A Convex Approximation of the Relaxed Binaural Beamforming Optimization Problem
The recently proposed relaxed binaural beamforming (RBB) optimization problem provides a flexible trade-off between noise suppression and binaural-cue preservation of the sound sources in the acoustic scene. It minimizes the output noise power, under…
Authors: Andreas I. Koutrouvelis, Richard C. Hendriks, Richard Heusdens
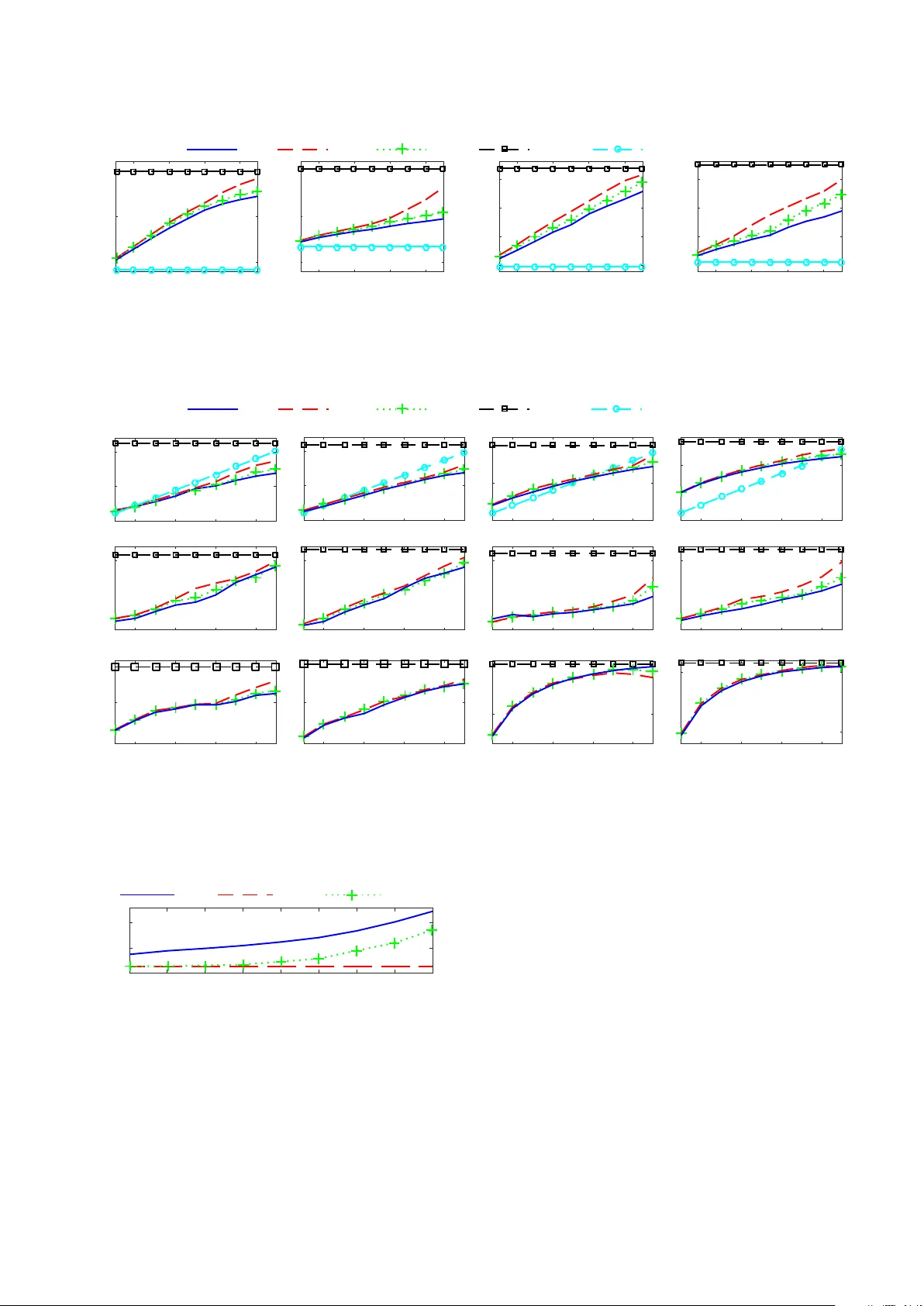
1 A Con v e x Approximation of the Relax ed Binaural Beamforming Optimization Problem Andreas I. K outrouvelis, Richard C. Hendriks, Richard Heusdens and Jesper Jensen Abstract —The recently pr oposed relaxed binaural beamf orm- ing (RBB) optimization problem pr ovides a flexible trade-off between noise suppr ession and binaural-cue pr eservation of the sound sour ces in the acoustic scene. It minimizes the output noise power , under the constraints which guarantee that the target remains unchanged after processing and the binaural-cue distortions of the acoustic sources will be less than a user -defined threshold. Howev er , the RBB problem is a computationally demanding non-conv ex optimization problem. The only existing suboptimal method which approximately solves the RBB is a successive convex optimization (SCO) method which, typically , requir es to solve multiple conv ex optimization problems per fre- quency bin, in order to conver ge. Conv ergence is achieved when all constraints of the RBB optimization problem are satisfied. In this paper , we propose a semi-definite con vex relaxation (SDCR) of the RBB optimization problem. The proposed suboptimal SDCR method solves a single convex optimization problem per frequency bin, resulting in a much lower computational complexity than the SCO method. Unlike the SCO method, the SDCR method does not guarantee user -contr olled upper -bounded binaural-cue distortions. T o tackle this problem we also propose a suboptimal hybrid method which combines the SDCR and SCO methods. Instrumental measures combined with a listening test show that the SDCR and hybrid methods achiev e significantly lower computational complexity than the SCO method, and in most cases better trade-off between predicted intelligibility and binaural-cue preserv ation than the SCO method. Index T erms —Binaural beamforming, binaural cues, convex optimization, LCMV , noise reduction, semi-definite relaxation. I . I N T RO D U C T I O N B IN A URAL beamforming (see e.g., [1] for an overvie w), also known as binaural spatial filtering, plays an impor- tant role in binaural hearing-aid (HA) systems [2]. Binaural beamforming is typically described as an optimization prob- lem, where the objective is to i) minimize the output noise power , ii) preserve the target sound source at the left and right HA reference microphone, and iii) preserve the binaural cues of all sound sources after processing. The microphone array , which is typically mounted on the HA devices, has only a few microphones and, thus, there is only limited freedom (i.e., a small feasibility set) to search for a good compromise between the three aforementioned goals. Besides the challenge in finding a good trade-of f among all these goals, the complexity should remain as lo w as possible, due to the limited computational po wer of the HA de vices. The binaural minimum v ariance distortionless response (BMVDR) BF [1] pro vides the maximum possible noise suppression among all binaural target-distortionless BFs [3]. This work was supported by the Oticon Foundation and NWO, the Dutch Organisation for Scientific Research. Unfortunately , the BMVDR severely distorts the binaural-cues of the residual noise at the output of the filter . Specifically , the residual noise inherits the intaraural transfer function of the tar get and, hence, sounds as originating from the target’ s direction [1]. The lack of spatial separation between the target and the noise after processing, may not only provide an unnat- ural impression to the user , but may also negati vely effect the intelligiblity [4]. In [5], [6], the BMVDR was compared with an oracle-based (i.e., non-practically implementable) method in several noise fields. The oracle-based method has the same noise suppression as the BMVDR, but does not introduce any binaural-cue distortions at the output. The spatially correct oracle-based method achieved an improvement of about 3 dB in SR T -50 1 ov er the BMVDR. Therefore, there are several reasons to seek for methods that simultaneously provide the maximum possible noise suppression and binaural-cue preser- vation of all sources in the acoustic scene. Sev eral modifications of the BMVDR BF hav e been pro- posed, which can be roughly categorized into two groups. The first group consists of BFs that add or maintain a portion of the unprocessed scene at the output of the filter (see e.g., [5], [7]– [9]). The second group consists of BFs, whose optimization problems hav e the same objectiv e function as the BMVDR, but introduce e xtra equality [3], [10], [11] or inequality [12] constraints in order to preserve the binaural cues of the interferers after processing. Such additional constraints in the optimization problem results in less degrees of freedom for noise reduction. With equality constraints, closed-form solutions may be deriv ed, but the degrees of freedom can be easily exhausted when multiple interferers exist in the acoustic scene, resulting in poor noise reduction. On the other hand, inequality constraints provide more flexibility and can approximately preserve the binaural cues of, typically , many more acoustic sources, or for the same number of acoustic sources provide larger amount of noise reduction [12]. Unfor- tunately , closed-form solutions do not exist for the inequality- constrained binaural BFs and, thus, iterati ve methods with a larger complexity are used instead. Recently , the relaxed binaural beamforming (RBB) op- timization problem was proposed, which uses inequality constraints to preserve the binaural cues of the interfering sources [12]. The inequality constraints in the RBB are not conv ex, resulting in a non-con ve x optimization problem. In [12], a suboptimal successiv e con ve x optimization (SCO) method w as proposed to approximately solve the RBB prob- 1 Speech reception threshold (SR T)-50 is the SNR in which a 50% correct recognition of words is achieved. 2 lem. In most cases, the SCO method needs to solve more than one conv ex optimization problem, per frequency bin, in order to conv erge. Con ver gence is achiev ed when all constraints of the RBB problem are satisfied. As a result, the SCO method guarantees an upper -bounded binaural-cue distortion of the interferers (as expressed by the interaural transfer function error), where the upper bound is controlled by the user . Unfortunately , the SCO method is computationally very de- manding due to its need to solve multiple con ve x optimization problems, per frequency bin, in order to con verge. In this paper , we propose a semi-definite con vex relaxation (SDCR) of the RBB optimization problem, which is significantly faster than the SCO method. This is because, the SDCR method requires to solve only one con vex optimization problem per frequency bin. The main dra wback of the SDCR method is that it does not guarantee user-controlled upper-bounded binaural-cue distortions as the SCO method. W e solve this issue by combining the SDCR and SCO methods into a sub- optimal hybrid method. The hybrid method guarantees user - controlled upper-bounded binaural-cue distortions, and still has a significantly lower computational complexity than the SCO method. Simulation experiments combined with listening tests sho w that both proposed methods, in most cases, provide a better trade-off between noise reduction and binaural-cue preservation than the SCO method. I I . S I G N A L M O D E L A N D N OTA T I O N W e assume that there is one target point-source signal, r point-source interferers, additive diffuse noise, and two HAs with M microphones in total. The processing is ac- complished per time-frequency bin independently . Neglecting time-frequency indices for brevity , the acquired M -element noisy v ector in the DFT domain, for a single time-frequency bin, is gi ven by y = s a |{z} x + r X i =1 v i b i + u | {z } n ∈ C M × 1 , (1) where s and v i are the target and i -th interferer signals at the original locations; a and b i the acoustic transfer function (A TF) vectors of the target and i -th interferer, respectiv ely; u the diffuse background noise, and n the total additi ve noise. Assuming statistical independence between all sources, the noisy cross-power spectral density matrix is giv en by P y = E [ yy H ] = P x + P n ∈ C M × M , (2) with P x = E [ xx H ] = p s aa H and P n = E [ nn H ] the target and noise cross-power spectral density matrices, respecti vely , and p s = E [ | s | 2 ] the power spectral density of the target signal. I I I . B I N AU R A L B E A M F O R M I N G P R E L I M I NA R I E S Binaural BFs consist of two spatial filters, w L , w R ∈ C M × 1 , which are both applied to the noisy measurements producing two different outputs given by ˆ x L ˆ x R = w H L y w H R y , (3) where ˆ x L , ˆ x R are played back by the loudspeakers of the left and right HAs, respectively . Note that the subscripts L and R are also used to refer to the two elements of the vectors in Eq. (1) associated with the left and right reference microphones of the binaural BF . Here, we select the first and the M -th microphones as reference microphones and, thus, y L = y 1 and y R = y M . The same applies to all the other vectors in Eq. (1). All BFs considered in this paper are target-distortionless. Their goal is not only noise supression, but also preservation of the binaural cues of all sources in the acoustic scene. In this paper , we mainly focus on preserving, after processing, the perceived location of the point sources. A simple way of measuring the binaural cues of a point source is via the interaural transfer function (ITF), which is a function of the A TF vector of the source [13]. The ITF of the i -th interferer before and after applying the spatial filter is gi ven by [13] ITF in i = b iL b iR , ITF out i = w H L b i w H R b i . (4) The input and output ITF of the target is expressed similarly . Ideally , to preserve all spatial cues of the point sources, a binaural BF will produce the same ITF output as the input for all point sources. In practice, this is very difficult to achie ve, when the number of interferers, r , is large and the number of microphones, M , is small [12]. As a result, most BFs will introduce some distortion to the ITF output, resulting in a non-zero ITF error given by [12] ITF e i = ITF out i − ITF in i = w H L b i w H R b i − b iL b iR ≥ 0 . (5) A. BMVDR Beamforming The BMVDR BF [1] achiev es the maximum possible noise suppression among all binaural BFs and is obtained from the following simple optimization problem [1], [3]: ˆ w L , ˆ w R = arg min w L , w R w H L w H R ˜ P w L w R s.t. w H L a = a ∗ L w H R a = a ∗ R , (6) where ˜ P = P n 0 0 P n . (7) The optimization problem in Eq. (6) provides closed-form solutions to the left and right spatial filters gi ven by [1], [3] ˆ w L = P − 1 n a a ∗ L a H P − 1 n a , ˆ w R = P − 1 n a a ∗ R a H P − 1 n a . (8) It can easily be shown, that the output ITF of the i -th interferer of the BMVDR spatial filter is given by [3], [12] ITF out i = a L a R , (9) which is the ITF input of the target. Therefore, all interferers sound as coming from the tar get direction after applying the BMVDR spatial filter . The BMVDR ITF error of the i -th interferer is gi ven by [12] ITF e,BMVDR i = a L a R − b iL b iR . (10) 3 B. Relaxed Binaural Beamforming The relaxed binaural beamforming (RBB) optimization problem, introduced in [12], uses additional inequality con- straints (compared to the BMVDR problem) to preserve the binaural cues of the interferers. The RBB problem is given by [12] ˆ w L , ˆ w R = arg min w L , w R w H L w H R ˜ P w L w R s.t. w H L a = a ∗ L w H R a = a ∗ R , w H L b i w H R b i − b iL b iR ≤ E i , i = 1 , · · · , m ≤ r , (11) where E i = c i ITF e,BMVDR i , 0 ≤ c i ≤ 1 . Note that E i is c i times the ITF error of the i -th interferer of the BMVDR BF [12]. Recall that the BMVDR causes full collapse of the binuaral cues of the interferers towards the binaural cues of the target. Therefore, the inequality constraints in Eq. (11) control the percentage of collapse. A small c i implies good preservation of binaural cues of the i -th interferer , but a smaller feasibility set and, thus, less noise reduction. On the other hand, a large c i implies worse binaural-cue preserv ation, but more noise reduction. It is clear from the abov e that the additional inequality constraints of the RBB problem require the knowledge of the (relativ e) A TF vectors of the interferers. In practice, interferers’ (R)A TF vectors are unknown and estimation is required. Sev eral methods for estimating RA TF v ectors exist (see e.g., [14] for an overvie w). An alternative approach is to use pre-determined ancechoic (R)A TF v ectors of fixed az- imuths around the head of the user , as proposed in [15]. These pre-determined (R)A TF vectors are acoustic scene independent and need to be obtained once for each user . This is useful when the (R)A TF vectors of the interferers are difficult to estimate, because e.g., the locations of the interferers relati ve to the head of the user are non-static. It is worth noting that by using pre-determined (R)A TF vectors, a larger number of inequality constraints, m > r , is typically used in Eq. (11). This is because we do not know where the interferers are located and we would like to cover the entire space around the head of the user . If c i > 0 , i = 1 , · · · , m , the inequality constraints of the optimization problem in Eq. (11) are non-con ve x. As a result, the optimization problem in Eq. (11) is non-con ve x. In [12], a suboptimal successiv e con ve x optimization (SCO) method [12], described in Section III-C, was proposed to approximately solve the RBB problem. C. Successive Con vex Optimization method The successiv e con vex optimization (SCO) method [12] approximately solves the RBB problem by solving multiple con ve x optimization problems per frequency bin. The SCO method con ver ges, when all constraints of the RBB problem in Eq. (11) are satisfied. It has been sho wn that the SCO method always con ver ges to a solution satisfying the constraints of the RBB problem if m ≤ 2 M − 3 . This means that if the (R)A TF vectors of the interferers hav e been estimated accurately enough, the SCO method will guarantee user-controlled upper- bounded ITF error of the interferers [12]. For m > 2 M − 3 , no guarantees exist for conv ergence. In case the method does not con ver ge, it stops after solving a pre-defined maximum number of conv ex optimization problems, k max . Nev ertheless, for a reasonable number of inequality constraints, m , it has been experimentally shown that the SCO method alw ays con ver ges [12], [15]. A disadvantage of the SCO method is that it has been experimentally shown in [12], that for larger c i values, the SCO method conv erges to solutions further a way from the boundary of the inequality constraints of the RBB problem. This results in a better binaural-cue preservation and less noise reduction compared to the expected trade-of f set by the user through the parameters c i , i = 1 , · · · , m . I V . P R O P O S E D C O N V E X A P P R OX I M A T I O N M E T H O D The proposed method is a semi-definite con vex relaxation (SDCR) of the optimization problem in Eq. (11). First, we revie w two important properties that will be useful for under- standing the proposed optimization problem. Pr operty 1: Any quadratic expression can be expressed as [16] q H Zq = tr q H Zq = tr qq H Z . (12) Pr operty 2: W e have the following equiv alence relation [17] Z = A B B H C 0 ⇔ A 0 , I − AA † B = 0 , S 1 0 , (13) C 0 , I − CC † B H = 0 , S 2 0 , (14) with S 1 = C − B H A † B the generalized Schur complement of A in Z , S 2 = A − BC † B H the generalized Schur complement of C in Z , and A † is the pseudo-in verse of A [18]. Before, we present the proposed conv ex optimization prob- lem, we first introduce an equiv alent optimization problem to the problem in Eq. (11). That is, ˆ w L , ˆ w R = arg min w L , w R w H L w H R ˜ P w L w R s.t. w H L a = a H L w H R a = a H R , w H L b i w H R b i − b iL b iR 2 ≤ E 2 i , i = 1 , · · · , m ≤ r . (15) By reformulating the inequality in Eq. (15), we obtain an equiv alent quadratic constraint giv en by w H L b i w H R b i − b iL b iR 2 ≤ E 2 i ⇒ w H L w H R | {z } w H A B B H C | {z } M i w L w R | {z } w ≤ 0 , (16) 4 where A = | b iR | 2 b i b H i , B = − b ∗ iL b iR b i b H i , C = | b iL | 2 − | b iR | 2 E 2 i b i b H i . Therefore, the optimization prob- lem in Eq. (15) can be re-written