LSTM Networks Can Perform Dynamic Counting
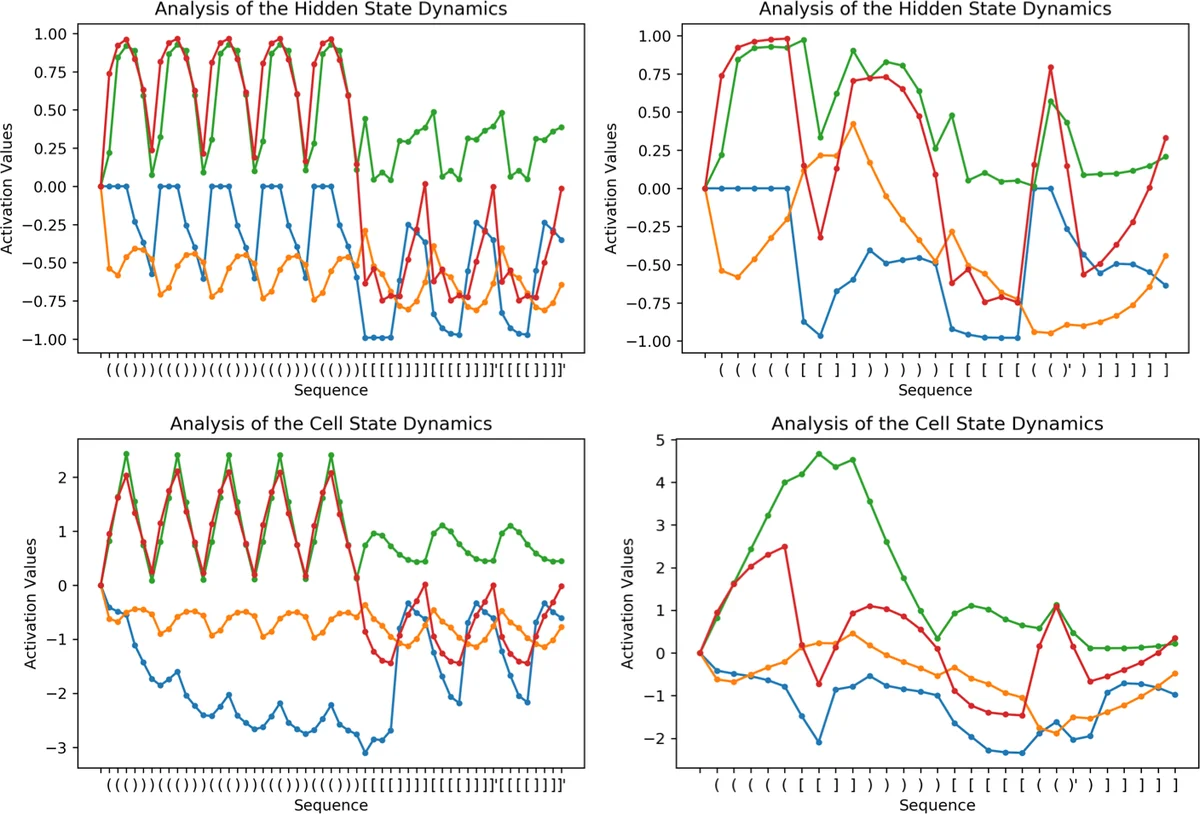
In this paper, we systematically assess the ability of standard recurrent networks to perform dynamic counting and to encode hierarchical representations. All the neural models in our experiments are designed to be small-sized networks both to prevent them from memorizing the training sets and to visualize and interpret their behaviour at test time. Our results demonstrate that the Long Short-Term Memory (LSTM) networks can learn to recognize the well-balanced parenthesis language (Dyck-$1$) and the shuffles of multiple Dyck-$1$ languages, each defined over different parenthesis-pairs, by emulating simple real-time $k$-counter machines. To the best of our knowledge, this work is the first study to introduce the shuffle languages to analyze the computational power of neural networks. We also show that a single-layer LSTM with only one hidden unit is practically sufficient for recognizing the Dyck-$1$ language. However, none of our recurrent networks was able to yield a good performance on the Dyck-$2$ language learning task, which requires a model to have a stack-like mechanism for recognition.
💡 Research Summary
The paper “LSTM Networks Can Perform Dynamic Counting” investigates whether standard recurrent neural networks, particularly Long Short‑Term Memory (LSTM) networks, can learn to perform dynamic counting and thereby recognize hierarchical structures in formal languages. The authors focus on four synthetic languages that differ in the computational mechanisms required for recognition: Dyck‑1 (well‑balanced parentheses with a single counter), Dyck‑2 (well‑balanced parentheses with two types, requiring a stack), Shuffle‑2 (the interleaving of two Dyck‑1 languages over disjoint parentheses), and Shuffle‑6 (the interleaving of six such languages).
To isolate the counting capability, all models are deliberately kept small—single‑layer recurrent networks with fewer than ten hidden units. Specifically, the Dyck‑1 experiments use three hidden units, Shuffle‑2 uses four, Shuffle‑6 uses eight, and a later experiment even shows that a single hidden unit suffices for Dyck‑1. The three model families compared are the classic Elman‑RNN, Gated Recurrent Unit (GRU), and LSTM. Training is framed as a sequence‑prediction task: at each time step the network receives one character (one‑hot encoded) and must output a k‑hot vector representing all characters that could legally follow according to the language’s grammar. A sigmoid output layer with a 0.5 threshold converts the continuous predictions into binary decisions. Accuracy is measured by whether the entire sequence is predicted correctly.
Training data consist of 10,000 Dyck‑1 strings of length 2–50 generated with a balanced probability distribution (p = ½ for opening, q = ¼ for closing). Two test sets are created: a “short” set of 5,000 strings drawn from the same length range but distinct from training, and a “long” set of 5,000 strings of length 52–100, ensuring no overlap with training data. The same procedure is applied to the shuffle languages, with the appropriate alphabet extensions, while Dyck‑2 strings are generated using two types of parentheses.
Results show a striking contrast. LSTMs achieve perfect (100 %) accuracy on both short and long Dyck‑1 test sets, even when limited to a single hidden unit. For Shuffle‑2 and Shuffle‑6, LSTMs maintain near‑perfect performance (≥ 99 % on short sets and ≥ 98 % on long sets), demonstrating that they can emulate deterministic k‑counter automata that perform an arbitrary number of turns. GRUs perform well on Dyck‑1 and Shuffle‑2 but degrade noticeably on Shuffle‑6, especially on longer sequences. Simple Elman‑RNNs struggle with all tasks beyond very short sequences, confirming that vanilla recurrent dynamics lack the robustness needed for dynamic counting.
In stark contrast, all three model families fail to learn Dyck‑2. Even the best LSTM reaches only about 31 % accuracy on the long test set, indicating that the gating mechanisms alone do not provide a stack‑like memory required for context‑free languages with nested dependencies. This aligns with theoretical expectations: Dyck‑2 cannot be recognized by a finite‑state controller equipped only with counters; a push‑down stack is essential.
The paper contributes several novel insights. First, it empirically validates the theoretical claim (Weiss et al., 2018) that LSTMs can simulate real‑time k‑counter machines, extending the evidence from simple one‑turn languages (aⁿbⁿ, aⁿbⁿcⁿ) to languages that require multiple independent counters and unrestricted turn counts. Second, by introducing shuffle languages, the authors create a benchmark that explicitly tests the ability to maintain several counters simultaneously, a scenario not previously explored in the literature. Third, the systematic use of extremely small networks demonstrates that the observed counting behavior is not a by‑product of over‑parameterization but an intrinsic property of the LSTM architecture.
The authors conclude that while LSTMs are surprisingly powerful for counting‑based languages, they remain insufficient for languages that demand a true stack. Future work should therefore explore augmentations such as differentiable stacks, queues, or external memory (e.g., Neural Turing Machines) to endow recurrent models with genuine push‑down capabilities. Such extensions could bridge the gap between the counting mechanisms demonstrated here and the hierarchical parsing required for natural language processing tasks involving deep nesting and long‑range dependencies.
Comments & Academic Discussion
Loading comments...
Leave a Comment