Singing voice separation: a study on training data
In the recent years, singing voice separation systems showed increased performance due to the use of supervised training. The design of training datasets is known as a crucial factor in the performance of such systems. We investigate on how the characteristics of the training dataset impacts the separation performances of state-of-the-art singing voice separation algorithms. We show that the separation quality and diversity are two important and complementary assets of a good training dataset. We also provide insights on possible transforms to perform data augmentation for this task.
💡 Research Summary
This paper investigates how the characteristics of training data influence the performance of state‑of‑the‑art singing‑voice separation systems. The authors focus on a single, well‑known deep learning architecture—a U‑Net originally proposed for music source separation—and train it on several distinct datasets while keeping all other variables (network hyper‑parameters, preprocessing, post‑processing) constant. The goal is to isolate the effect of the training data itself.
Three training corpora are used. (1) MUSDB, a public benchmark consisting of 150 professionally mixed songs (≈10 h) with high‑quality isolated stems for vocals, drums, bass and “other”. (2) Bean, a large private collection of 24 097 songs (≈95 h) also providing clean, professionally produced stems; the split is artist‑wise so that no artist appears in both training and validation/test sets. (3) Catalog, built from Deezer’s streaming catalog by pairing original mixes with released instrumental versions. From each pair a vocal estimate is obtained by half‑wave rectified subtraction of magnitude spectrograms, yielding 28 810 triplets (≈79 h). Two versions are created: Catalog A (raw) and Catalog B (re‑balanced in genre to match Bean). Catalog therefore represents weakly labeled data: the instrumental tracks are reliable, but the vocal tracks contain residual instrumental leakage and occasional mis‑matches.
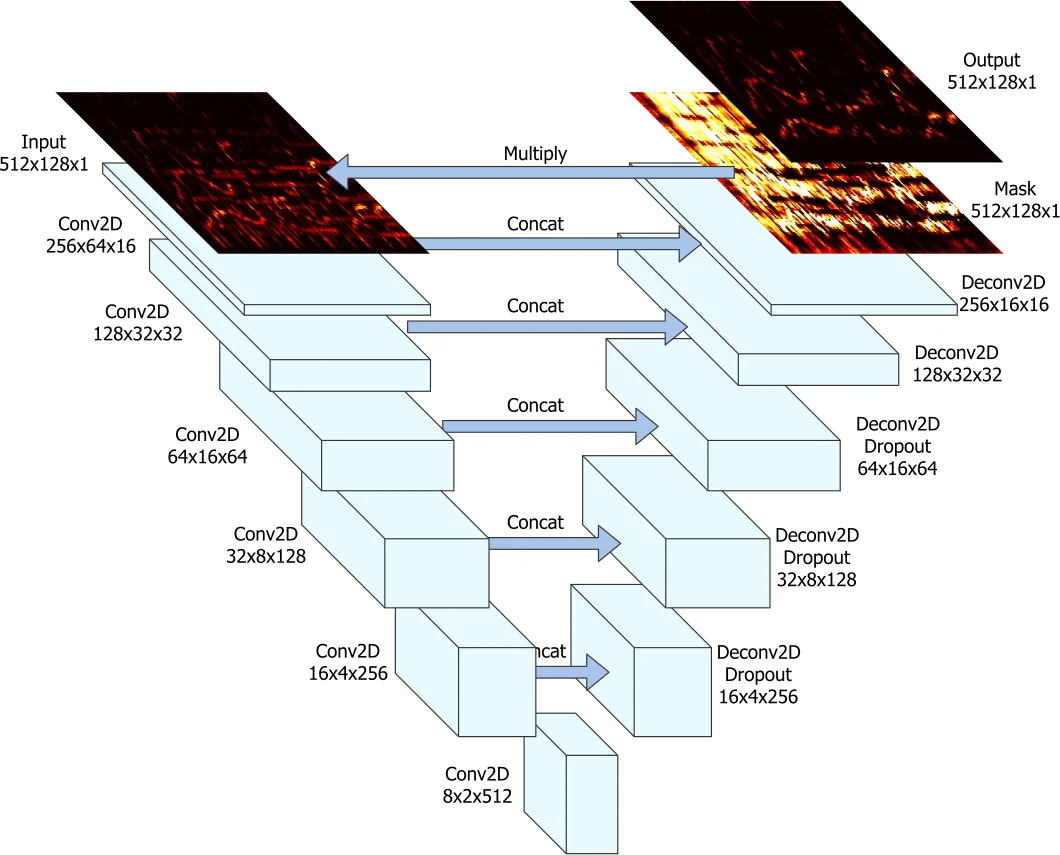
All audio is down‑sampled to 22 050 Hz, segmented into 11.88‑second excerpts, and transformed to magnitude spectrograms (2048‑point FFT, hop 512). The U‑Net processes stereo input as a 3‑D tensor (channels × time × frequency) and is trained separately for vocal and instrumental masks using an L1 loss on the masked magnitude. Training runs for 500 epochs (800 gradient steps per epoch) with Adam (lr = 1e‑4), batch size 1, and early stopping on the validation split. At inference, ratio masks are computed from the two network outputs and applied to the original mixture spectrogram; the mixture phase is reused for reconstruction.
Four experimental axes are explored:
-
Dataset size, quality, and diversity – The same U‑Net is trained on MUSDB, Bean, Catalog A, and Catalog B. Evaluation on both the MUSDB test set and a held‑out Bean test set (1 900 segments) uses the standard BSS_EVAL metrics (SDR, SIR, SAR). Bean consistently yields the highest SDR (≈6.8 dB) and SIR, confirming that a large amount of clean, diverse, high‑quality stems leads to better generalisation. Catalog A, despite its larger volume, underperforms by about 0.9 dB SDR because the vocal estimates are noisy. Re‑balancing genres in Catalog B improves results modestly but does not close the gap, indicating that label quality dominates over sheer quantity.
-
Data augmentation – On the small MUSDB corpus, six spectrogram‑level augmentations are applied: channel swapping, time stretching (±30 % stretch), pitch shifting (±30 % shift), remixing (random vocal/instrument loudness scaling between –9 dB and +9 dB), Gaussian filtering, and overall loudness scaling (±10 dB). A combined augmentation applies the first four simultaneously. Paired Student’s t‑tests on SDR show that channel swapping, pitch shifting, and time stretching produce statistically significant improvements (p < 0.05) but the absolute gain is modest (≤0.3 dB). Other transforms (filtering, loudness scaling, remixing) do not yield consistent benefits. The authors conclude that spectrogram‑level augmentations, while easy to implement, have limited impact for source separation where phase and non‑linear interactions matter.
-
Use of multiple instrument stems – Instead of collapsing drums, bass and “other” into a single instrumental target, the authors train separate networks for each non‑vocal stem and sum their outputs to obtain the instrumental estimate. This multi‑stem approach reduces drum leakage into the vocal estimate, improving SIR by roughly 1 dB and SDR by 0.1–0.2 dB. The gain is small but demonstrates that providing the model with richer supervision on the accompaniment can help it learn a more accurate instrumental representation.
-
Artist‑wise split – All datasets are split so that no artist appears in both training and validation/test sets. This precaution prevents the network from memorising timbral characteristics of specific singers, a known source of over‑optimistic results in music information retrieval. The strong performance of Bean despite this strict split underscores the benefit of diverse artist representation.
Overall, the paper delivers several key insights: (i) Quality and diversity trump sheer quantity – a large, clean, genre‑balanced dataset yields the best separation; weakly labeled large corpora are useful but cannot replace high‑quality stems. (ii) Standard spectrogram augmentations provide only marginal gains, suggesting that future work should explore audio‑domain augmentations (e.g., high‑quality pitch‑shifting, time‑domain convolution with realistic room impulse responses, or synthetic vocal generation). (iii) Multi‑stem supervision can modestly improve instrumental modeling, especially for percussive leakage. (iv) Artist‑wise partitioning is essential for reliable evaluation.
The authors recommend that the community invest in building larger, professionally mixed multi‑track repositories (or improving the quality of weakly labeled data via better source‑estimation pipelines) and develop augmentation techniques that respect the physics of audio mixing. Such steps are likely to push singing‑voice separation performance beyond the current plateau where models already approach oracle instrumental quality but still lag on vocal fidelity.
Comments & Academic Discussion
Loading comments...
Leave a Comment