as ˆ w = arg min w w H ˜ Pw s.t. w H a 0 0 a = a ∗ L a ∗ R , w H M i w ≤ 0 , i = 1 , · · · , m. (17) The matrix M i is not positi ve semi-definite and, therefore, the quadratic inequality constraint is not conv ex and, hence, the optimization problem in Eq. (17) is not con ve x. The proof of non positi ve semi-definiteness of M i uses Property 2 . Specifically , note that A 0 , but S 1 = −| b iR | 2 E 2 i b i b H i 0 , because b i b H i 0 and −| b iR | 2 E 2 i ≤ 0 and, therefore, M i is not positiv e semi-definite. The optimization problem in Eq. (17) is a non-conv ex quadratic-constrained quadratic program (QCQP) [17], [19]. Follo wing the methodology described in [19], we use Property 1 to re-write the optimization problem in Eq. (17) into the following equiv alent formulation: ˆ w , ˆ W = arg min w , W tr W ˜ P s.t. w H a 0 0 a = a ∗ L a ∗ R , tr ( WM i ) ≤ 0 , i = 1 , · · · , m, W = ww H . (18) The optimization problem in Eq. (18) is still not con vex, but it has two differences with the problem in Eq. (17). The trace inequality is con ve x, but the new equality constraint, W = ww H is not con vex. Following [19], we apply the SDCR to the non-con vex equality constraint of the problem in Eq. (18) and obtain the conv ex optimization problem gi ven by ˆ w , ˆ W = arg min w , W tr W ˜ P s.t. w H a 0 0 a = a ∗ L a ∗ R , tr ( WM i ) ≤ 0 , i = 1 , · · · , m. W ww H . (19) Using Property 2, the inequality constraint W ww H can be re-written as a linear matrix inequality , and the optimization problem in Eq. (19) can be re-written into a standard-form semi-definite program [19]. That is, ˆ w , ˆ W = arg min w , W tr W ˜ P s.t. w H a 0 0 a = a ∗ L a ∗ R , tr ( WM i ) ≤ 0 , i = 1 , · · · , m. W w w H 1 0 . (20) This is a con ve x optimization problem, which can be solved efficiently [19]. If the solutions are on the boundary , i.e., ˆ W = ˆ w ˆ w H , the minimizer, ˆ w , of the problem in Eq. (20) is also the minimizer of the non-con ve x RBB problem. This means, that in the case of ˆ W = ˆ w ˆ w H , the proposed problem in Eq. (20) is optimal. Moreover , in this case, the inequalities of the problem in Eqs. (17), (15) (11) are satisfied. Otherwise, if ˆ W ˆ w ˆ w H , the solution of the problem in Eq. (20) may or may not satisfy the inequalities of the RBB, which means that we lose the guarantee for user-controlled upper- bounded ITF error when the (R)A TF vectors of the interferers hav e been estimated accurately enough. In our experience, in practice ˆ W = ˆ w ˆ w H almost neve r happens. Nev ertheless, we will experimentally show in Section V that the SDCR method always stays relativ ely close to the boundary of the inequality constraints of the RBB problem. Finally , the main advantage of the new proposed SDCR method is that it reduces significantly the computational complexity , since a single con vex optimization problem is solved compared to the multiple con vex optimization problems that must be solved in the SCO method. A. Proposed Hybrid Method In this section, we propose a hybrid method, which com- bines the SDCR and the SCO methods into a single method. If the (R)A TF vectors of the interferers are estimated accurately enough, the hybrid method guarantees user-controlled upper - bounded binaural-cue distortions of the interferers as in the first version of the SCO method. Moreover , the proposed hybrid method is significantly faster than the SCO method and slightly slo wer than the SDCR method. W e will e xperimentally show in Section V, that the hybrid proposed method achiev es solutions closer to the boundary of the inequality constraints of the RBB problem compared to the SCO method, while at the same time achieving more noise suppression. For a particular frequenc y bin, the hybrid method first solv es the SDCR problem and then checks if the inequality con- straints of Eq. (11) are satisfied. If all of them are satisfied, the SDCR method will be used to approximately solv e the RBB problem. Otherwise the SCO method is used to approximately solve the RBB problem in this particular frequenc y bin. In such a way , there is a guarantee that we will always hav e an optimal solution which satisfies the constraints of the RBB problem, while at the same time reducing the ov erall computational complexity significantly . In order to avoid switching to the SCO method for just negligibly larger ITF errors than the user- controlled upper bounds E i , we use the following switching criterion: w H L b i w H R b i − b iL b iR ≤ ˜ E i , i = 1 , · · · , m, (21) where ˜ E i is a slightly increased upper bound and is gi ven by ˜ E i = ( c i + ) a L a R − b iL b iR , i = 1 , · · · , m, (22) where is very small, e.g., 0 < < 0 . 1 . This modification av oids possible switching to the SCO method for negligibly larger ITF errors than the E i . The hybrid method is summa- rized in Algorithm 1. 5 Algorithm 1: Hybrid scheme ˆ w 1 ← SDCR Problem in Eq. (20) if ˆ w 1 satisfies Eq. (21) then return ˆ w 1 else ˆ w 2 ← SCO method [12] return ˆ w 2 end if V . E X P E R I M E N T S W e conducted two different sets of experiments: the first examines the performance difference between the SCO method [12] (with k max = 50 ), the proposed SDCR method, and the proposed hybrid (with = 0 . 05 ) method, when the true RA TF vectors of the interferers are used. The reason for that is to show the theoretical trade-of f between noise re- duction and binaural-cue preservation. The second experiment examines the performance of the same methods, when the pre- determined RA TF vectors are used for preserving the binaural cues of the interferers. Note that in both sets of experiments, we used the true RA TF vector of the target source. W e used the CVX toolbox [20] to solve the con ve x optimization problems associated with the SCO, SDCR and hybrid methods. The CVX toolbox uses an interior point method to solve the con vex optimization problems [17]. In all methods that approximately solve the RBB problem, we used a common c value for all interferers in the inequality constraints, i.e., c i = c, ∀ i . W e also included the BMVDR BF as a reference method in the comparisons. The noise cross-power spectral density matrix was estimated using 5 seconds of a noise-only segment, where all interferers are active, but the target source is inactive. The spatial filters of all methods were estimated only once using the same estimated noise cross-po wer spectral density matrix and, thus, the y are time inv ariant. Note that for the pre-determined RA TF vectors, we used the RA TF vectors of 24 pre-determined anechoic head impulse responses from the database in [21]. The pre-determined RA TF vectors are associated with azimuths uniformly spaced around the head with a resolution of 360 / 24 = 15 degrees, starting from − 90 degrees. Please note that the pre-determined RA TF vector at 0 degrees was omitted from the constraints, because it was in the same direction as the RA TF vector of the target. A. Acoustic Scene Setup The acoustic scene that we used consists of one target female talker in the look direction (i.e., 0 degrees), and 4 interferers, where each has the same average po wer at its original location, as the target signal at the original location. The first interferer is a male talker on the right-hand side of the HA user with azimuth of 80 degrees; the second interferer is a music signal on the right-hand side of the HA user with azimuth of 50 degrees; the third interferer is a v acuum cleaner on the left-hand side of the HA user with azimuth − 35 degrees; and the fourth interferer is a ringing mobile phone on the left-hand side with azimuth − 70 de grees. Note that the RA TF vectors of all interferers hav e an azimuth mismatch with the pre-determined RA TF vectors’ azimuths. The microphone self-noise is set to have a 40 dB SNR at the left reference microphone, and it has the same power in all microphones. B. Hearing-Aid Setup and Pr ocessing The total number of microphones is M = 4 ; two at each HA. The sampling frequency is 16 kHz. The microphone signals were constructed using the head impulse responses from the reverberant office en vironment from the database in [21]. W e used the overlap-and-add processing method [22] for analyzing and synthesizing our signals. The analysis and synthesis windows are square-root Hanning windows and the ov erlap is 50% . The frame length is 10 ms, i.e., 160 samples, and the FFT size is 256 . C. Evaluation Methodology W e measure the noise-reduction performance in terms of the segmental signal-to-noise-ratio (SSNR) only in target-presence time re gions. W e used an ideal activity detector to find these time-regions. W e also predict intelligibility with the STOI measure [23]. W e measure binaural-cue distortions with instrumental mea- sures and a listening test. The instrumental measures are the av erage ITF error , interaural le vel difference (ILD) error and interaural phase difference (IPD) error per interferer . These av erages are calculated only ov er frequency , since we hav e fixed BFs over time. Note that, for the IPD error , we averaged only the frequency bins in the range of 0 − 1 . 5 kHz, while for the ILD error, we a veraged only the frequency bins in the range of 3 − 8 kHz. The reason for this choice is that the ILDs are perceptually more important for localization abov e 3 kHz, while the IPDs are perceptually more important for localization below 1 . 5 kHz [24]. Note that we used the expressions from [13] for computing the ILD and IPD errors for a single frequency bin. W e do not measure the binaural-cue distortions of the target, because all methods achieve perfect preservation of the binaural-cues of the target, since i) there are no estimation errors on the RA TF vector of the target signal used in the associated optimization problems and ii) the response of the binaural spatial filter with respect to the target at the two reference microphones is distortionless. The listening test is performed using the methodology described in [6], and examines the performance of the com- pared methods only in the case of the pre-determined RA TF vectors. T en normal-hearing subjects participated, excluding the authors. They were asked to determine the azimuths of all point-sources in the acoustic scene when listening to signals processed by the compared methods as well as the unprocessed scene. The tested c values were 0 . 3 and 0 . 7 for the SCO, SDCR and hybrid methods. In addition to listening to the noisy and processed signals, the subjects also listened to the clean unprocessed point sources in isolation, in order to determine the reference azimuthms of the point sources. The localization errors were calculated with respect to the reference (and not the true) azimuths as in [6]. This is because we used only 6 0.2 0.4 0.6 0.8 c -20 -15 -10 SSNR L (dB) SCO SDCR Hybrid BMVDR Unprocessed 0.2 0.4 0.6 0.8 c -20 -15 -10 SSNR R (dB) 0.2 0.4 0.6 0.8 c 0.35 0.4 0.45 0.5 STOI L 0.2 0.4 0.6 0.8 c 0.35 0.4 0.45 0.5 STOI R Fig. 1: Noise reduction and intelligiblity prediction performances when the true RA TF vectors of the interferers are used in the SCO, SDCR and hybrid methods. one set of head impulse responses from [21] to construct the binaural signals, which means that e very subject will hav e a different reference azimuth. In this way , a