Dynamic Traffic Scene Classification with Space-Time Coherence
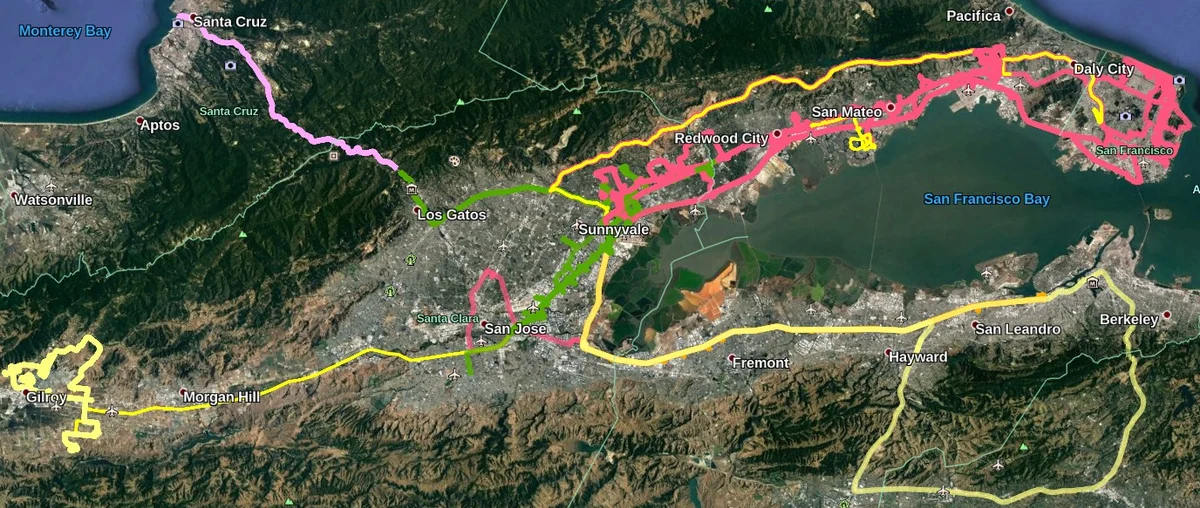
This paper examines the problem of dynamic traffic scene classification under space-time variations in viewpoint that arise from video captured on-board a moving vehicle. Solutions to this problem are important for realization of effective driving assistance technologies required to interpret or predict road user behavior. Currently, dynamic traffic scene classification has not been adequately addressed due to a lack of benchmark datasets that consider spatiotemporal evolution of traffic scenes resulting from a vehicle’s ego-motion. This paper has three main contributions. First, an annotated dataset is released to enable dynamic scene classification that includes 80 hours of diverse high quality driving video data clips collected in the San Francisco Bay area. The dataset includes temporal annotations for road places, road types, weather, and road surface conditions. Second, we introduce novel and baseline algorithms that utilize semantic context and temporal nature of the dataset for dynamic classification of road scenes. Finally, we showcase algorithms and experimental results that highlight how extracted features from scene classification serve as strong priors and help with tactical driver behavior understanding. The results show significant improvement from previously reported driving behavior detection baselines in the literature.
💡 Research Summary
This paper presents a comprehensive study on the problem of dynamic traffic scene classification from the perspective of a moving vehicle (egocentric view). The core challenge addressed is the classification of road scenes amidst substantial spatiotemporal variations in viewpoint caused by the vehicle’s own ego-motion, a problem underrepresented in existing research due to a lack of suitable datasets.
The paper makes three primary contributions. First, it introduces and releases the “Honda Scene Dataset,” a large-scale, temporally annotated dataset designed specifically for dynamic driving scene understanding. The dataset comprises 80 hours of high-quality driving video collected in the San Francisco Bay Area over six months, using varied camera hardware to encourage generalization. Its key innovation is multi-level temporal annotations across four categories: Road Places (e.g., intersections, crosswalks), Road Environment/Types (e.g., urban, highway), Weather, and Road Surface Condition. Notably, Road Places are annotated with fine-grained temporal states—“Approaching (A),” “Entering (E),” and “Passing (P)"—capturing the spatial evolution of a single scene as the vehicle navigates through it.
Second, the paper proposes novel and baseline algorithms that leverage the semantic context and temporal nature of this new dataset. Methodological experiments are built upon a ResNet50 backbone. The authors systematically explore the impact of different input representations: raw RGB images, RGB combined with semantic segmentation maps (RGBS), RGB images with traffic participants masked out (RGB-masked), and semantic segmentation maps alone (S). Findings reveal that the optimal input modality is task-dependent. For instance, masking traffic participants improved weather and road surface classification, while semantic maps alone outperformed RGB for distinguishing certain road environments like “ramps,” highlighting the importance of structural scene information. For the temporally rich Road Places classification, the authors compare frame-averaging, LSTM-based models, and a two-stream architecture designed to generate temporal proposals and aggregate features over trimmed video segments. The two-stream approach proved most effective, demonstrating the benefit of explicitly modeling temporal context over the entire event duration rather than per-frame.
Third, the paper showcases how features extracted from the scene classification models serve as strong priors for downstream tasks, specifically tactical driver behavior understanding. Experimental results demonstrate that utilizing these scene context features leads to significant improvements over previously reported baselines for driver behavior detection. This underscores the practical value of robust scene classification not as an isolated task, but as a foundational module that can provide crucial contextual cues for other perception and prediction systems within an autonomous driving stack.
In summary, this work critically defines the problem of dynamic scene classification under ego-motion, provides a essential benchmark dataset with rich spatiotemporal annotations, presents tailored methodologies that outperform standard approaches, and validates the utility of scene context for higher-level driving behavior analysis. It establishes a significant foundation for future research in fine-grained, context-aware perception for autonomous vehicles and advanced driver-assistance systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment