Characterizing Audio Adversarial Examples Using Temporal Dependency
Recent studies have highlighted adversarial examples as a ubiquitous threat to different neural network models and many downstream applications. Nonetheless, as unique data properties have inspired distinct and powerful learning principles, this paper aims to explore their potentials towards mitigating adversarial inputs. In particular, our results reveal the importance of using the temporal dependency in audio data to gain discriminate power against adversarial examples. Tested on the automatic speech recognition (ASR) tasks and three recent audio adversarial attacks, we find that (i) input transformation developed from image adversarial defense provides limited robustness improvement and is subtle to advanced attacks; (ii) temporal dependency can be exploited to gain discriminative power against audio adversarial examples and is resistant to adaptive attacks considered in our experiments. Our results not only show promising means of improving the robustness of ASR systems, but also offer novel insights in exploiting domain-specific data properties to mitigate negative effects of adversarial examples.
💡 Research Summary
The paper investigates defenses against adversarial examples targeting automatic speech recognition (ASR) systems, focusing on whether techniques successful in the image domain can be transferred to audio and whether the intrinsic temporal dependency of audio signals can be leveraged for robust detection.
First, the authors evaluate four straightforward input‑transformation defenses adapted from image research: waveform quantization (rounding amplitudes to multiples of q = 128, 256, 512, 1024), local smoothing with a sliding window (average or median), down‑sampling from 16 kHz to 8 kHz followed by reconstruction, and a sequence‑to‑sequence auto‑encoder that processes audio in short frames. These transformations are cheap to implement and have previously shown modest success against image‑based attacks. However, when applied to three state‑of‑the‑art audio attacks—(i) a genetic‑algorithm attack on speech‑command classification (Alzantot et al., 2018), (ii) the Carlini‑Wagner optimization attack on speech‑to‑text (Carlini & Wagner, 2018), and (iii) the “Commander Song” attack that embeds adversarial commands into music (Yuan et al., 2018)—the defenses provide only negligible robustness. Moreover, the authors demonstrate that an adaptive attacker, aware of the transformation pipeline and employing the gradient‑obfuscation‑bypassing method of Athalye et al. (2018), can easily circumvent these defenses. In many cases, the transformations even degrade the word error rate (WER) and character error rate (CER) on clean audio, indicating that naïve image‑style preprocessing is insufficient for audio.
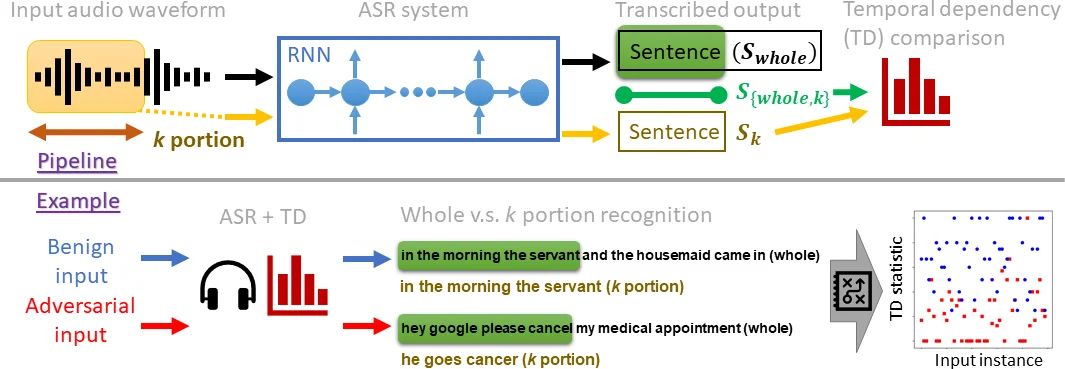
The core contribution is a detection method that exploits temporal dependency (TD). The idea is simple: given an audio clip, feed the first k seconds (or samples) to the ASR model and obtain a transcription Sₖ. Then feed the entire clip, obtain the full transcription, and extract its first k seconds to produce S_{whole,k}. For a benign utterance, because modern ASR models (e.g., DeepSpeech) rely heavily on sequential context, Sₖ and S_{whole,k} should be nearly identical; their WER will be low. For an adversarial example, the perturbation is crafted to force a specific target transcription when the whole signal is processed, but it does not preserve the local temporal structure needed for the short prefix. Consequently, Sₖ and S_{whole,k} diverge, yielding a high WER. By setting a threshold on this WER distance, the system flags inputs as adversarial or clean.
The authors evaluate TD on two large speech corpora (LibriSpeech and Mozilla Common Voice) and the Speech Commands dataset, using DeepSpeech for speech‑to‑text, a CNN‑based command classifier, and the Kaldi platform for the Commander Song attack. Across all three attacks, TD achieves detection accuracies above 95 % for non‑adaptive attacks. Crucially, the authors also construct strong adaptive attacks that know the exact TD procedure (including the value of k and the threshold) and attempt to minimize the TD‑based distance while still achieving the target transcription. Even under these conditions, TD maintains detection rates around 90 %, demonstrating substantial resilience.
The paper discusses practical considerations: the choice of k influences the trade‑off between detection reliability and computational cost; very short prefixes may lack sufficient linguistic context, leading to false positives, while very long prefixes increase processing time. The method does not require any modification to the underlying ASR model, nor does it rely on adversarial training or data augmentation, making it attractive for deployment. Limitations include potential vulnerability to attacks that specifically preserve local temporal patterns while altering global structure, and reduced effectiveness on non‑speech audio (e.g., music) where the notion of “prefix consistency” is less meaningful.
In conclusion, the study shows that (1) input‑transformation defenses from the image domain do not transfer well to audio, especially against adaptive attackers, and (2) leveraging domain‑specific properties—here, the temporal dependency of speech—provides a powerful, model‑agnostic defense that can detect a wide range of adversarial attacks, including those crafted with full knowledge of the defense. The authors suggest future work on multi‑scale prefix analysis, dynamic threshold learning, and extending the temporal‑dependency concept to multimodal data such as video (spatial + temporal) or audio‑visual streams.
Comments & Academic Discussion
Loading comments...
Leave a Comment