Graphical Models for Discrete and Continuous Data
We introduce a general framework for undirected graphical models. It generalizes Gaussian graphical models to a wide range of continuous, discrete, and combinations of different types of data. The models in the framework, called exponential trace mod…
Authors: Rui Zhuang, Noah Simon, Johannes Lederer
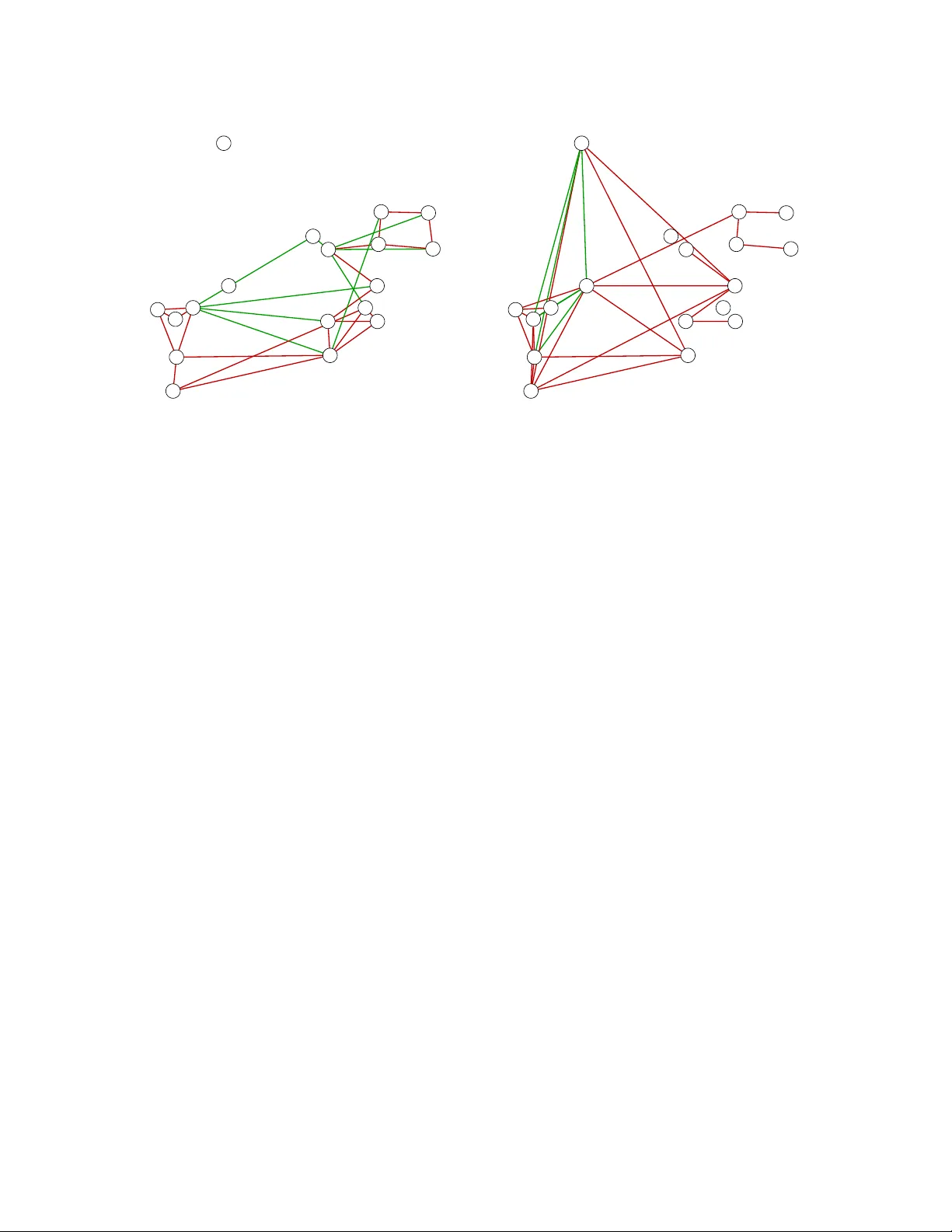
Graphical Mo dels for Discrete and Con tin uous Data Rui Zh uang Departmen t of Biostatistics, Universit y of W ashington and Noah Simon Departmen t of Biostatistics, Universit y of W ashington and Johannes Lederer Departmen t of Mathematics, Ruhr-Universit y Bo c h um June 18, 2019 Abstract W e in tro duce a g eneral framew ork for undirected graphical mo dels. It generalizes Gaussian graphical mo dels to a wide range of conti n uous, discrete, and com binations of different types of data. The mo dels in the framew ork, called exp onential trace mo dels, are amenable to estimation based on maximum likelihoo d. W e in tro duce a sampling-based approximation algorithm for computing the maximum likelihoo d estimator, and we apply this pip eline to learn sim ultaneous neural activities from spik e data. Keywor ds: Non-Gaussian Data, Graphical Mo dels, Maximum Likelihoo d Estimation 1 In tro duction Gaussian graphical mo dels (Drton & Maathuis 2016, Lauritzen 1996, W ain wright & Jordan 2008) describe the dependence structures in normally distributed random v ectors. These mo dels ha v e become increasingly p opular in the sciences, b ecause their represen tation of the dep endencies is lucid and can b e readily estimated. F or a brief ov erview, consider a 1 random v ector X ∈ R p that follo ws a cen tered normal distribution with densit y f Σ ( x ) = 1 (2 π ) p/ 2 p | Σ | e − x > Σ − 1 x / 2 (1) with resp ect to Leb esgue measure, where the p opulation co v ariance Σ ∈ R p × p is a symmetric and p ositiv e definite matrix. Gaussian graphical mo dels asso ciate these densities with a graph ( V , E ) that has v ertex set V := { 1 , . . . , p } and edge set E := { ( i, j ) : i, j ∈ { 1 , . . . , p } , i 6 = j, Σ − 1 ij 6 = 0 } . The graph enco des the dependence structure of X in the sense that any t w o entries X i , X j , i 6 = j, are conditionally indep enden t given all other entries if and only if ( i, j ) / ∈ E . A natural and straightforw ard estimator of Σ − 1 , and th us of E , is the inv erse of the empirical co v ariance, which is also the maximum likelihoo d estimator. Inference can then b e approac hed via the quan tiles of the normal distribution. The problem with Gaussian graphical mo dels is that in practice, data often violate the normalit y assumption. Data can b e discrete, hea vy-tailed, restricted to p ositive v alues, or deviate from normality in other w a ys. Graphical mo dels for some types of non-Gaussian data ha ve b een developed, including copula-based mo dels (Gu et al. 2015, Liu et al. 2012, 2009, Xue & Zou 2012), score matc hing approach (Lin et al. 2016, Y u et al. 2019), Ising mo dels (Brush 1967, Lenz 1920), and multinomial extensions of the Ising mo dels (Loh & W ain wrigh t 2013). Ho w ev er, there is no general framework that comprises differen t data t yp es including finite and infinite coun t data, potentially hea vy-tailed contin uous data, and combinations of discrete and contin uous data and at the same time, ensures a rigid theoretical structure. W e mak e three main con tributions in this paper: • W e formulate a general framework for undirected graphical mo dels that b oth encom- passes previously studied and new mo dels for con tin uous, discrete, and com bined data t yp es. • W e sho w that maxim um lik eliho o d is based on a conv ex and smo oth optimization function and provides consistent estimation and inference for the mo del parameters in the framework. • W e establish a sampling-based appro ximation algorithm for computing the maxim um lik eliho o d estimator. 2 Let us ha ve a glance at the framework. F or this, w e start with the Gaussian densities (1). Our first observ ation is that − x > Σ − 1 x / 2 = −h Σ − 1 , xx > / 2 i tr , where h· , ·i tr is the trace inner pro duct. This formulation lo oks “somewhat less rev ealing” (Eaton 2007, P age 125) on first sigh t, but it has t w o conceptual adv an tages. First, w e argue that writing the parameters and the data as algebraic duals of each other makes their relationship more symmetric. Second, w e argue that it is a go o d starting p oin t for generalizations. F or this, w e take the viewp oin t that the exp onents in the densities are linear functions of the matrix xx > / 2 , and then replace this matrix by a general matrix-v alued function T of x . Our second observ ation is that the fundamental quan tit y in the family of Gaussian graphical mo dels is the in verse co v ariance matrix Σ − 1 rather than the co v ariance matrix Σ itself. This suggests a reparametrization of the mo del using the matrix Σ − 1 , whic h is then replaced by a general matrix M . This subtlety is imp ortan t: as we will see later, the matrix M con tains all information ab out the dep endence structure of X , while the equalit y of M − 1 and the co v ariance matrix is a mere coincidence in the Gaussian case. With these t w o observ ations in mind, and denoting the log-normalization by γ (M) , with γ (M) = log ((2 π ) p | M − 1 | ) / 2 in the Gaussian case, we can then generalize the densities (1) to f M ( x ) = e −h M , T ( x ) i tr − γ (M) with resp ect to an arbitrary σ -finite measure ν , and with M , T ∈ R q × q a matrix-v alued parameter and data function, resp ectively . While additional data terms can b e absorb ed in the measure ν , it is sometimes illustrative to write them explicitly . W e th us consider distributions with densities of the form f M ( x ) = e −h M , T ( x ) i tr + ξ ( x ) − γ (M) , where ξ ( x ) dep ends on x only . These densities form an exp onential family indexed by M and are called exp onential trace mo dels in the following for con v enience. W e recall that the w ell-known pairwise interaction mo dels can also b e written in exp o- nen tial form, but there are important differences to the ab o v e formulation. First, pairwise in teraction mo dels and exp onen tial trace mo dels are not sub-classes of one another: ex- p onen tial trace mo dels are not limited to pairwise interactions, while pairwise interaction mo dels are not limited to canonical parameterizations. Y et, imp ortantly , exp onen tial trace 3 mo dels generalize pairwise in teraction models in the sense that all generic examples of pairwise interaction mo dels are encompassed. W e also highligh t that in contrast to pair- wise in teraction mo dels, w e allow for q 6 = p, whic h helps for concise formulations of mixed graphical models, for example. In general, we argue that the exponential trace framework is a practical starting p oin t for general studies of graphical mo dels, b ecause it comprises a v ery large v ariety of examples and still ensures a firm theoretical structure. W e carefully specify and study the described distributions in the follo wing sections. Section 2 contains the prop osed framework: we define the densities in Section 2.1, and w e discuss a v ariety of examples in Sections 2.2 and 2.3. Section 3 is fo cused on estimation: w e discuss the maxim um likelihoo d estimator for the mo del parameters in Section 3.1, and w e introduce a n umerical algorithm in Sections 3.2. Section 4 shows simulation results for differen t types of data. Section 5 applies the metho d to neural spike data. W e conclude the paper with a discussion in Section 6. The pro ofs are deferred to the Appendix. Notation F or matrices A, B ∈ R s × t , s, t ∈ { 1 , 2 , . . . } , we denote the trace inner pro duct (or F rob enius inner product) by h A, B i tr := tr A > B = s X i =1 t X j =1 A ij B ij and the corresp onding norm by | | A | | tr := p h A, A i tr = v u u t s X i =1 t X j =1 A 2 ij . W e consider random vectors X = ( X 1 , . . . , X p ) > ∈ R p . W e denote random vectors and their realizations b y upp er case letters such as X and arguments of functions b y lo wer case, b oldface letters such as x . Giv en a set S ⊂ { 1 , . . . , p } , w e denote b y X S ∈ R | S | the v ector that consists of the co ordinates of X with indices in S, and we set X − S := X S c ∈ R p −| S | . Indep endence of t wo elemen ts X i and X j , i 6 = j, is denoted b y X i ⊥ X j ; conditional indep endence of X i and X j giv en all other elemen ts is denoted b y X i ⊥ ⊥ X j | X −{ i,j } . 4 2 F ramew ork W e first discuss our framework. In Section 2.1, we formulate the densities. In Section 2.2, w e sho w that these densities apply to standard examples of graphical mo dels. In Section 2.3, w e study additional examples. 2.1 Exp onen tial T race Mo dels In th is section, we form ulate probabilistic mo dels for vector-v alued observ ations that hav e dep enden t co ordinates. Sp ecifically , w e consider arbitrary (non-empty) finite or contin uous domains D ⊂ R p and random vectors X ∈ D that ha v e densities of the form f M ( x ) := e −h M , T ( x ) i tr + ξ ( x ) − γ (M) (2) with resp ect to some σ -finite measure ν on D . F or reference, w e call these mo dels exp o- nen tial trace mo dels. W e b egin b y sp ecifying the different components of our mo del. The densities are indexed b y M ∈ M , where M is a subset of M ∗ := in terior { M ∈ R q × q : γ (M) < ∞} . Unlik e con v en tional framew orks, we do not require q = p, with the adv antage of concise form ulations of mixture mo dels, for example. In generic applications, M comprises the dep endence structure of X and determines if tw o co ordinates X i and X j are p ositively or negativ ely correlated. W e will discuss these asp ects in the next sections. The arguably most imp ortant note here is that the in tegrability condition γ (M) < ∞ is feasible. In particular, our framework pro vides natural form ulations of mo dels that a v oid unreasonable restrictions on the parameter space. It is b est to see this in sp ecific examples, so that we defer to later. Next, the data enters the mo del via a matrix-v alued function T : D → R q × q x 7→ T ( x ) 5 and a real-v alued function ξ : D → R x 7→ ξ ( x ) , and γ (M) is the normalization defined as γ (M) := log Z D e −h M , T ( x ) i tr + ξ ( x ) dν . W e finally hav e to imp ose t w o tec hnical assumptions on the parameter space. Our first assumption is that the function M 7→ f M of M to the densities with resp ect to the measure ν is bijectiv e. Sufficien t conditions for this are pro vided in (Berk 1972, P age 199) and (Johansen 1979, Definition 1.3); we stress, how ever, that the bijection is required here only on M rather than on the full set M ∗ . Our second assumption is that M is conv ex and that M is op en with resp ect to an affine subspace of R q × q . The tw o assumptions ensure, in particular, that the parameter M is identifiable and has a compact and “full-dimensional” neigh b orho o d in an affine subspace of R q × q . Imp ortan tly , ho w ev er, the assumptions are mild enough to allow for o v erparametrizations in the sense that M do es not hav e to b e op en in R q × q ; a t ypical example is M equal to the set of symmetric matrices, seen in Sections 2.2 and 2.3. The exp onential family formulation equips the framework with desirable structure. In particular, w e can deriv e the following. Lemma 2.1. The fol lowing two pr op erties ar e satisfie d. 1. The set M ∗ is c onvex; 2. for any M ∈ M ∗ , the c o or dinates of T ( X ) have moments of al l or ders with r esp e ct to f M . Prop ert y 1 ensures that M = M ∗ satisfies the ab ov e assumption about M and Prop erty 2 ensures concen tration of the maxim um lik eliho o d estimator discussed later. 2.2 Standard Graphical Models The goal of this section is to demonstrate that standard graphical mo dels, such as Ising mo dels with binary and m -ary resp onses and Gaussian and non-paranormal graphical mo d- 6 els, fit the exp onen tial trace framew ork. In com bination with the results in Section 3, this sho ws in particular that standard graphical models are automatically equipp ed with more structure than suggested by common pairwise in teraction form ulations. F or the standard mo dels, it is sufficient to consider q = p, T ij ( x ) ≡ T ij ( x i , x j ) , and ξ ( x ) = P p j =1 ξ j ( x j ) . Given M , we then define a graph G := ( V , E ) , where V := { 1 , . . . , p } is the v ertex (or node) set and E := { ( i, j ) : i, j ∈ V , i 6 = j, M ij 6 = 0 } the edge set. T w o matrices M , M 0 ∈ M ⊂ R p × p corresp ond to the same graph if and only if their non- zero patterns are the same. In view of the examples b elow, we are particularly interested in symmetric dep endence structures, that is, we consider symmetric matrices M in what follo ws. Then, also the edge set E is symmetric, that is, ( i, j ) ∈ E if and only if ( j, i ) ∈ E , and the graph G is called undirected. The corresp onding mo dels f M are a sp ecial case of pairwise interaction mo dels (pairwise Mark o v net works). Assuming that ν is a pro duct measure, a density h with respect to ν is a pairwise interaction mo del if it can b e written in the form h ( x ) = p Y i,j =1 h ij ( x i , x j ) with p ositiv e functions h ij . This means that the densities of pairwise interaction mo dels can be written as products of terms that dep end on at most t wo co ordin ates. The graph G now enco des the conditional dep endence structure, as one can show by applying the Hammersley-Clifford theorem (Besag 1974, Grimmett 1973). The theorem implies that for a strictly p ositive densit y h ( x ) with resp ect to a pro duct measure, t w o ele- men ts X i , X j are conditionally indep endent giv en all other co ordinates if and only if we can write h ( x ) = h 1 ( x − i ) h 2 ( x − j ) , where h 1 , h 2 are p ositive functions. F or the describ ed densi- ties in our framew ork, we can write f M ( x ) = f 1 M ( x − i ) f 2 M ( x − j ) with p ositive functions f 1 M , f 2 M if and only if M ij = 0 . By the ab ov e definition of the graph asso ciated with M , the latter is equiv alen t to ( i, j ) / ∈ E . W e th us find X i ⊥ ⊥ X j | X −{ i,j } if and only if ( i, j ) / ∈ E , meaning that the conditional dep endence structure of X is represen ted b y the edge set E . The graph G also determines the unconditional dep endence structure. T o illustrate this, we define E as the set of all connected comp onents in M , that is, ( i, j ) ∈ E if and only 7 M = 1 . 2 − 0 . 2 0 0 − 0 . 2 1 . 5 0 0 . 1 0 0 1 0 0 0 . 1 0 0 . 5 1 2 4 3 Figure 1: Example of a matrix M (left) and the corresp onding graph G (righ t). The v ertex set of the graph is V = { 1 , 2 , 3 , 4 } , the edge set of the graph is E = { (1 , 2) , (2 , 1) , (2 , 4) , (4 , 2) } . The enlarged edge set is E = E ∪ { (1 , 4) , (4 , 1) } . F or example, X 1 and X 4 are dep enden t (indicated by (1 , 4) ∈ E ), but they are conditionally indep endent giv en the other elemen ts of X (indicated b y (1 , 4) / ∈ E ). if there is a path ( i, i 1 ) , ( i 1 , i 2 ) . . . , ( i q , j ) ∈ E that connects i and j (in particular, E ⊂ E ). F or pairwise densities in our framew ork, it is easy to chec k that X i ⊥ X j if and only if ( i, j ) / ∈ E . Hence, the dep endence structure of X is captured by E . W e giv e an illustration of these prop erties in Figure 1. W e can now turn to the examples. 2.2.1 Coun ting Measure W e first describ e t w o cases where the base measure ν is the counting measure on { 0 , 1 , . . . } p . Sp ecifically , we show that the well-kno wn Ising and m ultinomial Ising mo dels are encom- passed b y our framew ork. Bey ond the measure, a unifying prop ert y of the tw o examples is that the in tegrabilit y condition is satisfied for all matrices. In a formula, this reads γ (M) < ∞ for all M ∈ R p × p . (3) Since the set of all matrices in R p × p is open, the in tegrabilit y prop erty (3) means that M ∗ = { M ∈ R p × p } . 8 This ensures that any con vex and (relativ ely) open set M ⊂ R p × p meets our tec hnical assumptions. Imp ortan tly , w e sho w later that the same prop erties are shared b y exp onen tial trace models for P oisson data. Ising The Ising mo del has a v ariet y of applications, for example, in Statisti cal Mec hanics and Quan tum Field Theory (Gallav otti 2013, Zub er & Itzykson 1977). Its densities are prop ortional to e P p j =1 a j j x j + P j,k a j k x j x k with a j k = a kj , and the domain is x 1 , . . . , x p ∈ { 0 , 1 } . As an illustration, consider a material that consists of p molecules with one “magnetic” electron each. The binary v ariable x j then corresp onds to the electron’s spin (up or down in a given direction) in the j th molecule, and the factor a j k determines whether the spins of the electrons in the j th and k th molecule tend to align ( a j k > 0 as in ferromagnetic materials) or tend to take opp osite directions ( a j k < 0 as in an ti-ferromagnetic materials). The Ising model is a sp ecial case of our framew ork (2). Indeed, since 1 2 = 1 and 0 2 = 0 , we can obtain the desired densities by setting D = { 0 , 1 } p , q = p, M ij = − a ij , T ij ( x ) = x i x j , and ξ ≡ 0 . Since the domain is finite, the in tegrability condition γ (M) < ∞ is naturally satisfied for all matrices M . Multinomial Ising The spin of spin 1 / 2 particles (suc h as the electron) can take tw o v alues. Th us, the corresp onding measurements can b e represen ted by the domain { 0 , 1 } as in the Ising mo del discussed ab ov e. In con trast, the spin of spin s particles with s ∈ { 1 , 3 / 2 , . . . } (such as W and Z v ector b osons and comp osite particles) can tak e 2 s + 1 v alues, whic h can not b e represented by binaries directly . Therefore, the m ultinomial Ising mo del, which extends the Ising mo del to m ultinomial domains, is of considerable interest in quan tum physics. F or similar reasons, m ultinomial Ising mo dels are of in terest in other fields, see (Diesner & Carley 2005) for an example in so ciology . W e now show that also the m ultinomial Ising mo del is a sp ecial case of our framework. F or this, we enco de the data in an enlarged binary vector. W e first denote the original m ultinomial data by Y ∈ { 0 , . . . , m − 1 } l . This could corresp ond to l spin ( m − 1) / 2 particles. W e then represent the data with an enlarged binary v ector X ∈ { 0 , 1 } p , p = l · ( m − 1) , b y 9 setting X i = 1 l n Y j = i − ( m − 1) b i − 1 m − 1 c , j = d i m − 1 e o ∈ { 0 , 1 } . Eac h co ordinate of the original data (for example, eac h spin) is now represented b y m − 1 binary v ariables. W e can use the same mo del as ab ov e, except for imp osing the additional requiremen t M ij = 0 if d i m − 1 e = d j m − 1 e to av oid self-in teractions. These settings yield the standard extension of the Ising mo del to multinomial data, cf. (Loh & W ain wright 2013). In particular, for m = 2 , we recov er the Ising mo del ab ov e. Again, since the domain is finite, the integrabilit y condition γ (M) < ∞ is naturally satisfied for all matrices M . 2.2.2 Con tinuous Measure W e now consider tw o examples in which the base measure ν is the Leb esgue measure on R p . Sp ecifically , w e show that Gaussian and non-paranormal graphical mo dels are encompassed b y our framework. W e show that the integrabilit y condition is satisfied for all matrices that are p ositiv e definite. In a form ula, this reads γ (M) < ∞ for all p ositive definite M ∈ R p × p . (4) Since the set of all positive definite matrices in R p × p is open, this means that M ∗ ⊃ { M ∈ R p × p : M p ositiv e definite } . One can thus take any conv ex and (relativ ely) op en set of p ositiv e definite matrices as parameter space M . Later, we will show that very similar mo dels can also b e formulated for exponential data, for example. Gaussian The most p opular examples are Gaussian graphical mo dels (Lauritzen 1996). F or centered data (which can b e assumed without loss of generality), these mo d els cor- resp ond to random vectors X ∼ N p (0 , Σ) , where Σ (and thus also Σ − 1 ) is a symmetric, p ositiv e definite matrix. W e can generate these mo dels in our framework (2) by setting D = R p , q = p, M = Σ − 1 , T ij ( x ) = x i x j / 2 , and ξ ≡ 0 . Gaussian graphical mo dels are well-studied and are also the starting point for our con tribution. It is th us especially imp ortant to disentangle general prop erties of graphical 10 mo dels in our framew ork from p eculiarities of the Gaussian case. First, the corresp ondence of the conditional indep endence structure and the non-zero pattern of the inv erse co v ariance matrix is sp ecific to the Gaussian case. This has already b een pointed out in (Loh & W ain wrigh t 2013), where relationships b etw een the dep endence structure and the inv erse co v ariance matrix in Ising mo dels and other exp onential families with additional in teraction terms are studied. How ever, instead of concen trating on p ossible connections, we argue that it is imp ortan t to distinguish clearly b etw een the t w o concepts. In our framework, the (conditional) dep endencies are completely captured by the matrix M . It is thus reasonable to consider M the fundamental quantit y . Instead, the equality of M − 1 and E M [ X X > ] is sp ecific to the Gaussian case, and the (generalized) co v ariances E M [ X X > ] ( 2 E M T ( X ) ) and their inv erse should b e viewed only as a characteristic of the mo del. Second, the t yp e of the no de conditionals can change once dependencies are in tro duced. In the Gaussian case, the no de conditionals are normal irresp ective of M . In most other cases, ho w ever, the types of no de conditionals cannot b e the same in the dep endent and indep enden t case - unless additional assumptions are introduced. W e will discuss this in the later examples b elo w. Non-paranormal W ell-kno wn generalizations of Gaussian graphical models are non- paranormal graphical mo dels (Liu et al. 2009). These mo dels corresp ond to vectors X suc h that ( g 1 ( X 1 ) , . . . , g p ( X p )) > ∼ N p (0 , Σ) for real-v alued, monotone, and differen tiable functions g 1 , . . . , g p and symmetric, p ositiv e definite matrix Σ . These models can b e generated in our framew ork b y setting D = R p , q = p, M = Σ − 1 , T ij ( x ) = g i ( x i ) g j ( x j ) / 2 , and ξ ( x ) = P p j =1 log | g 0 j ( x j ) | , cf. (Liu et al. 2009, Equation (2)). The normalization constant is (irresp ectiv e of symmetry) γ (M) = log((2 π ) p | M − 1 | ) / 2 < ∞ b oth in the Gaussian and the non-paranormal case, so that in both cases, prop ert y (4) is satisfied. 2.3 Non-standard Examples The idea that Ising mo dels as well as other standard graphical mo dels can b e written as exp onen tial families is not new (W ainwrigh t & Jordan 2008, Chapter 3.3). How ever, we argue that the details of the notions and form ulations are essen tial, esp ecially when it 11 comes to establishing mo dels for data that are not cov ered b y standard graphical mo dels. W e will outline this in the follo wing. W e first discuss P oisson and exp onential distributions. In particular, we establish thorough pro ofs for the integrabilit y of the square-ro ot mo dels in (Inouye et al. 2016) and in tro duce extensions that show that the square-ro ot is just one out of man y p ossible op erations for the interaction terms and that a v ariet y of distributions b esides P oisson can b e handled. P oisson A main ob jective in systems biology is the inference of microbial in teractions. The corresp onding data is multiv ariate coun t data with infinite range (F aust et al. 2012). Other fields where suc h data is prev alen t include particle phy sics (radioactiv e deca y of particles) and criminalistics (n um b er of crimes and arrests). How ever, copula-based ap- proac hes to infinite coun t data inflict sev ere iden tifiability issues (Genest & Nešleho v á 2007), while standard extensions of the indep endent case lead to integrabilit y issues, see b elo w. Multiv ariate P oisson data has thus obtained considerable attention in the recent Mac hine Learning literature (Inouy e et al. 2016, 2015, Y ang et al. 2015, 2013), but m uc h less in statistics. W e show in the follo wing that within framework (2), one can solve the problems asso- ciated with the standard approaches while preserving the Poisson fla v or of the individual co ordinates, esp ecially in the limit of small interactions. F or this, we use our framew ork with the sp ecifications D = { 0 , 1 , . . . } p , q = p, ξ ( x ) = − P p j =1 log( x j !) , and functions T that satisfy T ii ( x ) = T ii ( x i ) = x i and T ij ( x ) = T ij ( x i , x j ) ≤ c ( x i + x j ) for some c ∈ (0 , ∞ ) . W e note that the case T ij ( x ) = √ x i x j has b een in tro duced in the Mac hine Learning litera- ture (Inouye et al. 2016), but the technical asp ects of this case ha ve not b een studied, and the general setting has not been formulated altogether. Most imp ortantly , we need to show prop ert y (3). T o this end, w e hav e to verify that for all matrices M ∈ R p × p ∞ X x 1 ,...,x p =0 e − P j M j j x j − P i,j : i 6 = j M ij T ij ( x i ,x j ) Q j x j ! < ∞ . Since − M ij T ij ( x i , x j ) ≤ ˜ cx i + ˜ cx j , where ˜ c := c max i,j | M ij | , a sufficient condition is ∞ X x 1 ,...,x p =0 e − P j (M j j − 2 p ˜ c ) x j Q j x j ! < ∞ . 