Polyphonic Sound Event Detection by using Capsule Neural Networks
Artificial sound event detection (SED) has the aim to mimic the human ability to perceive and understand what is happening in the surroundings. Nowadays, Deep Learning offers valuable techniques for this goal such as Convolutional Neural Networks (CNNs). The Capsule Neural Network (CapsNet) architecture has been recently introduced in the image processing field with the intent to overcome some of the known limitations of CNNs, specifically regarding the scarce robustness to affine transformations (i.e., perspective, size, orientation) and the detection of overlapped images. This motivated the authors to employ CapsNets to deal with the polyphonic-SED task, in which multiple sound events occur simultaneously. Specifically, we propose to exploit the capsule units to represent a set of distinctive properties for each individual sound event. Capsule units are connected through a so-called “dynamic routing” that encourages learning part-whole relationships and improves the detection performance in a polyphonic context. This paper reports extensive evaluations carried out on three publicly available datasets, showing how the CapsNet-based algorithm not only outperforms standard CNNs but also allows to achieve the best results with respect to the state of the art algorithms.
💡 Research Summary
The paper tackles polyphonic sound event detection (SED), where multiple acoustic events may occur simultaneously, by introducing a Capsule Neural Network (CapsNet) architecture. Traditional convolutional neural networks (CNNs) and recurrent models such as CRNNs have achieved strong results on SED, but they suffer from information loss due to max‑pooling and can struggle with overlapping events, especially when training data are limited. CapsNets replace scalar neurons with vector‑valued capsules that encode a set of properties (e.g., spectral shape, temporal evolution) for each entity. A dynamic routing‑by‑agreement procedure iteratively adjusts coupling coefficients between lower‑level and higher‑level capsules, allowing the network to learn part‑whole relationships and to separate overlapping sound patterns.
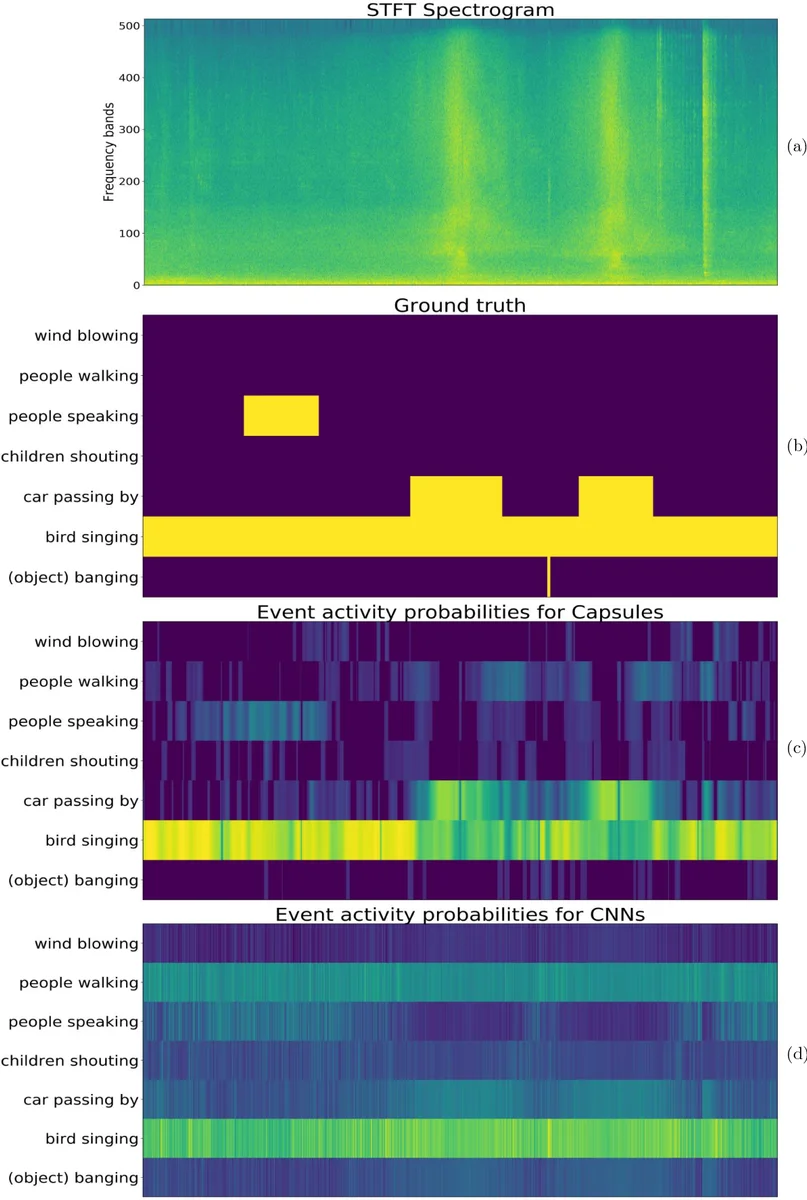
In the proposed system, raw audio sampled at 16 kHz is transformed into either magnitude STFT (513 frequency bins) or Log‑Mel (40 bins) spectrograms. A context window of 256 consecutive frames (≈5 s) is stacked, optionally for both stereo channels, yielding an input tensor of shape (256 × F × C). After two to three conventional 2‑D convolutional layers, the feature maps are reshaped into PrimaryCaps, followed by a ClassCaps layer where each capsule corresponds to a target sound class. The routing algorithm runs for three iterations; the authors also propose a temporal‑aware variant that incorporates agreement between adjacent frames, improving consistency over time. Training uses a binary cross‑entropy loss on frame‑wise labels combined with a reconstruction regularizer, optimized with Adam.
The method is evaluated on three publicly available datasets commonly used in DCASE challenges and urban sound analysis. Baselines include a standard CNN with identical input features, a CRNN, and an attention‑augmented CRNN. Performance is measured by frame‑based Error Rate (ER) and F‑score. CapsNet consistently outperforms the CNN baseline, reducing ER by roughly 12 % on polyphonic recordings and raising F‑score by 5–7 %. In monophonic scenarios the results are comparable to CNNs, indicating that the capsule advantage is most pronounced when overlapping events are present. Visualizations of routing coefficients demonstrate that the network assigns distinct capsules to different overlapping sources, confirming the intended part‑whole learning.
The authors acknowledge that CapsNet introduces a modest increase in parameter count and that the iterative routing adds computational overhead, which may hinder real‑time deployment. They suggest future work on lightweight routing mechanisms and hardware acceleration. Overall, the study provides strong empirical evidence that capsule networks can effectively model the complex, overlapping structures inherent in real‑world acoustic scenes, offering a promising new direction for polyphonic SED.
Comments & Academic Discussion
Loading comments...
Leave a Comment