Neural Heterogeneous Scheduler
Access to parallel and distributed computation has enabled researchers and developers to improve algorithms and performance in many applications. Recent research has focused on next generation special purpose systems with multiple kinds of coprocessors, known as heterogeneous system-on-chips (SoC). In this paper, we introduce a method to intelligently schedule–and learn to schedule–a stream of tasks to available processing elements in such a system. We use deep reinforcement learning enabling complex sequential decision making and empirically show that our reinforcement learning system provides for a viable, better alternative to conventional scheduling heuristics with respect to minimizing execution time.
💡 Research Summary
The paper introduces a deep reinforcement‑learning (DRL) based scheduler for heterogeneous system‑on‑chips (SoCs) that contain a mix of CPUs, GPUs, ASICs and other accelerators. Recognizing that traditional heuristic schedulers lack adaptability and struggle with task dependencies, the authors model the scheduling problem as a semi‑Markov decision process (SMDP) where actions correspond to assigning ready tasks to specific processing elements (PEs) and “no‑operation” actions are taken while tasks run. To overcome partial observability, the state representation concatenates binary and multi‑binary vectors encoding the full set of task lists (ready, running, completed, outstanding) together with a resource matrix describing each PE’s performance characteristics.
A policy‑gradient actor‑critic algorithm is employed. The reward is a constant –1 per time step, encouraging the agent to minimize total execution time. Advantage estimates are computed from discounted returns, and the actor loss follows the standard ∇θ J formulation while the critic minimizes the squared advantage error. Exploration uses a temperature‑controlled Softmax that decays over training, effectively transitioning from stochastic to greedy action selection.
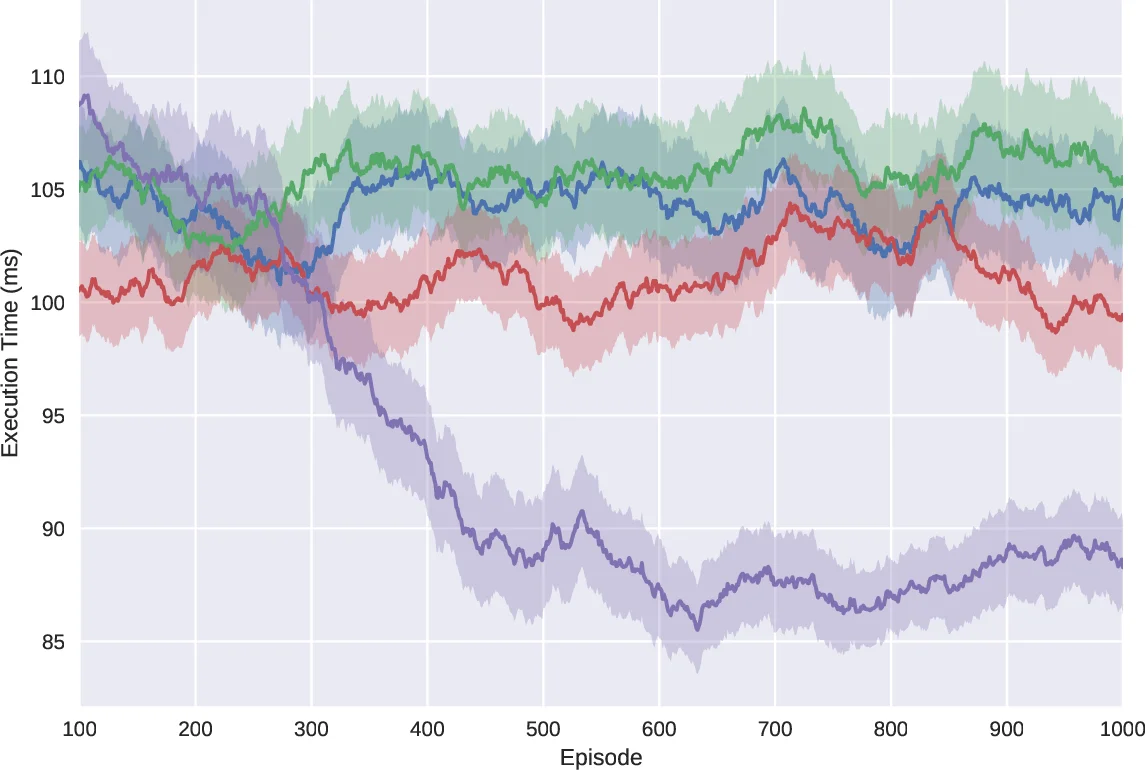
The experimental platform, called DS3, is built on the SimPy discrete‑event library and reads job files (task IDs, dependencies, earliest start times, deadlines) and resource matrix files (execution times per PE). In the reported experiments, a job of ten tasks and three heterogeneous PEs is used under two conditions: a fixed resource matrix and a randomized matrix for each episode. Baselines include three classic heuristics—Earliest Finish Time (EFT), Earliest Time First (ETF), and Minimum Execution Time (MET). With the fixed matrix, MET briefly outperforms the DRL agent because it always picks the fastest PE for the current task, but the DRL policy converges to a comparable 94 ms average after about 720 episodes. With randomized matrices, the DRL scheduler consistently surpasses all heuristics, showing decreasing execution times as training progresses and demonstrating better generalization across varying hardware profiles. Thirty independent runs with different random seeds confirm the robustness of the learned policy.
To provide insight into the learned behavior, the authors apply Grad‑CAM to the policy network, producing saliency maps that highlight which parts of the state vector influence decisions. Gantt‑chart visualizations illustrate how the schedule evolves from an initial high‑latency policy (≈140 ms) to a more efficient one (≈100 ms) after training, including non‑intuitive PE assignments that respect task dependencies.
Compared with prior work such as DeepRM, which handles homogeneous resources and ignores dependencies, this study extends DRL‑based scheduling to realistic heterogeneous environments with complex precedence constraints. Limitations include the exclusive focus on execution time (ignoring energy or power), the lack of pre‑emption (only No‑Op during task execution), and relatively small‑scale experiments. Future directions suggested are multi‑objective reward design, incorporation of pre‑emptive actions, scaling to larger task graphs, and validation on real hardware platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment