTR algorithm called Fair-PG-Rank for directly searching the space of fair ranking policies via a policy-gradient approach. Beyond the theoretical evidence in deriving the framework and the algorithm, we provide empirical results on simulated and real-world datasets verifying the effectiveness of the approach in individual and group-fairness settings.
💡 Research Summary
The paper addresses a critical gap in modern learning‑to‑rank (LTR) systems: while traditional LTR algorithms focus solely on maximizing user‑centric utility metrics such as NDCG or DCG, they completely ignore the impact of the produced rankings on the items being ranked. In many multi‑sided platforms—online marketplaces, job portals, college admissions—exposure is a scarce resource that directly influences economic outcomes for the items (sellers, candidates, etc.). Ignoring fairness in exposure can amplify existing biases and create new, systematic inequities.
To remedy this, the authors propose a unified framework that treats ranking as a stochastic policy learning problem. A ranking policy π maps a query q and its candidate set to a probability distribution over all possible permutations. The expected utility U(π|q) is defined as the expectation of a standard ranking metric (the paper focuses on NDCG) under this distribution, while the expected exposure of an item di is the expected position bias vπ(di) summed over all positions the item could occupy.
Fairness is formalized through merit‑based exposure constraints. Each item’s merit M_i is a non‑negative function of its relevance (e.g., rel_i, rel_i², √rel_i). The core principle is that higher merit should never receive less exposure per unit merit than a lower‑merit item. Formally, for any pair i, j with M_i ≥ M_j > 0, the constraint vπ(di)/M_i ≤ vπ(dj)/M_j must hold. This yields an individual‑fairness disparity measure D_ind(π|q) that aggregates the maximum violation over all such pairs. A group‑fairness counterpart aggregates exposure and merit at the group level (e.g., gender, seller, publisher) and defines D_group(π|q) analogously. Both D_ind and D_group are non‑negative and vanish only when the exposure‑merit proportionality is perfectly satisfied.
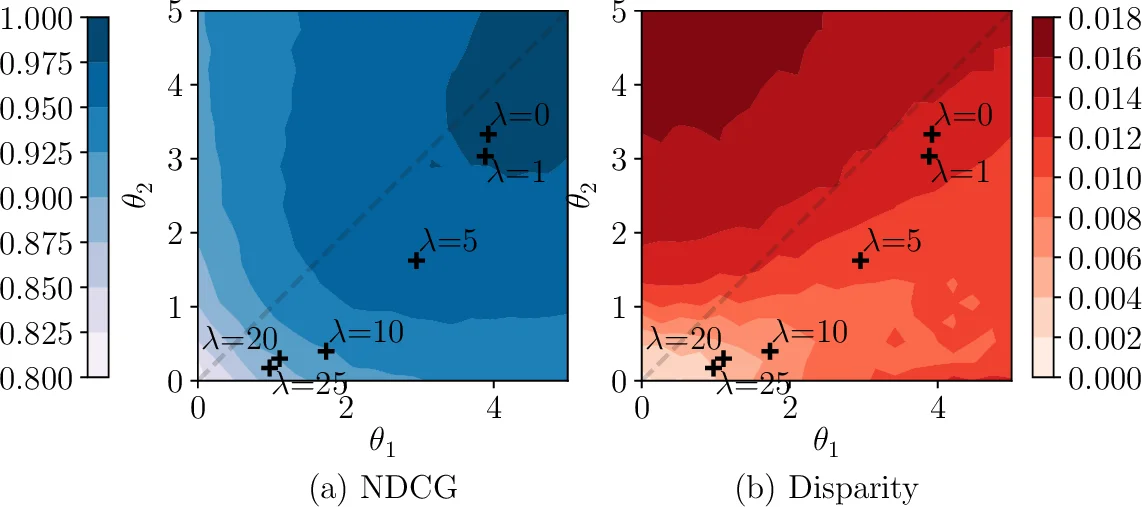
The learning objective combines utility maximization with a fairness penalty via a Lagrange multiplier λ:
max_π E_q
Comments & Academic Discussion
Loading comments...
Leave a Comment