Supervised Learning in Spiking Neural Networks with Phase-Change Memory Synapses
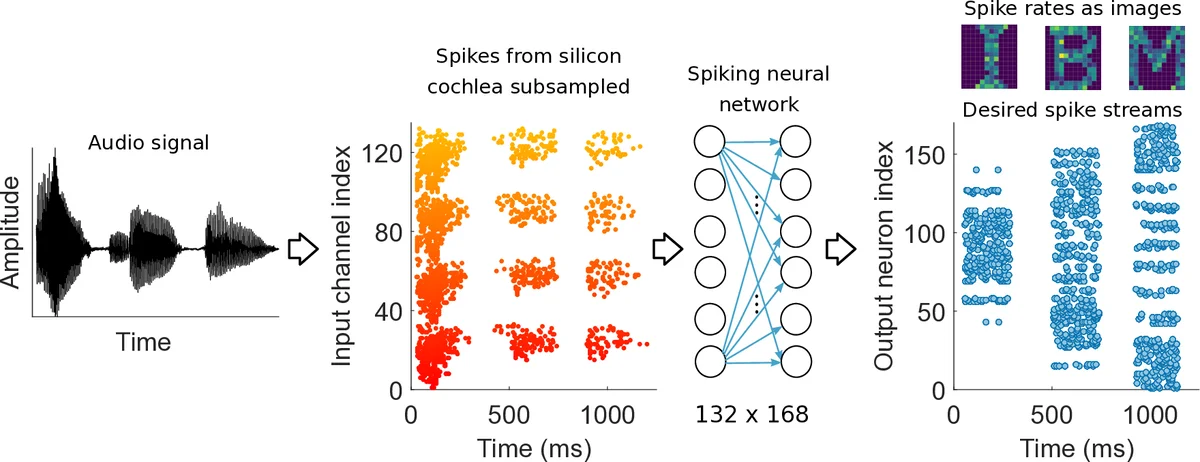
Spiking neural networks (SNN) are artificial computational models that have been inspired by the brain’s ability to naturally encode and process information in the time domain. The added temporal dimension is believed to render them more computationally efficient than the conventional artificial neural networks, though their full computational capabilities are yet to be explored. Recently, computational memory architectures based on non-volatile memory crossbar arrays have shown great promise to implement parallel computations in artificial and spiking neural networks. In this work, we experimentally demonstrate for the first time, the feasibility to realize high-performance event-driven in-situ supervised learning systems using nanoscale and stochastic phase-change synapses. Our SNN is trained to recognize audio signals of alphabets encoded using spikes in the time domain and to generate spike trains at precise time instances to represent the pixel intensities of their corresponding images. Moreover, with a statistical model capturing the experimental behavior of the devices, we investigate architectural and systems-level solutions for improving the training and inference performance of our computational memory-based system. Combining the computational potential of supervised SNNs with the parallel compute power of computational memory, the work paves the way for next-generation of efficient brain-inspired systems.
💡 Research Summary
This paper presents the first experimental demonstration of in‑situ supervised learning for spiking neural networks (SNNs) using phase‑change memory (PCM) devices as analog synapses in a computational‑memory architecture. The authors fabricate a 90 nm CMOS chip containing over one million GST‑based PCM cells and configure each synaptic weight as the difference between two conductances (G⁺ and G⁻). To mitigate the intrinsic non‑linearity, stochasticity, and drift of PCM, each conductance is realized by summing four PCM devices, resulting in a differential, multi‑device synapse that uses eight devices per weight (177 408 devices for 22 176 synapses).
Training is performed with the Normalized Approximate Descent (NormAD) algorithm, which updates weights only at spike events based on the error between desired and observed spike trains. The weight change ΔW is mapped to conductance updates via a scaling factor β and implemented by blind programming pulses (50 ns, 40‑130 µA) without read‑verify, reflecting a realistic low‑overhead computational‑memory scenario.
The experimental task converts spoken alphabet audio (“I”, “B”, “M”) captured by a silicon cochlea into spike streams (132 channels, ~10 Hz). These inputs feed a single‑layer SNN with 168 output neurons, each representing a pixel of a 14 × 12 image. Desired output spikes are generated from a Poisson process proportional to pixel intensities. During training, the network learns to emit spikes at precise times that encode the target images.
Results show that increasing the number of PCM devices per synapse improves classification accuracy: a single‑device synapse reaches ~70 % accuracy, while a four‑device configuration attains a peak of 92.5 %. Adding random jitter to input spikes accelerates convergence, and an array‑level compensation scheme mitigates accuracy loss due to conductance drift over time. Simulations using a statistical PCM model closely match hardware measurements, confirming the validity of the device model.
Energy analysis indicates that read operations consume only 1‑100 fJ per device, and because only one of the four devices per synapse is programmed per update, the overhead remains modest. Although peripheral neuron circuits dominate area in the current prototype, PCM scaling promises substantial reduction in synapse footprint, making the approach scalable to larger networks.
In summary, the work demonstrates that PCM‑based computational memory can support high‑performance, event‑driven supervised learning in SNNs, achieving precise spike‑time encoding with competitive accuracy and low energy. The combination of differential multi‑device synapses, blind programming, and spike‑time‑based learning algorithms offers a viable path toward brain‑inspired, energy‑efficient AI hardware. Future directions include deeper network architectures, multi‑class tasks, integration with on‑chip neuron circuits, and direct interfacing with event‑based sensors such as artificial retinas or cochleae.
Comments & Academic Discussion
Loading comments...
Leave a Comment