Essence Knowledge Distillation for Speech Recognition
It is well known that a speech recognition system that combines multiple acoustic models trained on the same data significantly outperforms a single-model system. Unfortunately, real time speech recognition using a whole ensemble of models is too computationally expensive. In this paper, we propose to distill the knowledge of essence in an ensemble of models (i.e. the teacher model) to a single model (i.e. the student model) that needs much less computation to deploy. Previously, all the soften outputs of the teacher model are used to optimize the student model. We argue that not all the outputs of the ensemble are necessary to be distilled. Some of the outputs may even contain noisy information that is useless or even harmful to the training of the student model. In addition, we propose to train the student model with a multitask learning approach by utilizing both the soften outputs of the teacher model and the correct hard labels. The proposed method achieves some surprising results on the Switchboard data set. When the student model is trained together with the correct labels and the essence knowledge from the teacher model, it not only significantly outperforms another single model with the same architecture that is trained only with the correct labels, but also consistently outperforms the teacher model that is used to generate the soft labels.
💡 Research Summary
The paper addresses the well‑known trade‑off in automatic speech recognition (ASR) between the high accuracy obtained by model ensembles and the prohibitive computational cost of deploying such ensembles in real‑time applications. To bridge this gap, the authors propose “Essence Knowledge Distillation” (EKD), a method that extracts only the most informative part of the teacher’s output distribution and uses it together with the hard ground‑truth labels to train a compact student model.
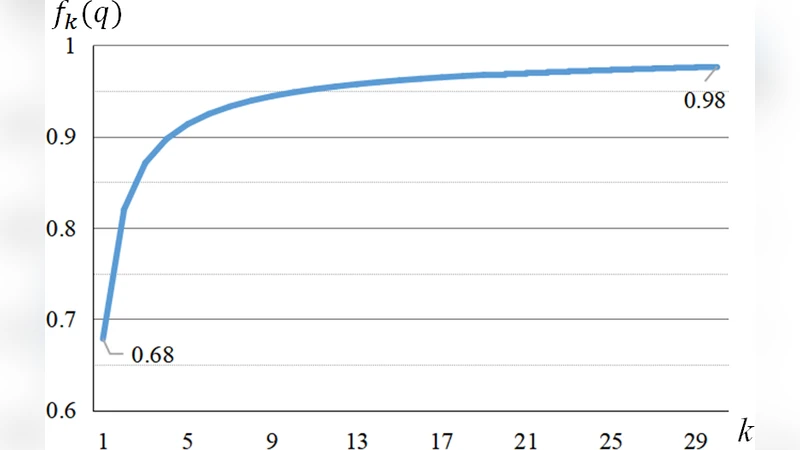
First, the authors build a strong teacher model by fusing two acoustically diverse neural networks—a Time‑Delay Neural Network (TDNN) and a hybrid TDNN‑LSTM—trained on the same 309‑hour Switchboard corpus. The fusion is performed by averaging the logits of the two sub‑models with equal weight and applying a softmax with temperature T (set to 1 in the experiments). The resulting output layer has 8,912 dimensions, reflecting the number of senone targets. An analysis of the teacher’s posterior distribution shows that the top‑1 probability averages around 0.68, the top‑10 sum to about 0.90, and the top‑40 capture roughly 0.98 of the total probability mass. Consequently, the remaining ~8,872 entries contribute only ~0.02 and are considered noisy.
EKD therefore keeps only the top‑k (k = 40) probabilities, zeroes out the rest, and renormalizes the vector to form a “soft essence” distribution. This distribution is used as the target in a Kullback‑Leibler (KL) divergence term. Simultaneously, the student model is trained on the original hard labels via a standard cross‑entropy loss. The overall objective is a weighted sum:
J(θ) = λ · J_CE + (1 − λ) · J_KL,
where λ balances the contribution of the hard‑label and soft‑essence losses (empirically set between 0.5 and 0.7). This multitask formulation ensures that the student benefits from the relational information encoded in the teacher’s soft outputs while still being anchored to the correct transcription.
Experiments are conducted on the Hub500 evaluation set (20 Switchboard and 20 CallHome conversations) using a 30‑k‑word 4‑gram language model. Input features consist of 40‑dimensional MFCCs extracted every 10 ms and 100‑dimensional i‑vectors for speaker adaptation. Training employs stochastic gradient descent with exponential learning‑rate decay and model averaging for parallelism.
Results show that the teacher ensemble achieves a total word error rate (WER) of 19.3 %. A baseline student model of identical architecture trained only on hard labels yields 20.3 % WER. When EKD is applied, the student’s WER drops to 18.9 %, surpassing the teacher despite having fewer parameters. Additional experiments varying the amount of training data (1 %, 5 %, 10 % of the full set) confirm that EKD consistently outperforms both the teacher and the hard‑label baseline across data‑scarce regimes.
The authors argue that the performance gain stems from two factors: (1) removing low‑probability, noisy entries from the teacher’s posterior reduces harmful signal that would otherwise misguide the student, and (2) the multitask loss leverages both the smooth similarity structure of the soft essence and the precise supervision of the hard labels, preventing over‑fitting to noisy teacher predictions.
In conclusion, Essence Knowledge Distillation provides a practical pathway to compress high‑performing ASR ensembles into lightweight single models without sacrificing—and even improving—recognition accuracy. The method is simple (top‑k selection and renormalization) yet effective, and it opens avenues for applying similar “essence‑only” distillation in other large‑output domains such as language modeling or multilingual speech recognition.
Comments & Academic Discussion
Loading comments...
Leave a Comment