significant estimation bias was removed. T wo repetitions of the listening test were conducted. The reference azimuth of each source and ev ery subject was computed as the av erage between the two repetitions, and the error was computed with respect to this a veraged reference azimuth. The localization errors of the sources were av eraged ov er subjects and repetitions. A t-test was used in order determine whether the methods result in statistically significantly different perceiv ed source locations. W e also measured the complexity of the compared methods in terms of the number of con vex optimization problems that they needed to solve for all frequency bins in total. Note that the BFs are fixed over time and, therefore, we do not measure varying complexity over time. D. Discussion of Results with T rue RA TF V ectors In this section, the compared methods use the true RA TF vectors of the sources in the constraints. Fig. 1 depicts the noise reduction performance and intelligibility prediction of the unprocessed scene, and SCO, SDCR, BMVDR methods at both reference microphones. As expected the BMVDR achiev es the best noise reduction performance and predicted intelligibility . It is clear , that all other methods achieve similar performances for the left reference microphone, while for the right reference microphone the SCO method achie ves the worst noise reduction performance among all. Moreov er , as expected, as c increases, the noise reduction and STOI v alue increases for all methods. Note that the SDCR method has almost identical performance as the hybrid method. This is because, in this example the hybrid method switched to the SCO method only a fe w times. Fig. 2 sho ws the binaural-cue distortions of the com- pared methods per interfering source. As expected, the larger binaural-cue distortions are obtained with the BMVDR BF , while all other methods achiev e less binaural-cue distortions. As expected, as c increases, the binaural-cue distortions in- crease. Note that for the ITF errors, we also display the c times the ITF error of the BMVDR (which is labeled as ITF upper bound) in order to visualize the closeness of the estimated spatial filters at the boundary of the inequality constraints of the RBB problem. It is clear that both SDCR and hybrid meth- ods are closer to the boundary of the inequality constraints compared to the SCO method. Moreover , the hybrid method is for all c v alues (on av erage) below the boundary , ev en if we used the extended switch criterion in Eq. (21). On the other hand, the ITF error of the SDCR method sometimes (see Interferers 1 and 2) is slightly above the boundary . As explained in Section IV, this is because the SDCR method does not guarantee a user-controlled upper -bounded ITF error as the SCO or the hybrid methods do. Note also that as expected the SCO method for e.g., c = 0 . 8 , 0 . 9 v alues, is not close to the boundary , while the SDCR and hybrid methods are closer to the boundary . Fig. 3 shows the computational complexity of the compared methods in terms of number of con vex optimization problems required to solve for con vergence. The SDCR method requires to solve much less conv ex problems than the SCO method (especially at larger c values) and slightly less compared to the hybrid method. The hybrid method again requires to solve much less con vex problems than the SCO method, especially at larger c values. W e can conclude from the above that, in most cases, the theoretical performance (i.e., when the true RA TF vectors are used) of both proposed methods is more optimal than the SCO method. Specifically , both proposed methods provide solutions that are closer to the expected solutions of the RBB problem, since both proposed methods are closer to the boundary . This means that both methods provide a more user-controlled trade- off between noise reduction and binaural-cue preserv ation than the SCO method, especially in large c values. Finally both proposed methods are significantly less computationally demanding than the SCO method. E. Discussion of Results with Pr e-Determined RA TF V ectors In this section, the compared methods use the pre- determined RA TF vectors. Fig. 4 shows the noise reduction performance and intelligibility prediction of the compared methods. Here the gap in performance between the proposed methods and the SCO method is bigger compared to the case where the true RA TF vectors were used. The proposed methods (especially the SDCR method) significantly improved both noise reduction and predicted intelligibility at both ref- erence microphones. The reason why the performance gap 7 0.2 0.4 0.6 0.8 0 0.5 1 ITF error Interferer 1 SCO SDCR Hybrid BMVDR ITF upper bound 0.2 0.4 0.6 0.8 0 0.5 1 Interferer 2 0.2 0.4 0.6 0.8 0 2 4 Interferer 3 0.2 0.4 0.6 0.8 0 5 Interferer 4 0.2 0.4 0.6 0.8 0 0.5 IPD error 0.2 0.4 0.6 0.8 0 0.5 0.2 0.4 0.6 0.8 0 0.5 0.2 0.4 0.6 0.8 0 0.5 0.2 0.4 0.6 0.8 c -15 -10 -5 0 ILD error (dB) 0.2 0.4 0.6 0.8 c -15 -10 -5 0 0.2 0.4 0.6 0.8 c 0 5 10 0.2 0.4 0.6 0.8 c 5 10 15 Fig. 2: Binaural-cue distortions (av eraged ov er frequency) of interferers when the true RA TF vectors of the interferers are used in the SCO, SDCR and hybrid methods. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 c 0 500 1000 # solved problems SCO SDCR Hybrid Fig. 3: Computational complexity measured as the number of solved conv ex optimization problems (in all frequency bins) when the true RA TF vectors of the interferers are used in the SCO, SDCR and hybrid methods. between the SDCR method and the hybrid method is increased compared to the case where the true RA TF vectors were used is because the hybrid method switched many more times to the SCO method (see Algorithm 1) here. In conclusion, both proposed methods achiev e in most cases a better noise reduction and predicted intelligibility than the SCO method, especially for lar ger c values. Fig. 5 sho ws the binaural-cue distortions of the com- pared methods per interfering source. As expected, when pre- determined RA TF vectors are used, all methods do not guaran- tee user-controlled upper-bounded ITF error of the interferers. Therefore, all methods, in many occasions (see interferers 3 and 4), result in a larger ITF error than the av erage ITF upper bound of the RBB problem when computed using the true RA TFs of the interferers. The SCO method has the lo west binaural-cue distortions compared to the compared methods. Nev ertheless, we will see later on in the t-test of the listening test that the compared methods are not significantly different for the same c v alues. In Fig. 6, we sho w the computational complexities of the compared methods. Again the SDCR method requires to solve less con vex problems compared to the SCO method, but the hybrid method does not have a huge computational advantage ov er the SCO method in this case. Howe ver , the usage of the hybrid method using pre-determined (R)A TF vectors is not critical, since anyw ay no method can guarantee user -controlled upper-bounded ITF error of the interferers, unless the number of pre-determined RA TF vectors is huge. This of course is not practical since it may result in non-feasible solutions and/or the noise reduction will be negligible due to the large number of constraints. Fig. 7 sho ws the results of the subjecti ve localization test. A similar behavior as with the instrumental binaural-cue dis- tortion measures is observed here. The only dif ference appears for the ringing mobile phone, where for c = 0 . 7 all methods achiev e slightly worse performance than the BMVDR. Se veral users also reported difficulty in localizing the ringing phone after completing the test. W e believe that this is because of the high frequency content of the ringing tone of the mobile phone and only the ILDs might hav e been used for localization. T able I sho ws the results of the t-test, which was done by gathering all localization errors of all sources. The significance lev el was set to 5% . It is clear that the SCO, SDCR and hybrid methods are all not significantly different for the same c v alue. This means that ev en though we observed less binaural-cue distortions in the SCO method in Figs 2 and 5, compared to the proposed methods for the same c value, these 8 0.2 0.4 0.6 0.8 c -20 -15 -10 SSNR L (dB) SCO SDCR Hybrid BMVDR Unprocessed 0.2 0.4 0.6 0.8 c -20 -15 -10 SSNR R (dB) 0.2 0.4 0.6 0.8 c 0.35 0.4 0.45 0.5 STOI L 0.2 0.4 0.6 0.8 c 0.35 0.4 0.45 0.5 STOI R Fig. 4: Noise reduction and intelligiblity prediction performances when the pre-determined RA TF vectors of the interferers are used in the SCO, SDCR and hybrid methods. 0.2 0.4 0.6 0.8 0 0.5 1 ITF error Interferer 1 SCO SDCR Hybrid BMVDR ITF upper bound 0.2 0.4 0.6 0.8 0 0.5 1 Interferer 2 0.2 0.4 0.6 0.8 0 2 4 Interferer 3 0.2 0.4 0.6 0.8 0 5 Interferer 4 0.2 0.4 0.6 0.8 0 0.5 IPD error 0.2 0.4 0.6 0.8 0 0.5 0.2 0.4 0.6 0.8 0 0.5 0.2 0.4 0.6 0.8 0 0.5 0.2 0.4 0.6 0.8 c -20 -10 0 ILD error (dB) 0.2 0.4 0.6 0.8 c -20 -10 0 0.2 0.4 0.6 0.8 c 5 10 0.2 0.4 0.6 0.8 c 10 15 Fig. 5: Binaural-cue distortions (a veraged o ver frequency) of interferers when the pre-determined RA TF vectors of the interferers are used in the SCO, SDCR and hybrid methods. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 c 0 500 1000 # solved problems SCO SDCR Hybrid Fig. 6: Computational complexity measured as the number of solved conv ex optimization problems (in all frequency bins) when the pre-determined RA TF vectors of the interferers are used in the SCO, SDCR and hybrid methods. differences are not perceptually important. Ho wever , recall that the proposed methods achieve a better noise reduction and predicted intelligibility compared to the SCO method. Thus, the proposed methods provide a better perceptual trade-of f compared to the SCO method. Finally , note that the SCO, SDCR and hybrid methods are not statistically significantly different from the unprocessed scene for c = 0 . 3 . This means that in all three methods the subjects managed (on av erage) to localize as good as in the unprocessed scene. Ho wev er , unlike the unprocessed scene, all three methods improved noise reduction and predicted intelligibility . V I . C O N C L U S I O N W e proposed two new suboptimal methods for approxi- mately solving the non-conv ex relaxed binaural beamforming (RBB) optimization problem. Both methods are significantly computationally less demanding compared to the existing successiv e con vex optimization (SCO) method. For each fre- 9 0 50 100 150 error (deg.) female talker (target) mean median 0 50 100 150 error (deg.) male talker 0 50 100 150 error (deg.) ringing phone 0 50 100 150 error (deg.) music 0 50 100 150 error (deg.) vacuum cleaner BMVDR SCO c=0.3 SCO c=0.7 SDCR c=0.3 SDCR c=0.7 hybrid c=0.3 hybrid c=0.7 unpr. 0 50 100 150 error (deg.) all sources Fig. 7: Localization test comparing the SCO, SDCR and hybrid methods with respect to the localization error in degrees. quency bin, the SCO method requires to solve multiple con- ve x optimization problems in order to con verge. In contrast, the first proposed method, which is a semi-definite con ve x relaxation (SDCR) of the RBB problem, solves only one con ve x optimization problem per frequency bin. Apart from the computational advantage, the SDCR method also achiev es in most cases a better trade-off between intelligibility and binaural-cue preservation than the SCO method. Howe ver , the SDCR method does not guarantee user-controlled upper bounded ITF error when the RA TF vectors of the interferers are estimated accurately enough. This problem is solved by the second proposed method, which is a hybrid combination of the SDCR and SCO methods. This method guarantees user - controlled upper-bounded ITF error, and at the same time is computationally much less demanding than the SCO method. Finally , listening tests sho wed that all three methods achiev e the same localization errors for the same amount of relaxation. R E F E R E N C E S [1] S. Doclo, W . Kellermann, S. Makino, and S. Nordholm, “Multichannel signal enhancement algorithms for assisted listening devices, ” IEEE Signal Process. Mag. , v ol. 32, no. 2, pp. 18–30, Mar. 2015. [2] J. M. Kates, Digital hearing aids . Plural publishing, 2008. T ABLE I: T -test: + denotes significantly different (i.e., the null hypothesis is rejected at 5% significance level), while ◦ denotes not significantly different. Method BMVDR SCO c = 0 . 3 SCO c = 0 . 7 SDCR c = 0 . 3 SDCR c = 0 . 7 Hybrid c = 0 . 3 Hybrid c = 0 . 7 BMVDR ◦ + + + + + + SCO c = 0 . 3 + ◦ + ◦ + ◦ + SCO c = 0 . 7 + + ◦ + ◦ + ◦ SDCR c = 0 . 3 + ◦ + ◦ + ◦ + SDCR c = 0 . 7 + + ◦ + ◦ + ◦ Hybrid c = 0 . 3 + ◦ + ◦ + ◦ + Hybrid c = 0 . 7 + + ◦ + ◦ + ◦ Unpro- cessed + ◦ + ◦ + ◦ + [3] E. Hadad, D. Marquardt, S. Doclo, and S. Gannot, “Theoretical analysis of binaural transfer function MVDR beamformers with interference cue preserv ation constraints, ” IEEE T rans. Audio, Speech, Language Pr ocess. , vol. 23, no. 12, pp. 2449–2464, Dec. 2015. [4] A. W . Bronkhorst, “The cocktail party phenomenon: A revie w of research on speech intelligibility in multiple-talker conditions, ” Acta Acoustica , vol. 86, no. 1, pp. 117–128, 2000. [5] D. Marquardt, “Dev elopment and ev aluation of psychoacoustically mo- tiv ated binaural noise reduction and cue preservation techniques, ” Ph.D. dissertation, Carl von Ossietzky Uni versit ¨ at Oldenburg, 2015. [6] A. I. Koutrouv elis, R. C. Hendriks, R. Heusdens, S. van de Par, J. Jensen, and M. Guo, “Evaluation of binaural noise reduction methods in terms of intelligibility and perceived localization, ” in submitted to EUSIPCO , 2018. [7] J. G. Desloge, W . M. Rabino witz, and P . M. Zurek, “Microphone-array hearing aids with binaural output .I. Fixed-processing systems, ” IEEE T rans. Speech Audio Pr ocess. , vol. 5, no. 6, pp. 529–542, Nov . 1997. [8] D. P . W elker , J. E. Greenberg, J. G. Desloge, and P . M. Zurek, “Microphone-array hearing aids with binaural output .II. A two- microphone adaptiv e system, ” IEEE T rans. Speech Audio Process. , vol. 5, no. 6, pp. 543–551, Nov . 1997. [9] T . Klasen, T . V an den Bogaert, M. Moonen, and J. W outers, “Binaural noise reduction algorithms for hearing aids that preserve interaural time delay cues, ” IEEE T rans. Signal Pr ocess. , vol. 55, no. 4, pp. 1579–1585, Apr . 2007. [10] A. I. Koutrouv elis, R. C. Hendriks, J. Jensen, and R. Heusdens, “Im- proved multi-microphone noise reduction preserving binaural cues, ” in IEEE Int. Conf. Acoust., Speech, Signal Pr ocess. (ICASSP) , Mar. 2016. [11] E. Hadad, S. Doclo, and S. Gannot, “The binaural LCMV beamformer and its performance analysis, ” IEEE T rans. Audio, Speec h, Language Pr ocess. , vol. 24, no. 3, pp. 543–558, Jan. 2016. [12] A. I. Koutrouvelis, R. C. Hendriks, R. Heusdens, and J. Jensen, “Relaxed binaural LCMV beamforming, ” IEEE Tr ans. Audio, Speech, Language Pr ocess. , vol. 25, no. 1, pp. 137–152, Jan. 2017. [13] B. Cornelis, S. Doclo, T . V an den Bogaert, M. Moonen, and J. W outers, “Theoretical analysis of binaural multimicrophone noise reduction tech- niques, ” IEEE T rans. Audio, Speech, Languag e Pr ocess. , vol. 18, no. 2, pp. 342–355, Feb . 2010. [14] S. Gannot, E. Vincet, S. Markovich-Golan, and A. Ozerov , “ A consoli- dated perspecti ve on multi-microphone speech enhancement and source separation, ” IEEE T rans. Audio, Speech, Language Process. , vol. 25, no. 4, pp. 692–730, April 2017. [15] A. I. Koutrouvelis, R. C. Hendriks, R. Heusdens, J. Jensen, and M. Guo, “Binaural beamforming using pre-determined relative acoustic transfer functions, ” in EURASIP Europ. Signal Process. Conf. (EUSIPCO) , Aug. 2017. [16] H. Anton, Elementary linear algebra . John Wile y & Sons, 2010. [17] S. Boyd and L. V andenberghe, Con vex optimization . Cambridge univ ersity press, 2004. 10 [18] G. Golub and C. V . Loan, Matrix Computations , 3rd ed. Oxford: North Oxford Academic, 1983. [19] L. V andenberghe and S. Boyd, “Semidefinite programming, ” SIAM r eview , vol. 38, no. 1, pp. 49–95, Mar . 1996. [20] “Cvx: Matlab software for disciplined conv ex programming. ” 2008. [21] H. Kayser, S. Ewert, J. Annemuller , T . Rohdenburg, V . Hohmann, and B. Kollmeier , “Database of multichannel in-ear and behind-the-ear head- related and binaural room impulse responses, ” EURASIP J. Advances Signal Process. , vol. 2009, pp. 1–10, Dec. 2009. [22] J. B. Allen, “Short-term spectral analysis, and modification by dis- crete Fourier transform, ” IEEE T rans. Acoust., Speech, Signal Pr ocess. , vol. 25, no. 3, pp. 235–238, June 1977. [23] C. H. T aal, R. C. Hendriks, R. Heusdens, and J. Jensen, “ An algorithm for intelligibility prediction of time-frequency weighted noisy speech, ” IEEE T rans. Audio, Speech, Language Process. , v ol. 19, no. 7, pp. 2125– 2136, Sep. 2011. [24] W . M. Hartmann, “How we localize sound, ” Physics T oday , vol. 52, no. 11, pp. 24–29, Nov . 1999.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment