Deep Neuroevolution of Recurrent and Discrete World Models
Neural architectures inspired by our own human cognitive system, such as the recently introduced world models, have been shown to outperform traditional deep reinforcement learning (RL) methods in a variety of different domains. Instead of the relatively simple architectures employed in most RL experiments, world models rely on multiple different neural components that are responsible for visual information processing, memory, and decision-making. However, so far the components of these models have to be trained separately and through a variety of specialized training methods. This paper demonstrates the surprising finding that models with the same precise parts can be instead efficiently trained end-to-end through a genetic algorithm (GA), reaching a comparable performance to the original world model by solving a challenging car racing task. An analysis of the evolved visual and memory system indicates that they include a similar effective representation to the system trained through gradient descent. Additionally, in contrast to gradient descent methods that struggle with discrete variables, GAs also work directly with such representations, opening up opportunities for classical planning in latent space. This paper adds additional evidence on the effectiveness of deep neuroevolution for tasks that require the intricate orchestration of multiple components in complex heterogeneous architectures.
💡 Research Summary
The paper investigates whether a complex, heterogeneous neural architecture—specifically the “world model” introduced by Ha and Schmidhuber—can be trained end‑to‑end using a simple genetic algorithm (GA) rather than the conventional multi‑stage pipeline that mixes unsupervised gradient‑based learning with evolutionary control. A world model consists of three modules: (1) a variational auto‑encoder (VAE) that compresses raw 64×64 RGB observations into a 32‑dimensional latent vector z, (2) a recurrent memory network (an LSTM combined with a mixture‑density output, MDN‑RNN) that predicts the distribution of the next latent state given the current state, action, and hidden state, and (3) a linear controller that maps the concatenated latent vector and LSTM hidden state to three continuous actions (steering, acceleration, braking).
In the original approach, the VAE is trained on 10 000 random rollouts, the MDN‑RNN is trained to predict future latents, and finally the controller is evolved. The authors replace this three‑phase training with a single GA that directly mutates the entire parameter vector of all three modules (≈4.3 M weights). Three mutation strategies are examined:
- MUT‑ALL – Gaussian noise (σ = 0.01) is added simultaneously to every weight in the VAE encoder, the MDN‑RNN, and the controller.
- MUT‑MOD – With equal probability, only one of the three modules is mutated in a given offspring, allowing more focused adaptation.
- MUT‑C – Only the controller is mutated; the VAE encoder and MDN‑RNN remain fixed (used as a baseline).
No crossover is employed; selection is performed via 2‑way tournament, and the top 50 % of individuals plus their offspring form the next generation. The population size is 200 and evolution runs for up to 1 000 generations. Early termination stops evaluation if the agent fails to reach a new track tile within 20 steps, reducing wasted computation.
The testbed is the OpenAI Gym CarRacing‑v0 environment, a procedurally generated 2‑D racing task where each episode presents a new track. The reward scheme penalises time (‑0.1 per frame) and rewards progress (+100/N per newly visited tile). The target benchmark, established by Ha & Schmidhuber, is an average score of 900 over 100 consecutive runs. Traditional deep RL methods (A3C, DQN, etc.) typically plateau around 600, while the original world‑model reaches ≈906 ± 21.
Results show that both MUT‑ALL and MUT‑MOD achieve the target well before the 1 200‑generation cutoff. MUT‑ALL reaches an average of 920 and a peak of 970 after ≈1 100 generations, essentially matching the original world‑model performance. MUT‑MOD performs similarly, confirming that evolving all modules jointly is feasible and that selective mutation does not hinder learning. The baseline MUT‑C (controller‑only) fails to solve the task, underscoring the necessity of co‑evolving the perception and memory components.
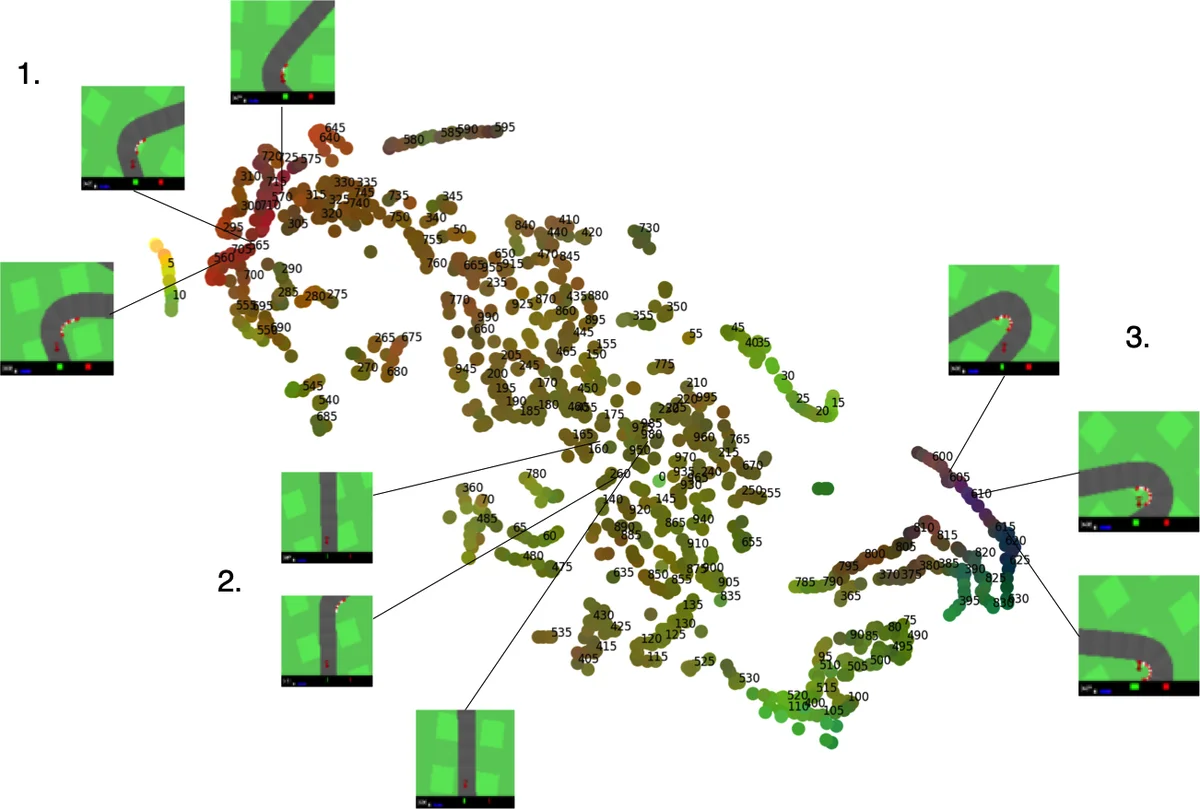
A key observation is that, despite the VAE never being directly optimized for reconstruction loss, the evolved encoder learns a latent space that clusters semantically similar visual states—mirroring the representations obtained by gradient‑based training. This emergent compression arises because the GA implicitly rewards encodings that facilitate downstream control. Likewise, the MDN‑RNN develops predictive dynamics that help the controller anticipate sharp turns, even though it is not explicitly trained to minimize prediction error.
The authors also explore a discrete latent variant (DISCRETE‑MOD), where the VAE’s continuous outputs are passed through a step function to produce binary codes. Gradient‑based methods struggle with such non‑differentiable representations, but the GA handles them naturally. The discrete model attains a respectable ≈880 average score—slightly below the continuous version—but demonstrates that evolutionary search can discover useful binary latent codes, opening the door to classical planning or symbolic reasoning in latent space.
From a methodological perspective, the work provides several insights:
- End‑to‑end neuroevolution is viable for large, multi‑component networks, challenging the belief that evolutionary algorithms cannot scale to millions of parameters.
- Representation learning can emerge without explicit reconstruction or prediction losses, suggesting that task‑driven fitness alone can shape useful perceptual embeddings.
- Discrete latent spaces are naturally accommodated, offering a straightforward path to integrate planning algorithms that require symbolic or binary state descriptions.
- Mutation hyper‑parameters (σ, module‑wise probability) significantly affect learning speed, hinting at the potential of adaptive or meta‑evolutionary strategies.
The paper concludes that deep neuroevolution is a competitive alternative to gradient‑based methods for tasks demanding coordinated operation of heterogeneous modules. Future directions include evolving the architecture itself (structural evolution), applying the approach to multi‑task or transfer learning scenarios, and coupling the evolved binary latent space with explicit planning or symbolic AI techniques.
Overall, the study convincingly demonstrates that a simple GA can replace a sophisticated, multi‑stage training pipeline, achieving comparable performance on a challenging control benchmark while also offering unique advantages for discrete representations and integrated planning.
Comments & Academic Discussion
Loading comments...
Leave a Comment