12 Hence, defining C (M , j ) := e − (M j j − 2 p ˜ c ) ∈ (0 , ∞ ) , j ∈ { 1 , . . . , p } , the in tegrability condition is implied for any M b y the fact ∞ X x 1 ,...,x p =0 p Y j =1 C (M , j ) x j x j ! = p Y j =1 e C (M ,j ) < ∞ . This pro ves prop erty (3). In con trast, the corresp onding integrabilit y conditions in standard approaches to this data type inflict severe restrictions on the parameter space. T o see this, recall that the join t densit y of p indep endent P oisson random v ariables with parameters a 1 , . . . , a p > 0 is prop ortional to exp p X j =1 log( a j ) x j − p X j =1 log( x j !) . The standard approach to include in teractions is to add terms of the form a ij x i x j . This yields densities prop ortional to exp p X j =1 log( a j ) x j + X i 6 = j a ij x i x j − p X j =1 log( x j !) ! . (5) The dominating terms in this expression are the interaction terms a ij x i x j . Using Stirling’s appro ximation, we find that x 2 / log( x !) → ∞ for x → ∞ , sho wing that the density cannot b e normalized unless a ij ≤ 0 for all i, j. This means that the standard approac h excludes p ositiv e in teractions b etw een the nodes. Let us finally lo ok at the no de conditionals for a sp ecific T . W e c ho ose T ij ( x ) = √ x i x j for simplicit y . The no de conditionals b ecome f M ( x j | x − j ) ∼ e − M j j x j − log( x j !) L Int , where L Int = e − √ x j P k ∈N ( j ) (M j k +M kj ) √ x k . The off-diagonal terms in M model the in teractions of j with the other nodes. If the factors M j k are small, L Int ≈ 1 , and thus, the no de j appro ximately follo ws a Poisson distribution with parameter e − M j j . In particular, if M is diagonal, the no des are indep enden t P oisson distributed random v ariables. 13 In comparison, the standard approach represen ted b y Displa y (5) results in exact P ois- son no de conditionals for any non-p ositive correlations. Con v ersely , it has b een shown in (Chen et al. 2015, Prop osition 1 and Lemma 1) that one can find a distribution with P oisson (or exp onential) no de conditionals only if all interactions are non-p ositiv e. Thus, an unav oidable price for “pure” no de conditionals is a strong, in practice t ypically unrealis- tic assumption on the parameter space. Our framework a v oids this assumption and is still close to the exact P oisson (exp onen tial) distributions if the interactions are small. Exp onen tial The exp onential case is the counterpart of the Poisson case discussed ab ov e. In particular, the standard approac h to correlated exponential data is confron ted with the same integrabilit y issues as ab o v e, while approaches via framew ork (2) easily satisfy the in tegrabilit y conditions. T o mo del exp onential data, w e consider D = [0 , ∞ ) p , q = p, and ξ ≡ 0 . Again a num b er of transformations T would hav e the desired prop erties; ho w ev er, to av oid digression, we only consider the square-ro ot transformations T ij ( x ) = √ x i x j that corresp ond to (Inouye et al. 2016); generalization are p ossible along the same lines as in the Poisson case. W e can no w c hec k the integrabilit y condition (4). Denoting the smallest ` 2 -eigen v alue of M by κ (M) > 0 , w e find e γ (M) = Z ∞ 0 · · · Z ∞ 0 e − P p i,j =1 M ij √ x i x j dx 1 . . . dx p ≤ Z ∞ 0 · · · Z ∞ 0 e − κ (M) | | x | | 1 dx 1 . . . dx p = Z ∞ 0 e − κ (M) x dx p = κ (M) − p < ∞ . Hence, γ (M) < ∞ for all p ositive definite matrices M . In con trast, adding linear in teraction terms to the indep endent joint densit y forbids p ositiv e correlations. One can chec k this similarly as in the P oisson case ab o v e. The node conditionals finally become f M ( x j | x − j ) ∼ e − M j j x j L Int , 14 where L Int = e − √ x j P k ∈N ( j ) (M j k +M kj ) √ x k . The off-diagonal terms in M model the in teractions of j with the other nodes. If the factors M j k are small, L Int ≈ 1 , and thus, no de j approximately follo ws an exp onen tial distribution with parameter M j j . In particular, if M is diagonal, all node conditionals follo w indep enden t exp onen tial distributions. Comp osite Mo dels As an example for comp osite mo dels, let us consider data with P ois- son and exponential elemen ts. Note first that the conditions on the set of matrices M are differen t in the discrete examples and the con tin uous examples: In the discrete examples, w e ha v e shown γ (M) < ∞ for any matrix M . In the con tin uous examples, w e ha v e sho wn γ (M) < ∞ under the additional assumption that M is p ositiv e definite. In the case of com- p osite mo dels, one can in terp olate the conditions. Ho w ever, for the sake of simplicit y , we in- stead assume that the matrices M are p ositive definite. W e then consider p 1 , p 2 ∈ { 1 , 2 , . . . } , p 1 + p 2 = p, D = { 0 , 1 , . . . } p 1 × [0 , ∞ ) p 2 , M ⊂ { M ∈ R p × p : M symmetric, positive definite } , M op en and conv ex, and ξ ( x ) = − P p 1 j =1 log( x j !) . Hence, the first p 1 elemen ts of the ran- dom vector X are discrete, while the other p 2 elemen ts are contin uous. Using again the square-ro ot transformation, the Poisson-t yp e no de conditionals for j ∈ { 1 , . . . , p 1 } are f M ( x j | x − j ) ∼ e − M j j x j − log( x j !) L Int , where L Int = e − √ x j P k ∈N ( j ) (M j k +M kj ) √ x k . The exponential-t yp e no de conditionals for j ∈ { p 1 + 1 , . . . , p 1 + p 2 } ha ve the corresp onding form. The expressions highligh t that the densities can include interactions b etw een the discrete and con tinuous elements of X , while the Poisson/exponential-fla vors of the no des are still preserved. T o show that γ (M) < ∞ , w e proceed similarly as in the examples ab ov e. More precisely , 15 denoting the smallest ` 2 -eigen v alue of M b y κ (M) > 0 , w e find e γ (M) = ∞ X x 1 ,...,x p 1 =0 Z ∞ 0 · · · Z ∞ 0 e − P p i,j =1 M ij √ x i x j Q p 1 j =1 x j ! dx p 1 +1 . . . dx p ≤ ∞ X x 1 ,...,x p 1 =0 Z ∞ 0 · · · Z ∞ 0 e − κ (M) | | x | | 1 Q p 1 j =1 x j ! dx p 1 +1 . . . dx p = ∞ X x 1 ,...,x p 1 =0 e − κ (M) ( x 1 + ··· + x p 1 ) Q p 1 j =1 x j ! × Z ∞ 0 · · · Z ∞ 0 e − κ (M) ( x p 1 +1 + ··· + x p 2 ) dx p 1 +1 . . . dx p = e e − κ (M) p 1 Z ∞ 0 e − κ (M) x dx p 2 < ∞ . Laplace and Bey ond There is muc h ro om for our creativity in constructing mo dels. F or example, we can readily establish mo dels for Laplace (double-exp onential) data b y inserting absolute v alues throughout, for example, T ij ( x ) = p | x i x j | . Indeed, again denoting the smallest ` 2 -eigen v alue of M b y κ (M) > 0 , w e find e γ (M) = Z ∞ −∞ · · · Z ∞ −∞ e − P p i,j =1 M ij √ | x i x j | dx 1 . . . dx p ≤ Z ∞ −∞ · · · Z ∞ −∞ e − κ (M) | | x | | 1 dx 1 . . . dx p = 2 Z ∞ 0 e − κ (M) x dx p = (2 /κ (M)) p < ∞ . Hence, γ (M) < ∞ for all p ositive definite matrices M . In general, the essentially only limit is that to ensure integrabilit y , the interaction terms ha ve to b e of “smaller order” than the terms that corresp ond to the indep enden t case. 3 Estimation W e now turn to estimation based on maxim um lik eliho o d. In Section 3.1, w e sho w that maxim um lik eliho o d estimation has desirable prop erties in our framework. In Section 3.2, w e prop ose a sampling-based approximation algorithm for computing the maximum likeli- ho o d estimator. 16 3.1 Maxim um Lik eliho o d Estimation W e study maximum lik eliho o d estimation in our framework. F or this, we assume we are giv en n i.i.d. data samples X 1 , . . . , X n from a distribution of the form (2). Also, we assume w e are given the mo del sp ecifications D , ν, T , ξ and the parameter space M ; that is, w e assume that the mo del class is known. In con trast, the correct mo del parameters sp ecified in the matrix M are unkno wn. Our goal is to estimate M from the data. As a to y example, consider data on p differen t p opulations of freshw ater fish in n similar lak es. More sp ecifically , consider v ector-v alued observ ations X 1 , . . . , X n ∈ { 0 , 1 , . . . } p , where ( X i ) j is the num b er of fish of t yp e j in lake i . W e w an t to use these data to uncov er the relationships among the differen t populations. A model suited for this task is the P oisson mo del discussed earlier. F or example, w e migh t set D = { 0 , 1 , . . . } p , q = p, { M ∈ R p × p : M symmetric } , T ij ( x ) = √ x i x j , and ξ ( x ) = − P p j =1 log( x i !) . The relationships among the fish p opulations are then enco ded in M , which then needs to b e estimated from the observ ations. Before heading on, w e add some conv enient notation. W e summarize the data in X := ( X 1 , . . . , X n ) and denote the corresp onding function argument by x := ( x 1 , . . . , x n ) for x 1 , . . . , x n ∈ D . The generalized Gram matrix is denoted by T ( x ) := 1 n n X i =1 T ( x i ) . The negative join t log-lik eliho o d function − ` M for n i.i.d random vectors corresp onding to the model (2) is finally given by − ` M ( x ) = n h M , T ( x ) i tr − n X i =1 ξ ( x i ) + nγ (M) . W e can now state the maximum likelihoo d estimator and its prop erties. F or further reference, w e first state the essence of the previous discussion in the following lemma. Lemma 3.1 (Log-lik eliho o d) . Given any M ∈ M ∗ , the ne gative joint lo g-likeliho o d func- tion − ` M of n i.i.d. r andom ve ctors distribute d ac c or ding to f M in (2) c an b e expr esse d by − ` M ( x ) = n h M , T ( x ) i tr + nγ (M) + c , wher e c ∈ R do es not dep end on M . 17 Motiv ated b y Lemma 3.1, we introduce the maxim um likelihoo d estimator of M b y b M := argmin e M ∈ M − ` e M ( X ) = argmin e M ∈ M h e M , T ( X ) i tr + γ ( e M) . (6) The estimator exists in all generic examples. More generally , under our assumption that M ∈ M ⊂ M ∗ and M is op en and con v ex, and the minimizer exists for n sufficien tly large, cf. (Berk 1972). In particular, the ob jective function is conv ex, and its deriv ativ es can b e computed explicitly . Lemma 3.2 (Conv exity) . F or any x ∈ D p , the function M ∗ → R M 7→ h M , T ( x ) i tr + γ (M) is c onvex. Lemma 3.3 (Deriv atives) . F or any x ∈ D p , the function M ∗ → R M 7→ h M , T ( x ) i tr + γ (M) is twic e differ entiable with p artial derivatives ∂ ∂ M ij h M , T ( x ) i tr + γ (M) = T ij ( x ) − E M T ij ( X ) and ∂ ∂ M ij ∂ ∂ M kl h M , T ( x ) i tr + γ (M) = n E M T ij ( X ) − E M T ij ( X ) T kl ( X ) − E M T kl ( X ) for i, j, k , l ∈ { 1 , . . . q } . Con v exity and the explicit deriv ativ es are desirable for b oth optimization and theory . F rom an optimization p ersp ective, the tw o prop erties are v aluable, b ecause they render the ob- jectiv e function amenable to gradien t-t yp e minimization. F rom a theoretical p ersp ectiv e, the t wo prop erties are v aluable, because they imply that M = argmin e M ∈ M E M h e M , T ( X ) i tr + γ ( e M) , 18 sho wing that b M is a standard M-estimator, and b ecause they imply that b M can b e written as a Z-estimator (note that b M is necessarily in the in terior of M ) with criterion T ( X ) = E b M T ( X ) . A simple sp ecial case is the multiv ariate Gaussian mo del. Recall that in this case, M is the in verse of the usual p opulation co v ariance matrix. Moreov er, one can chec k that T ( x ) = 1 n n X i =1 x i x i > and b M = T ( X ) − 1 . Hence, in this case, the estimator b M is the inv erse of the (usual) sample co v ariance matrix. Remark 3.1. The maximum likeliho o d estimator of M is asymptotic al ly normal with c o- varianc e e qual to the inverse Fisher information. In p articular, c onsistency and asymptotic normality of the maximum likeliho o d estimator c an b e pr ove d fol lowing the ar guments in the classic al p ap er (Berk 1972), se e esp e cial ly (Berk 1972, The or ems 4.1 and 6.1). W e r efer to that p ap er for details. 3.2 Algorithm The main c hallenge in computing the maximum likelihoo d estimator is the uncon v en tional normalization term. W e address this c hallenge by approximating the ob jective function using a sampling-based tec hnique. In this section, we describ e the corresp onding algorithm. W e denote the ob jective function of the maxim um likelihoo d estimator in Equation (6) as g ( e M) := h e M , T ( X ) i tr + γ ( e M) . The normalization term γ ( e M) , in general, do es not ha ve a closed-form form ula and, there- fore, mak es the ob jective function hard to compute exactly . Ho w ever, w e sho w in the follo wing that it can b e feasibly approximated. A dding the constan t term γ (M 0 ) , where M 0 is a pre-sp ecified constan t parameter matrix, to the ob jective function of (6) yields an equiv alen t definition of the maxim um likelihoo d estimator as b M = argmin e M ∈ M h e M , T ( X ) i tr + γ ( e M) − γ (M 0 ) . (7) 19 Algebraic transformation reveals γ ( e M) − γ (M 0 ) = log E M 0 e −h e M − M 0 , T ( x ) i tr . The finite exp ectation can b e approximated b y an empirical mean based on some sample set Y from the distribution f M 0 ( x ) := exp( −h M 0 , T ( x ) i tr + ξ ( x ) − γ (M 0 )) . By the strong la w of large n um b ers, when the cardinality of the set Y (denoted as | Y | ) go es to infinity , the empirical mean approximates the exp ectation w ell: log 1 | Y | X Z ∈ Y e −h M − M 0 , T ( Z ) i tr a.s − → log E M 0 e −h M − M 0 , T ( x ) i tr . Hence, in practice, we solv e the approximate problem b M ≈ argmin e M ∈ M e g ( e M) , (8) where e g ( e M) := h e M , T ( X ) i tr + log 1 | Y | X Z ∈ Y e −h e M − M 0 , T ( Z ) i tr . W e apply gradient descent to solve the problem of (8). The gradien t with resp ect to e M is ∇ e g ( e M) = T ( X ) − P Z ∈ Y T ( Z ) e −h e M − M 0 , T ( Z ) i tr P Z ∈ Y e −h e M − M 0 , T ( Z ) i tr . (9) Remark 3.2. The gr adient in (9) c an also b e c onsider e d as an instantiation of self- normalize d imp ortanc e sampling (Owen 2013). L emma 3.3 gives the gr adient of g ( e M) in the form of ∇ g ( e M) = T ( X ) − E e M T ( X ) = T ( X ) − E e M T ( X ) . When E e M T ( X ) lacks an algebr aic expr ession and f e M is inc onvenient to sample fr om, im- p ortanc e sampling (Owen 2013) is useful to appr oximate the exp e ctation term E e M T ( X ) . The ide a of imp ortanc e sampling is to dr aw samples fr om a biase d distribution and obtain the desir e d f e M by adjusting the weights for the dr awn samples. Self-normalize d imp ortanc e sampling r efers to the sp e cial c ase when weights ar e normalize d by their sum. Equation (9) r efle cts the same ide a and uses the pr e-sp e cifie d f M 0 as the biase d sampling distribution. The c hoice of M 0 is essen tial for the finite-sample p erformance of the appro ximation. Our t w o main considerations are: First, the sampling distribution f M 0 should b e straigh t- forw ard for generating samples. Second, it should lead to balanced weigh ts and a small 20 v ariance of b E e M T ( X ) ; if w eights concentrate in just a few samples, we ha v e effectively only got these observ ations, resulting in large v ariability of the approximation (Ow en 2013). T o incorp orate the t wo considerations, w e prop ose M 0 := argmin e M ∈ M h e M , T ( X ) i tr + γ ( e M) sub ject to e M kl = 0 , ∀ k 6 = l. (10) W e restrict the parameter to a diagonal matrix, b y which w e presume mutual indep endence among all co ordinates and disentangle the ob jective function. Hence, b oth the optimiz- ing problem (10) and the task of sampling from f M 0 can b e handled for each co ordinate separately , and each co ordinate reduces to a standard univ ariate exp onential family dis- tribution. Besides, M 0 is the diagonal matrix closest to the actual parameter. When the off-diagonal entries of the actual parameter matrix are small, weigh ts of the drawn samples are expected to b e reasonable. Algorithm 1 summarizes our computational pip eline. In the full version, whic h is stated in App endix B, a backtrac king line searc h selects the step size adaptiv ely and incorp orates the domain constrain t as needed (for example, the p ositiv e definite requirement for the case of con tinuous measures). 4 Sim ulation Studies Exp onen tial trace mo dels apply to a large v ariety of multiv ariate data that ha v e correlated co ordinates. The framew ork is esp ecially useful for data that are discrete, heavy-tailed, or comp osed of different data types. W e consider the following four mo del-types in simula- tions: Poisson, Exp onen tial, Poisson-Bernoulli (a comp osite of P oisson and Bernoulli), and P oisson-Gaussian (a comp osite of P oisson and Gaussian). Such types of models are useful in practice but, to date, ha ve prov en c hallenging to characterize and estimate. 4.1 Settings W e follo w the discussion of Section 2.3 and consider the square-ro ot transformation for non-Gaussian data as one example, that is, we set T ij ( x ) = t i ( x i ) t j ( x j ) , where t i ( x i ) = √ x i for non-Gaussian co ordinates and t i ( x i ) = x i for Gaussian co ordinates. 21 Algorithm 1: Solving for the maximum likelihoo d estimator // η : step size Input : T ( X ) , η > 0 Output: b M // Solve for M 0 1 M 0 ← 0 p × p ; 2 for i = 1 , . . . , p do 3 (M 0 ) ii ← argmin m ∈ R n mT ii ( X ) + log R exp − mT ii ( x ) + ξ ( x i ) dx i o ; // Generate sample set Y from f M 0 = Q p i =1 f (M 0 ) ii ( x i ) 4 for i = 1 , . . . , p do 5 Generate 10,000 random samples from f (M 0 ) ii ( x i ) for the i -th co ordinate; // Apply gradient descent with constant step size to (8) 6 k ← 0 ; 7 e M k ← M 0 ; 8 rep eat 9 k ← k + 1 ; 10 ∇ e g ( e M k − 1 ) ← T ( X ) − P Z ∈ Y T ( Z ) e −h e M k − 1 − M 0 , T ( Z ) i tr P Z ∈ Y e −h e M k − 1 − M 0 , T ( Z ) i tr ; 11 e M k ← e M k − 1 − η ∇ e g ( e M k − 1 ) ; 12 un til e g ( e M k ) − e g ( e M k − 1 ) < 10 − 4 ; 13 b M ← e M k ; 22 In the follo wing, we describ e the sp ecific graph structures for discrete data, contin uous data, and comp osite data of b oth t yp es. The discrete data category also cov ers comp osite data of different discrete t yp es (for example, Poisson-Bernoulli). Discrete Data W e consider Erdős-Rén yi random graphs and generate the corresp onding p × p parameter matrix M in the following manner. Let c 0 and c 1 b e t wo constants ( c 1 6 = 0 ). W e set the diagonal entries to M ii = c 0 . F or i 6 = j , the off-diagonal entries are indep endent and iden tically distributed as M ij = M j i = c 1 with probabilit y 1 /p, − c 1 with probabilit y 1 /p, 0 with probability 1 − 2 /p. (11) The corresp onding Erdős-Rényi random graph has p − 1 edges in exp ectation, among which half represen t p ositive interactions and the other half negative ones. Con tin uous Data W e consider again Erdős-Rényi random graphs. In addition, we generate strictly diagonally dominan t matrices with p ositiv e diagonal en tries for the parameter matrix M . It can b e sho wn that the M ’s are positive definite and satisfy the in tegrability condition. More sp ecifically , w e first generate a p × p adjacency matrix with i.i.d. off-diagonal entries A ij = A j i = 1 with probabilit y 1 /p, − 1 with probabilit y 1 /p, 0 with probabilit y 1 − 2 /p, W e denote the maxim um no de degree b y s := max i P j 6 = i | A ij | . Then, a p ositiv e definite M can be generated b y setting the diagonal en tries to 1 and the off-diagonal en tries to M ij = M j i = 1 / ( s + 0 . 1) A ij . The corresp onding Erdős-Rényi random graph has p − 1 edges in exp ectation, among which half represen t p ositive interactions and the other half negative ones. 23 A Comp osite of Discrete and Con tin uous Data W e consider even v alues of p , with the first p 1 = p/ 2 co ordinates discrete, and the remaining p 2 = p/ 2 co ordinates con tinuous. The parameter matrix in blo c kwise format is M = M 11 M 12 M > 12 M 22 , where M 11 , M 22 represen t the conditional dep endences among p 1 discrete and p 2 con tin uous co ordinates, resp ectively . The remaining blo c k M 12 describ es the conditional dep endences b et w een discrete and contin uous co ordinates. When the contin uous no de conditionals follow a Gaussian distribution, the in tegrabilit y condition is satisfied for all M ∈ R p × p suc h that M 22 is p ositive definite. Therefore, w e generate M 22 in the ab ov e describ ed contin uous case to guarantee its p ositiv e definiteness while generating M 11 and M 12 in the abov e described discrete case. 4.2 Results W e ev aluate the maximum lik eliho o d estimators in terms of edge reco v ery b y studying a v erage ROC (receiv er op erating characteristic) curv es based on thresholding maxim um lik eliho o d estimates. Each av erage R OC curve is tak en ov er 50 individ ual ROC curves that corresp ond to 50 different Erdős-Rén yi random graphs. ROC curves are combined using horizon tal-a veraging via the R pack age ROCR (Sing et al. 2005). Since Gaussian graphical mo dels are curren tly widely used, ev en in cases with obvious missp ecification (eg. coun t data) (Zhao & Duan 2019), w e compare the maxim um likelihoo d estimators of the exponential trace mo del to that of the (missp ecified) Gaussian graphical mo del. The graph structures are describ ed in Section 4.1. Details regarding the data generation approac hes are deferred to Appendix C. W e use n = 250 indep enden t observ ations to reco v er the conditional dep en dence of p = 20 v ariables. The diagonal en try is c 0 = − 1 and the off-diagonal entry is c 1 = 0 . 3 . W e sho w the a verage R OC curv es of P oisson, Exp onen tial, P oisson-Bernoulli, and P oisson-Gaussian in Figures 2 and 4. In addition, w e explore scenarios with diagonal entry c 0 ∈ { 0 , − 0 . 5 , − 1 , − 1 . 5 , − 2 } and off-diagonal entry 24 (a) P oisson A verage f alse positive rate T rue positive r ate 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 ETM GGM (b) Exponential A verage f alse positive rate T rue positive r ate 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 ETM GGM Figure 2: A v erage ROC curves for pure data. ETM stands for the Exp onential trace mo de and GGM stands for Gaussian graphical mo del. c 1 ∈ { 0 . 1 , 0 . 2 , 0 . 3 , 0 . 4 , 0 . 5 } : w e show the differences in A UC of av erage R OC curv es b et ween the exponential trace mo del and the Gaussian graphical mo del in Figures 3 and 5. In the pure data t yp e scenarios: The exp onential trace mo del outp erforms the Gaus- sian graphical mo del substantially—the exp o ential trace mo del’s R OC curves lie en tirely ab o v e the Gaussian graphical mo del’s R OC curves—in the scenario of small interaction and small sufficien t statistics T ( x ) (see Figure 2). In addition, we look into more configurations of P oisson t yp e scenarios by v arying c 0 and c 1 : the p erformance of the sampling-based appro ximation determines that of the exp onential trace mo del (see Figure 3). When the in teraction term and sufficien t statistics are small to mo derate, the exp onen tial trace mo del has a larger A UC than the Gaussian graphical mo del. But when the in teraction term and sufficien t statistics are large, for example, c 0 = − 2 and c 1 = 0 . 5 , the impro v emen t is not guaran teed. F or the comp osite data t yp e scenarios: The exp onential trace mo del shows impro v ed p erformance for Poisson-Bernoulli data but not for Poisson-Gaussian data (see Figures 4 and 5). Bernoulli data hav e very small sufficien t statistics so that the impro v e- 25 ● ● ● ● ● −2.0 −1.5 −1.0 −0.5 0.0 −0.15 −0.05 0.05 0.15 (a) P oisson c 0 ∆ A UC ● c 1 = 0.1 c 1 = 0.2 c 1 = 0.3 c 1 = 0.4 c 1 = 0.5 ● ● ● ● ● 0.1 0.2 0.3 0.4 0.5 −0.15 −0.05 0.05 0.15 (b) P oisson c 1 ∆ A UC ● c 0 = 0 c 0 = −0.5 c 0 = −1 c 0 = −1.5 c 0 = −2 Figure 3: Differences in A UC of a v erage ROC curve b etw een exp onen tial trace mo del and Gaussian graphical mo del for Poisson data. (a) P oisson−Bernoulli A verage f alse positive rate T rue positive r ate 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 ETM GGM (b) P oisson−Gaussian A verage f alse positive rate T rue positive r ate 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 ETM GGM Figure 4: A v erage R OC curves for comp osite data. ETM stands for the Exp onential trace mo de and GGM stands for Gaussian graphical mo del. 26 ● ● ● ● ● −2.0 −1.5 −1.0 −0.5 0.0 −0.2 −0.1 0.0 0.1 0.2 (a) P oisson−Bernoulli c 0 ∆ A UC ● c 1 = 0.1 c 1 = 0.2 c 1 = 0.3 c 1 = 0.4 c 1 = 0.5 ● ● ● ● ● 0.1 0.2 0.3 0.4 0.5 −0.2 −0.1 0.0 0.1 0.2 (b) P oisson−Bernoulli c 1 ∆ A UC ● c 0 = 0 c 0 = −0.5 c 0 = −1 c 0 = −1.5 c 0 = −2 ● ● ● ● ● −2.0 −1.5 −1.0 −0.5 0.0 −0.2 −0.1 0.0 0.1 0.2 (c) P oisson−Gaussian c 0 ∆ A UC ● c 1 = 0.1 c 1 = 0.2 c 1 = 0.3 c 1 = 0.4 c 1 = 0.5 ● ● ● ● ● 0.1 0.2 0.3 0.4 0.5 −0.2 −0.1 0.0 0.1 0.2 (d) P oisson−Gaussian c 1 ∆ A UC ● c 0 = 0 c 0 = −0.5 c 0 = −1 c 0 = −1.5 c 0 = −2 Figure 5: Differences in AUC of a v erage ROC curv es b etw een exp onential trace mo del and Gaussian graphical mo del for comp osite data. 27 men t in P oisson-Bernoulli data is substantial for a large range of interaction terms, but P oisson-Gaussian data inv olves Gaussian co ordinates, so that the p erformance of the exp o- nen tial trace mo del is mixed. The comparative p erformance is not only determined b y the p erformance of the approximation algorithm but also the degree to which the conditional dep endence structure resem bles the zero pattern of the precision matrix. In conclusion, the simulation study shows that: (1) the exp onential trace mo del can impro v e on the Gaussian graphical mo del for non-Gaussian data, esp ecially when the suf- ficien t statistics and small in teractions are small; (2) the appro ximation approac h can struggle when sufficien t statistics and in teractions are large. Based on this, w e b elieve that our mo deling approach has substantial p otential: Some of this p otential is realized b y our current implementation, ho wev er some of the potential might require additional computational insigh ts. 5 Application to Neural Spik e Data In this section, we apply the prop osed exp onen tial trace mo del to neural spik e data. The temp oral and spatial patterns of neural spikes capture the concurren t activity of neurons. Understand this is essential for learning neural circuits. Neural spike data is usually formu- lated as spik e counts in a short time bin and mo deled b y a P oisson distribution (Theis et al. 2016). W e consider a data set of m ulti-electro de arra y recordings of spik e trains in mouse retina (Demas et al. 2003) obtained from the Retinal W av e Rep ository ( Home p age for the R etinal W ave R ep ository 2014). W e transform the spik e time data into spike coun ts in time bins of 40 ms following con v entions in neural science (Theis et al. 2016). The short time in terv al captures the instan taneous characteristics of neuron firing. The recording cov ers an 800 × 800 µm surface area and provides lo cations of each recorded unit in the form of ( x, y ) -co ordinates. The num b er of recorded units ranges from 12 to 22 in differen t mice. The spik e coun ts of each recorded unit range from 0 to 13 and roughly follo w the mean- v ariance relationship of a Poisson distribution. The small counts imply: (1) the exp onen tial trace mo del with square-ro ot transformation is close to the P oisson one; (2) the prop er- ties of the data fit the scenario for which the prop osed algorithm is appropriate. These t w o observ ations render the exp onential trace model with a square-root transformation 28 appropriate. In Figures 6, w e presen t the reco v ered connections of recorded units for a 6-w eek-old wild-t yp e mouse. T o obtain sparse graphs, the maximum likelihoo d estimator is thresholded to 30 edges. In the plotted graphs, the p ositions of the no des corresp ond to to [slightly jittered] ( x, y ) -co ordinates of the neurons in the recording. This allo ws us to consider spatial summaries, eg. the av erage ph ysical length of edges in our graph. The exp onen tial trace mo del finds a more centralized graph than the Gaussian graphical mo del, that is, neurons lo cated together tend to connect in the exp onential trace mo del approac h while the estimated connections in the graph are longer in the Gaussian approach. T o ev aluate this difference quan titatively , w e compute the mean Euclidean distance b etw een all pairs of directly connected neurons. In the 6-w eek-old wild-t yp e mouse, the mean distance is 169 µm (SE: 24 µm ) under the exp onen tial trace mo del and 252 µm (SE: 36 µm ) under the Gaussian graphical mo del. In addition, the exp onential trace mo del recov ers a main connection comp onent and an isolated neuron unit (see Unit 7 in Figure 6). The isolated neuron unit is ph ysically far a w a y from the primary comp onent and ma y b elong to another functional group. In con trast, the Gaussian graphical mo del do es not distinguish the location separation clearly but instead connects almost ev ery units. These c haracteristics found in the exp onential trace mo del but not the Gaussian graph- ical mo del align with our biological understanding. In particular, neurons transmit signals to others through synapses, whic h are ph ysical connections b etw een tw o neurons (Lo dish et al. 2008). This biological mechanism fa v ors direct co ordination of closely lo cated neu- rons. Specifically , previous studies find that the degree tw o units spike together within some small time windo w decays with the distance separating the neurons in retina (Cutts & Eglen 2014, W ong et al. 1993, Xu et al. 2011). 6 Discussion In this pap er w e prop osed an exp onential family-based framew ork to build graphical mo dels. This framework for graphical mo dels allo ws for a wide range of data types as h ighligh ted in Sections 2.2 and 2.3 and y et ensures a rigid theoretical structure as demonstrated in 29 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ETM 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 GGM Figure 6: Retinal connections recov ered for a 6-w eek-old wild-type mouse of the Demas et al. 2003 data. The p ositive interactions are dra wn in red,and the negativ e ones in green. The left panel displa ys the connection reco v ered by the exp onen tial mo del with square-ro ot transformation; the righ t panel displays the connection reco v ered by the Gaussian graphical mo del. Section 3. The mo dels are amenable to estimation based on maximum lik eliho o d, whic h can be computed through a sampling-based approximation tec hnique. A c kno wledgemen ts W e also thank Jon W ellner, Marco Rossini, Mathias Drton, Sam Koelle, Zack Almquist, Ali Sho jaie, Lina Lin for their v aluable input. References Berk, R. H. (1972), ‘Consistency and asymptotic normality of MLE’s for exp onen tial mo d- els’, A nn. Mat. Statist. 43 , 193–204. Besag, J. (1974), ‘Spatial interaction and the statistical analysis of lattice systems’, J. R oy. Statist. So c. Ser. B 36 , 192–236. With discussion b y D. R. Cox, A. G. Hawk es, P . 30 Clifford, P . Whittle, K. Ord, R. Mead, J. M. Hammersley , and M. S. Bartlett and with a reply by the author. Brush, S. G. (1967), ‘History of the Lenz-Ising mo del’, R eviews of mo dern physics 39 (4), 883. Chen, S., Witten, D. M. & Sho jaie, A. (2015), ‘Selection and estimation for mixed graphical mo dels’, Biometrika 102 (1), 47–64. Cutts, C. S. & Eglen, S. J. (2014), ‘Detecting pairwise correlations in spike trains: An ob- jectiv e comparison of metho ds and application to the study of retinal w a ves’, J. Neur osci. 34 (43), 14288–14303. Demas, J., Eglen, S. J. & W ong, R. O. (2003), ‘Developmen tal loss of sync hronous sp on- taneous activity in the mouse retina is indep enden t of visual exp erience’, J. Neur osci. 23 (7), 2851–2860. Diesner, J. & Carley , K. M. (2005), Exploration of communication netw orks from the enron email corpus, in ‘SIAM International Conference on Data Mining: W orkshop on Link Analysis, Coun terterrorism and Securit y , Newp ort Beach, CA’, Citeseer. Drton, M. & Maath uis, M. H. (2016), ‘Structure learning in graphical mo deling’, arXiv:1606.02359 . Eaton, M. L. (2007), ‘Multiv ariate statistics: A v ector space approac h’, IMS L e ctur e Notes Mono gr. Ser. 53 . URL: http://pr oje cteuclid.or g/euclid.lnms/1196285102 F aust, K., Sathirapongsasuti, J. F., Izard, J., Segata, N., Gev ers, D., Rae s, J. & Hut- tenho w er, C. (2012), ‘Microbial co-o ccurrence relationships in the human microbiome’, PLOS Comput. Biol. 8 (7), e1002606. Galla v otti, G. (2013), Statistic al me chanics: A short tr e atise , Springer Science & Business Media. 31 Genest, C. & Nešleho vá, J. (2007), ‘A primer on copulas for coun t data’, Astin Bul l. 37 (2), 475–515. Grimmett, G. R. (1973), ‘A theorem ab out random fields’, Bul l. L ondon Math. So c. 5 , 81– 84. Gu, Q., Cao, Y., Ning, Y. & Liu, H. (2015), ‘Local and global inference for high dimensional nonparanormal graphical mo dels’, arXiv:1502.02347 . Home p age for the R etinal W ave R ep ository (2014), http://www.damtp.cam.ac.uk/user/ eglen/waverepo . Inouy e, D. I., Ra vikumar, P . & Dhillon, I. S. (2016), ‘Square ro ot graphical mo dels: Multi- v ariate generalizations of univ ariate exponential families that p ermit positive dep enden- cies’, Pr o c e e dings of the International Confer enc e on Machine L e arning . Inouy e, D. I., Ra vikumar, P . K. & Dhillon, I. S. (2015), Fixed-length Poisson MRF: adding dep endencies to the multinomial, in ‘NIPS’, pp. 3195–3203. Johansen, S. (1979), Intr o duction to the the ory of r e gular exp onential families , V ol. 3 of L e ctur e Notes , Universit y of Cop enhagen, Institute of Mathematical Statistics, Cop en- hagen. Lauritzen, S. L. (1996), Gr aphic al mo dels , V ol. 17 of Oxfor d Statistic al Scienc e Series , The Clarendon Press, Oxford Universit y Press, New Y ork. Oxford Science Publications. Lenz, W. (1920), ‘Beiträge zum Verständnis der magnetisc hen Eigensc haften in festen Körp ern’, Physikalische Zeitschrift 21 , 613–615. Lin, L., Drton, M. & Sho jaie, A. (2016), ‘Estimation of high-dimensional graphical mo dels using regularized score matching’, Ele ctr on. J. Stat. 10 (1), 806. Liu, H., Han, F., Y uan, M., Lafferty , J. & W asserman, L. (2012), ‘High-dimensional semi- parametric Gaussian copula graphical mo dels’, A nn. Statist. 40 (4), 2293–2326. Liu, H., Lafferty , J. & W asserman, L. (2009), ‘The nonparanormal: semiparametric esti- mation of high dimensional undirected graphs’, J. Mach. L e arn. R es. 10 , 2295–2328. 32 Lo dish, H., Darnell, J. E., Berk, A., Kaiser, C. A., Krieger, M., Scott, M. P ., Bretscher, A., Ploegh, H. & Matsudaira, P . (2008), Mole cular c el l biolo gy , Macmillan. Loh, P .-L. & W ainwrigh t, M. J. (2013), ‘Structure estimation for discrete graphical mo dels: generalized co v ariance matrices and their inv erses’, A nn. Statist. 41 (6), 3022–3049. Mahani, A. S. & Sharabiani, M. T. (2014), ‘Multiv ariate-from-univ ariate MCMC sampler: R P ack age MfUSampler’, arXiv:1412.7784 . Neal, R. M. (2003), ‘Slice sampling’, Ann. Statist. 31 (3), 705–767. Ow en, A. B. (2013), Monte Carlo the ory, metho ds and examples . Shao, J. (2003), Mathematic al statistics , Springer T exts in Statistics, second edn, Springer- V erlag, New Y ork. Sing, T., Sander, O., Beerenwink el, N. & Lengauer, T. (2005), ‘ROCR: visualizing classifier p erformance in R’, Bioinformatics 21 (20), 3940–3941. Theis, L., Berens, P ., F roudarakis, E., Reimer, J., Rosón, M. R., Baden, T., Euler, T., T olias, A. S. & Bethge, M. (2016), ‘Benc hmarking spike rate inference in population calcium imaging’, Neur on 90 (3), 471–482. W ain wrigh t, M. J. & Jordan, M. I. (2008), Gr aphic al mo dels, exp onential families, and variational infer enc e , V ol. 1, No w Publishers Inc. W ong, R. O., Meister, M. & Shatz, C. J. (1993), ‘T ransient p erio d of correlated bursting activit y during developmen t of the mammalian retina’, Neur on 11 (5), 923–938. Xu, H.-p., F urman, M., Mineur, Y. S., Chen, H., King, S. L., Zenisek, D., Zhou, Z. J., Butts, D. A., Tian, N., Picciotto, M. R. & Crair, M. C. (2011), ‘An instructive role for patterned sp on taneous retinal activit y in mouse visual map dev elopmen t’, Neur on 70 (6), 1115–1127. Xue, L. & Zou, H. (2012), ‘Regularized rank-based estimation of high-dimensional non- paranormal graphical mo dels’, Ann. Statist. 40 (5), 2541–2571. 33 Y ang, E., Ra vikumar, P ., Allen, G. I. & Liu, Z. (2015), ‘On graphical mo dels via univ ariate exp onen tial family distributions’, J. Mach. L e arn. R es. 16 , 3813–3847. Y ang, E., Ravikumar, P . K., Allen, G. I. & Liu, Z. (2013), On P oisson graphical mo dels, in ‘NIPS’, pp. 1718–1726. Y u, S., Drton, M. & Sho jaie, A. (2019), ‘Generalized score matching for n on-negativ e data.’, J. Mach. L e arn. R es. 20 (76), 1–70. Zhao, H. & Duan, Z.-H. (2019), ‘Cancer genetic netw ork inference using Gaussian graphical mo dels’, Bioinform. Biol. Insights 13 , 1–9. Zub er, J.-B. & Itzykson, C. (1977), ‘Quantum field theory and the tw o-dimensional Ising mo del’, Physic al R eview D 15 (10), 2875. 34 A Pro ofs A.1 Pro of of Lemma 2.1 Pr o of of L emma 2.1. W e pro ve the t wo prop erties in order. The main proof ideas can also b e found in (Berk 1972, P ages 193-195). Prop ert y 1 W e first sho w that M ∗ is con vex. F or this, consider α ∈ [0 , 1] and M , M 0 ∈ M ∗ . Then, b y definition of the normalization and b y conv exit y of the exp onential function, e γ ( α M+(1 − α )M 0 ) = Z D e −h α M+(1 − α )M 0 , T ( x ) i tr + ξ ( x ) dν ≤ Z D αe −h M , T ( x ) i tr + ξ ( x ) + (1 − α ) e −h M 0 , T ( x ) i tr + ξ ( x ) dν = α e γ (M) + (1 − α ) e γ (M 0 ) < ∞ . Hence, γ ( α M + (1 − α )M 0 ) < ∞ , and thus, α M + (1 − α )M 0 ∈ M ∗ . This concludes the pro of of the first prop erty . Prop ert y 2 W e no w sho w that for an y M ∈ M ∗ , the co ordinates of T ( X ) ha v e moments of all orders with resp ect to f M . T o this end, fix an M ∈ M ∗ . Since M ∗ is op en, there is a neighborho o d M M of 0 q × q suc h that { M − A : A ∈ M M } ⊂ M ∗ . F or any A ∈ M M , the moment generating function of T ( X ) is finite: E M e h A, T ( X ) i tr = Z D e −h M − A, T ( x ) i tr + ξ ( x ) − γ (M) dν = e γ (M − A ) − γ (M) < ∞ . This is a sufficien t condition for the existence of all momen ts of T ( X ) (Shao 2003, P age 33) and th us concludes the proof of the second prop erty . A.2 Pro of of Lemma 3.2 Pr o of of L emma 3.2. The claim follows readily from Lemma 3.3, whic h is prov ed in the next section. Indeed, using the second deriv ates stated in Lemma 3.3, w e find for an y 35 M ∈ M ∗ and M 0 ∈ R q × q , q X i,j,k,l =1 M 0 ij ∂ ∂ M ij ∂ ∂ M kl h M , T ( x ) i tr + γ (M) M 0 kl = n q X i,j,k,l =1 M 0 ij E M T ij ( X ) − E M T ij ( X ) T kl ( X ) − E M T kl ( X ) M 0 kl = n E M h M 0 , T ( X ) − E M T ( X ) i 2 tr . The displa y implies that for any M ∈ M ∗ and M 0 ∈ R q × q , q X i,j,k,l =1 M 0 ij ∂ ∂ M ij ∂ ∂ M kl h M , T ( x ) i tr + γ (M) M 0 kl ≥ 0 . This ensures conv exity , and th us concludes the proof of Lemma 3.2. A.3 Pro of of Lemma 3.3 Pr o of of L emma 3.3. W e prov e the t wo claims in order. P art 1 W e start b y taking the first deriv ativ e, showing that ∇ ij h M , T ( x ) i tr + γ (M) = T ij ( x ) − E M T ij ( X ) , where w e use the shorthand notation ∇ ij := ∂ ∂ M ij . Since the trace is linear, the deriv ative of the first term is ∇ ij h M , T ( x ) i tr = T ij ( x ) . F or the second term, recall that the normalization γ is giv en by γ (M) = log Z D e −h M , T ( x ) i tr + ξ ( x ) dν . T aking exp onen tials on b oth sides, w e find e γ (M) = Z D e −h M , T ( x ) i tr + ξ ( x ) dν . W e can now take deriv atives and get e γ (M) ∇ ij γ (M) = Z D ∇ ij e −h M , T ( x ) i tr + ξ ( x ) dν = − Z D T ij ( x ) e −h M , T ( x ) i tr + ξ ( x ) dν , 36 where we again use the linearity of the trace. Bringing the exp onen tial factor back in to the in tegral and using the assumed indep endence of the observ ations then yields ∇ ij γ (M) = − Z D T ij ( x ) e −h M , T ( x ) i tr + ξ ( x ) − γ (M) dν = − E M T ij ( X ) = − E M T ij ( X ) . This pro vides the deriv ativ e for the second term. Collecting the pieces concludes the pro of of the first part. P art 2 W e now compute the second deriv ative, showing that ∇ ij ∇ kl h M , T ( x ) i tr + γ (M) = E M T ij ( X ) − E M T ij ( X ) T kl ( X ) − E M T kl ( X ) , where w e again use the shorthand notation ∇ ij = ∂ ∂ M ij . T o pro ve this claim, recall that by Part 1, ∇ kl h M , T ( x ) i tr + γ (M) = T kl ( x ) − E M T kl ( X ) . Since the first term is indep enden t of M , w e can fo cus on the second term. Indep endence of the observ ations and the mo del (2) provide E M T kl ( X ) = E M T kl ( X ) = Z D T kl ( x ) e −h M , T ( x ) i tr + ξ ( x ) − γ (M) dν . T aking deriv ativ es, we find similarly as in P art 1 − ∇ ij E M T kl ( X ) = − Z D T kl ( x ) ∇ ij e −h M , T ( x ) i tr + ξ ( x ) − γ (M) dν = − Z D T kl ( x ) ( − T ij ( x ) − ∇ ij γ (M)) e −h M , T ( x ) i tr + ξ ( x ) − γ (M) dν = − Z D T kl ( x ) ( − T ij ( x ) + E M T ij ( X )) e −h M , T ( x ) i tr + ξ ( x ) − γ (M) dν = Z D ( T ij ( x ) − E M T ij ( X )) ( T kl ( x ) − E M T kl ( X )) e −h M , T ( x ) i tr + ξ ( x ) − γ (M) dν = E M T ij ( X ) − E M T ij ( X ) T kl ( X ) − E M T kl ( X ) = n E M T ij ( X ) − E M T ij ( X ) T kl ( X ) − E M T kl ( X ) . Plugging this in ab ov e concludes the pro of of Part 2. 37 B F ull Algorithm for the maxim um lik eliho o d estimator In thi s app endix, we presen t the full algorithm, whic h utilizes a backtrac king line search to adaptively select step sizes and incorp orate the applicable domain constrain t. By con- v en tion, g ( e M) is infinite for e M / ∈ M . The inequality of backtrac king line search implies that e M k − 1 − η ∇ e g ( e M k − 1 ) ∈ M . In a practical implementation, w e multiple η b y β un til e M k − 1 − η ∇ e g ( e M k − 1 ) ∈ M . 38 Algorithm 2: Solving for the maxim um likelihoo d estimator with a bac ktrac king line searc h // η : initial step size // α , β : backtracking parameters Input : T ( X ) , η > 0 , α ∈ (0 , 0 . 5) , β ∈ (0 , 1) Output: b M // Solve for M 0 1 M 0 ← 0 p × p ; 2 for i = 1 , . . . , p do 3 (M 0 ) ii ← argmin m ∈ R n mT ii ( X ) + log R exp − mT ii ( x ) + ξ ( x i ) dx i o ; // Generate sample set Y from f M 0 = Q p i =1 f (M 0 ) ii ( x i ) 4 for i = 1 , . . . , p do 5 Generate 10,000 random samples from f (M 0 ) ii ( x i ) for the i -th co ordinate; // Apply gradient descent with a backtracking line search to (8) 6 k ← 0 ; 7 e M k ← M 0 ; 8 rep eat 9 k ← k + 1 ; 10 ∇ e g ( e M k − 1 ) ← T ( X ) − P Z ∈ Y T ( Z ) e −h e M k − 1 − M 0 , T ( Z ) i tr P Z ∈ Y e −h e M k − 1 − M 0 , T ( Z ) i tr ; // Select the stepsize adaptively using a backtracking line search 11 rep eat 12 η ← β η ; 13 un til e g ( e M k − 1 − η ∇ e g ( e M k − 1 )) ≤ e g ( e M k − 1 ) − αη | |∇ e g ( e M k − 1 ) | | 2 ; 14 e M k ← e M k − 1 − η ∇ e g ( e M k − 1 ) ; 15 un til e g ( e M k ) − e g ( e M k − 1 ) < 10 − 4 ; 16 b M ← e M k ; 39 C Data Generation Here w e describ e ho w to generate samples from an exp onen tial trace mo del in the form of f M ( x ) = e −h M , T ( x ) i tr + ξ ( x ) − γ (M) . Generating data from a multiv ariate distribution directly is difficult for mo derate no de n um b ers. Instead, we consider a Gibbs sampler to sample from the conditional distribution at eac h iteration. Conditioning on all the other v ariables x − j , the density of x j is f M ( x j | x − j ) ∼ e − M j j T j j − 2 P k 6 = j M j k T j k − ξ ( x j ) . W e generate the conditional distribution using a slice sampler Neal (2003) with R pac k age MfUSampler Mahani & Sharabiani (2014). Note the slice sampler was designed for con tin uous v ariables. F or discrete co ordinates, w e uniformly spread the probability in the spik e at an integer c into the interv al b etw een c and c + 1 . This defines a con tinuous density f M ( y j | x − j ) ∼ e − M j j b y j c− 2 P k 6 = j M j k T j k ( b y j c ,x k ) − ξ ( b y j c ) , where b y j c represen ts the largest integer less than y j . W e sample from the ab o v e con tinuous densit y and take b y j c as the realization of a discrete x j . 40
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment