AssemblyNet: A Novel Deep Decision-Making Process for Whole Brain MRI Segmentation
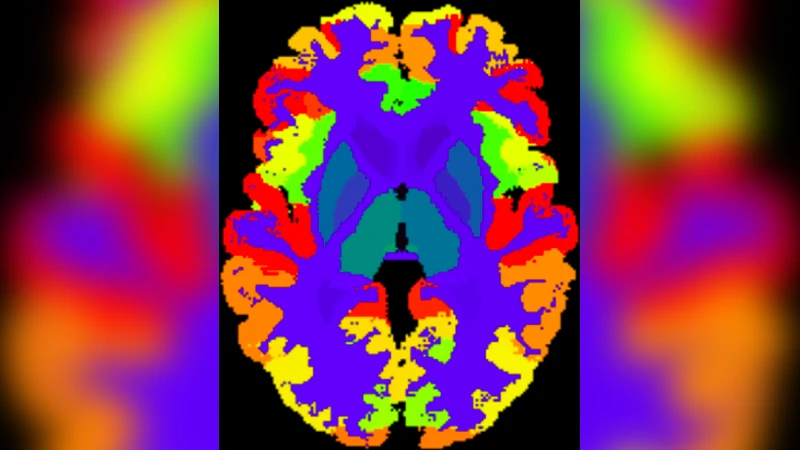
Whole brain segmentation using deep learning (DL) is a very challenging task since the number of anatomical labels is very high compared to the number of available training images. To address this problem, previous DL methods proposed to use a global convolution neural network (CNN) or few independent CNNs. In this paper, we present a novel ensemble method based on a large number of CNNs processing different overlapping brain areas. Inspired by parliamentary decision-making systems, we propose a framework called AssemblyNet, made of two “assemblies” of U-Nets. Such a parliamentary system is capable of dealing with complex decisions and reaching a consensus quickly. AssemblyNet introduces sharing of knowledge among neighboring U-Nets, an “amendment” procedure made by the second assembly at higher-resolution to refine the decision taken by the first one, and a final decision obtained by majority voting. When using the same 45 training images, AssemblyNet outperforms global U-Net by 28% in terms of the Dice metric, patch-based joint label fusion by 15% and SLANT-27 by 10%. Finally, AssemblyNet demonstrates high capacity to deal with limited training data to achieve whole brain segmentation in practical training and testing times.
💡 Research Summary
This paper tackles the notoriously difficult problem of whole‑brain MRI segmentation, where the number of anatomical labels (132) far exceeds the number of available manually annotated training scans. While previous deep learning approaches have relied on a single global 3D U‑Net, patch‑wise networks, or the SLANT framework that splits the brain into a modest number of overlapping sub‑volumes (e.g., 8 or 27), these methods either struggle with limited data or require extensive computational resources.
AssemblyNet introduces a novel “parliamentary” decision‑making architecture composed of two separate assemblies of U‑Nets, analogous to a bicameral legislature. The first assembly operates at a coarse resolution of 2 mm³, consisting of 125 U‑Nets arranged in a 5 × 5 × 5 grid that each process an overlapping sub‑volume (≥50 % overlap). To promote knowledge sharing, a nearest‑neighbor transfer learning scheme is employed: the descending‑path weights of a U‑Net are used to initialise its spatial neighbour, effectively propagating learned features across adjacent brain regions without increasing the total number of parameters dramatically.
The second assembly works at a fine resolution of 1 mm³, also with 125 U‑Nets. The coarse segmentation produced by the first assembly is up‑sampled using nearest‑neighbour interpolation and combined with a non‑linearly registered multi‑atlas prior (derived from the MICCAI 2012 Multi‑Atlas Labelling Challenge). This “amendment” stage refines the coarse decision, analogous to a legislative revision process. Finally, a majority‑vote across all U‑Nets in both assemblies yields the final label for each voxel.
Pre‑processing follows a standard pipeline: denoising, bias field correction, affine registration to MNI space, intensity normalisation, and brain extraction. Atlas priors are generated by deformable registration of the multi‑atlas to each subject. Training uses 45 T1‑weighted OASIS scans with BrainCOLOR labels, augmented with flips and MixUp, and employs a lightweight U‑Net (24 filters per layer) to reduce GPU memory usage by ~25 %. Each network is trained for 100 epochs plus an additional 20 epochs of weight averaging; dropout is applied at test time and three stochastic outputs per network are averaged to reduce variance.
Experimental results demonstrate that AssemblyNet, using only the 45 training images, achieves a mean Dice coefficient of 73.3 % on 19 test scans (132 labels). This outperforms a global U‑Net (57.0 % Dice, +28 %), SLANT‑8 (57.0 %, +28 %), SLANT‑27 (66.1 %, +10 %), and the classic patch‑based Joint Label Fusion (63.4 %). The coarse‑only assembly (2 mm) already reaches 67.9 % Dice; adding the multiscale cascade improves performance by 1.6 % absolute Dice. Training time is about 7 days and inference takes roughly 10 minutes per scan, comparable to SLANT‑27 but without the massive library extension (which would require 21 CPU‑years for 5 111 auxiliary scans).
Performance is further analysed across three test cohorts: adult OASIS scans, pediatric CANDI scans, and the high‑resolution Colin27 scan. AssemblyNet consistently yields the highest Dice scores (78.8 % on OASIS, 71.1 % on CANDI, 74.2 % on Colin27), demonstrating robustness to different acquisition protocols and age groups. Notably, while other methods suffer a dramatic drop on the pediatric data, AssemblyNet maintains strong performance, highlighting the benefit of knowledge sharing and atlas priors in handling distribution shifts.
In conclusion, AssemblyNet presents a compelling new paradigm for whole‑brain segmentation: a parliamentary‑style deep ensemble that leverages nearest‑neighbor weight transfer, atlas priors, and a multiscale refinement process. It achieves state‑of‑the‑art accuracy with limited training data and practical computational demands. Future work may explore optimal assembly sizes, integration of additional priors (e.g., functional connectivity), and scalable cloud‑based training to further enhance performance and applicability.
Comments & Academic Discussion
Loading comments...
Leave a Comment