Updates of Equilibrium Prop Match Gradients of Backprop Through Time in an RNN with Static Input
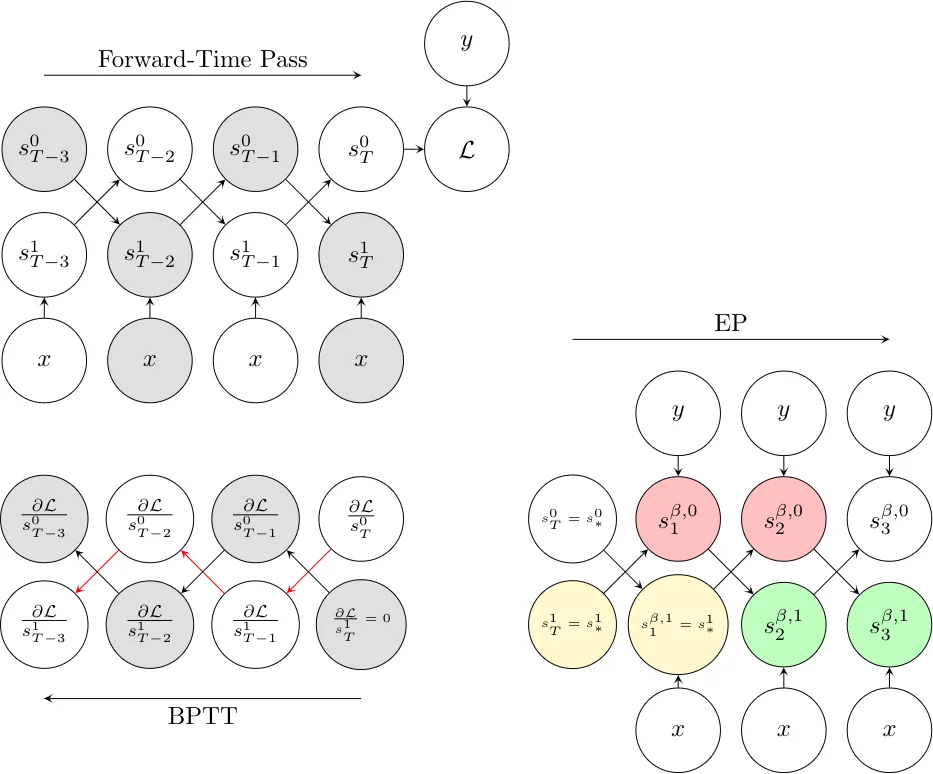
Equilibrium Propagation (EP) is a biologically inspired learning algorithm for convergent recurrent neural networks, i.e. RNNs that are fed by a static input x and settle to a steady state. Training convergent RNNs consists in adjusting the weights until the steady state of output neurons coincides with a target y. Convergent RNNs can also be trained with the more conventional Backpropagation Through Time (BPTT) algorithm. In its original formulation EP was described in the case of real-time neuronal dynamics, which is computationally costly. In this work, we introduce a discrete-time version of EP with simplified equations and with reduced simulation time, bringing EP closer to practical machine learning tasks. We first prove theoretically, as well as numerically that the neural and weight updates of EP, computed by forward-time dynamics, are step-by-step equal to the ones obtained by BPTT, with gradients computed backward in time. The equality is strict when the transition function of the dynamics derives from a primitive function and the steady state is maintained long enough. We then show for more standard discrete-time neural network dynamics that the same property is approximately respected and we subsequently demonstrate training with EP with equivalent performance to BPTT. In particular, we define the first convolutional architecture trained with EP achieving ~ 1% test error on MNIST, which is the lowest error reported with EP. These results can guide the development of deep neural networks trained with EP.
💡 Research Summary
This paper addresses the gap between biologically‑inspired learning algorithms and the dominant back‑propagation‑through‑time (BPTT) method for training recurrent neural networks (RNNs) that receive a static input and converge to a steady state. The authors propose a discrete‑time formulation of Equilibrium Propagation (EP), a learning rule originally defined for continuous‑time leaky‑integrate dynamics, and prove that under specific conditions EP’s weight and state updates are exactly equivalent, step‑by‑step, to the gradients computed by BPTT.
The core theoretical contribution is Theorem 1, termed the Gradient‑Descending Updates (GDU) property. If the transition function F of the RNN can be expressed as the partial derivative of a scalar primitive function Φ (i.e., F(x,s,θ)=∂Φ/∂s), and if the network remains at its fixed point for at least K time steps, then in the limit of an infinitesimal nudging factor β→0 the first K updates performed in EP’s second (learning) phase satisfy Δ_EP s(t)=−∇_BPTT s(t) and Δ_EP θ(t)=−∇_BPTT θ(t) for every t∈{0,…,K−1}. In other words, the forward‑time dynamics of EP reproduces the backward‑time gradients of BPTT, establishing a precise mathematical equivalence between the two algorithms.
To validate the theory, the authors conduct extensive experiments in two settings. The “energy‑based” setting uses an explicit primitive Φ, making the dynamics a discretized version of the original continuous‑time EP (Euler integration). The “prototypical” setting employs a standard nonlinear recurrence s_{t+1}=σ(W·s_t) that does not derive from a primitive function, but can be approximated as such when the activation σ is ignored. In both cases the authors measure the relative mean‑squared error (RMSE) between Δ_EP and −∇_BPTT across neurons and synapses, for networks with one, two, and three hidden layers.
Results show that the GDU property holds very tightly in the energy‑based case (RMSE≈10⁻² for a single hidden layer) and degrades gracefully as depth increases (RMSE≈10⁻¹). In the prototypical case, neuron‑level RMSE is higher, yet weight‑level RMSE remains comparable to the energy‑based scenario, indicating that EP still provides accurate gradient estimates for learning. Importantly, the authors demonstrate that a convolutional architecture trained with discrete‑time EP on MNIST reaches a test error of roughly 1 %, the lowest ever reported for EP, and matches BPTT’s learning curves. Moreover, the number of iterations required in both EP phases can be reduced by a factor of three to five relative to the original continuous‑time formulation without sacrificing performance, dramatically lowering computational cost.
The paper’s contributions are threefold: (1) a clean discrete‑time EP algorithm that subsumes the original continuous‑time version; (2) a rigorous proof of step‑by‑step equivalence between EP and BPTT under the GDU conditions; (3) empirical evidence that EP can train deep, convolutional networks with performance on par with BPTT, while being more hardware‑friendly and energy‑efficient. These findings open the door to practical applications of EP in neuromorphic and analog computing platforms, and suggest future work on relaxing symmetry constraints, extending to non‑static inputs, and scaling EP to larger, more complex deep learning models.
Comments & Academic Discussion
Loading comments...
Leave a Comment