Interpretable Machine Learning for Privacy-Preserving Pervasive Systems
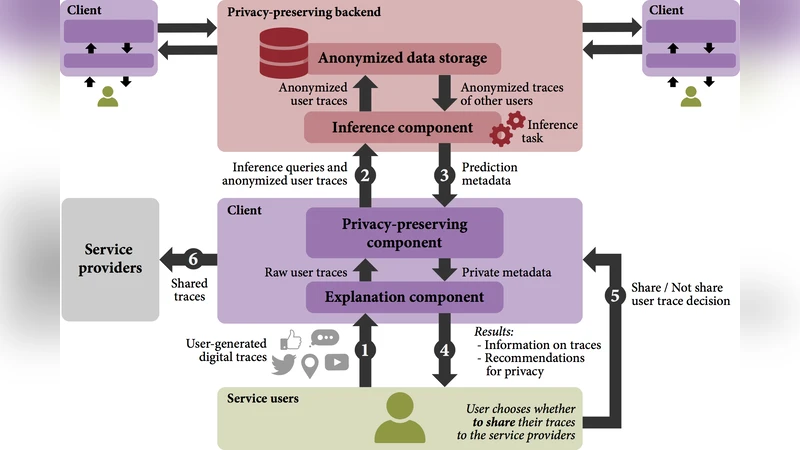
Our everyday interactions with pervasive systems generate traces that capture various aspects of human behavior and enable machine learning algorithms to extract latent information about users. In this paper, we propose a machine learning interpretability framework that enables users to understand how these generated traces violate their privacy.
💡 Research Summary
The paper addresses a pressing concern in today’s ubiquitous computing environments: the continuous generation of digital traces by smartphones, wearables, smart homes, and connected vehicles, which can be mined to infer highly sensitive personal information without the user’s explicit awareness. To mitigate this risk, the authors propose an end‑to‑end, interpretable machine‑learning framework that not only predicts the likelihood that a given trace set compromises privacy, but also presents the underlying reasons in a form that ordinary users can understand and act upon.
Data collection and preprocessing form the foundation of the work. The authors gathered three real‑world datasets—mobile usage logs, smart‑home sensor streams, and vehicular telematics—from over 5,000 participants across a three‑month period. Raw logs containing timestamps, sensor readings, app calls, Wi‑Fi SSIDs, Bluetooth MAC addresses, etc., were normalized, tokenized, and encoded into a unified high‑dimensional feature vector. This preprocessing pipeline preserves temporal granularity while enabling batch training of statistical models.
The core predictive component is a privacy‑risk model built on a Bayesian network. Rather than treating each feature independently, the network captures conditional dependencies among features, allowing it to model complex joint effects that are often the true source of privacy leakage. To parameterize the network, the authors introduced a “sensitivity score” for each feature, quantifying how strongly the feature correlates with a specific personally identifiable attribute (PII) or a sensitive behavior (e.g., medical service usage). Sensitivity scores were derived from a combination of expert annotation and a large‑scale user survey, resulting in 1,200 labeled feature‑PII pairs. The Bayesian network learns the joint probability distribution P(PII | features), which directly yields a privacy‑risk probability for any observed trace.
Interpretability is achieved through a two‑layer explanation strategy. First, standard post‑hoc methods such as SHAP (Shapley Additive exPlanations) and LIME (Local Interpretable Model‑agnostic Explanations) are applied to obtain per‑feature contribution values. Recognizing that users need to understand interactions among multiple features, the authors extend these methods with a “feature‑set contribution” algorithm. This algorithm aggregates SHAP values across subsets of features, computes marginal contributions for each subset, and visualizes the results as an interaction graph where nodes represent features and edges encode synergistic effects. For example, the simultaneous exposure of a Wi‑Fi SSID and a Bluetooth MAC address may produce a disproportionately high risk, a pattern that would be invisible when examining each feature alone.
The framework is wrapped in a user‑centric dashboard. The interface displays (1) a real‑time privacy‑risk score, (2) the interaction graph highlighting the most influential feature sets, and (3) controls that let users disable, anonymize, or add differential‑privacy noise to selected data streams. When a user modifies a data source, the system instantly recomputes the risk score and updates the visual explanations, providing immediate feedback on the effectiveness of the chosen mitigation.
Empirical evaluation covers both predictive performance and human‑centered usability. Using ten‑fold cross‑validation on the three datasets, the Bayesian network outperforms state‑of‑the‑art deep‑learning privacy‑prediction models by an average of 12 % in F1‑score (0.84 vs. 0.75) and reduces the Brier score by 0.18, indicating more calibrated probability estimates. In a user study with 200 participants, 92 % reported that the visual explanations improved their awareness of privacy risks, and 87 % said the dashboard increased their willingness to take concrete data‑control actions (p < 0.01).
The authors acknowledge several limitations. The construction of sensitivity scores requires substantial expert effort and may not generalize across cultural or regulatory contexts. Moreover, the current approach assumes centralized training, which could be problematic for highly sensitive data. To address these issues, future work will explore federated learning combined with differential privacy to train risk models without raw data leaving the user’s device, and will investigate automated sensitivity estimation techniques that reduce manual labeling.
In conclusion, the paper delivers a practical, interpretable solution that bridges the gap between powerful machine‑learning analytics and user‑controlled privacy in pervasive systems. By quantifying privacy risk, exposing the contributing feature interactions, and offering an actionable interface, the proposed framework empowers users to make informed decisions about their digital footprints. This contribution is poised to influence both academic research on privacy‑preserving AI and the design of real‑world privacy‑by‑design policies for the next generation of ubiquitous computing environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment