Autoencoders for music sound modeling: a comparison of linear, shallow, deep, recurrent and variational models
This study investigates the use of non-linear unsupervised dimensionality reduction techniques to compress a music dataset into a low-dimensional representation which can be used in turn for the synthesis of new sounds. We systematically compare (sha…
Authors: Fanny Roche (1, 2), Thomas Hueber (1)
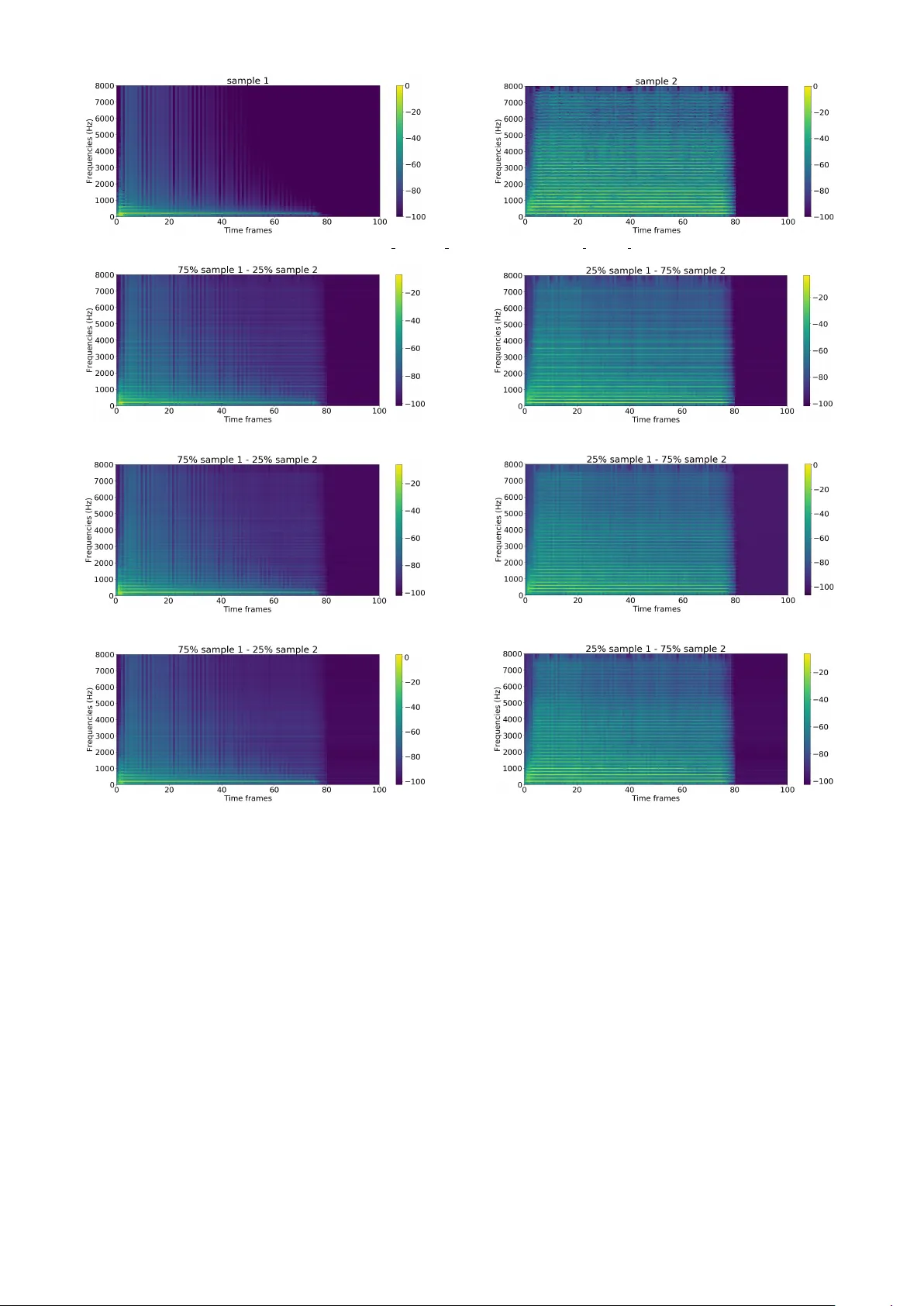
A utoencoders f or music sound modeling: a comparison of linear , shallow , deep, r ecurrent and v ariational models Fanny Roche 1,3 Thomas Hueber 3 Samuel Limier 1 Laurent Girin 2,3 1 Arturia, Meylan, France 2 Inria Grenoble Rh ˆ one-Alpes, France 3 Univ . Grenoble Alpes, CNRS, Grenoble INP , GIPSA-lab, Grenoble, France fanny.roche@gipsa-lab.fr ABSTRA CT This study inv estigates the use of non-linear unsupervised dimensionality reduction techniques to compress a music dataset into a low-dimensional representation which can be used in turn for the synthesis of new sounds. W e systemati- cally compare (shallo w) autoencoders (AEs), deep autoen- coders (D AEs), recurrent autoencoders (with Long Short- T erm Memory cells – LSTM-AEs) and v ariational autoen- coders (V AEs) with principal component analysis (PCA) for representing the high-resolution short-term magnitude spectrum of a large and dense dataset of music notes into a lower-dimensional vector (and then con vert it back to a magnitude spectrum used for sound resynthesis). Our ex- periments were conducted on the publicly available multi- instrument and multi-pitch database NSynth. Interestingly and contrary to the recent literature on image processing, we can show that PCA systematically outperforms shal- low AE. Only deep and recurrent architectures (D AEs and LSTM-AEs) lead to a lower reconstruction error . The op- timization criterion in V AEs being the sum of the recon- struction error and a regularization term, it naturally leads to a lo wer reconstruction accurac y than D AEs b ut we sho w that V AEs are still able to outperform PCA while provid- ing a low-dimensional latent space with nice “usability” properties. W e also pro vide corresponding objective mea- sures of perceptual audio quality (PEMO-Q scores), which generally correlate well with the reconstruction error . 1. INTR ODUCTION Deep neural networks, and in particular those trained in an unsupervised (or self-supervised) way such as autoen- coders [1] or GANs [2], have sho wn nice properties to ex- tract latent representations from large and complex datasets. Such latent representations can be sampled to generate new data. These types of models are currently widely used for image and video generation [3–5]. In the context of a project aiming at designing a music sound synthesizer driv en by high-level control parameters and propelled by data-driv en machine learning, we inv estigate the use of such techniques for music sound generation as an alter- nativ e to classical music sound synthesis techniques like Copyright: c 2019 Roche et al. This is an open-access article distrib uted under the terms of the Creative Commons Attrib ution 3.0 Unported License , which per- mits unrestricted use, distribution, and repr oduction in any medium, provided the original author and sour ce ar e cr edited. additiv e synthesis, subtractiv e synthesis, frequency modu- lation, wa vetable synthesis or physical modeling [6]. So far , only a few studies in audio processing have been proposed in this line, with a general principle that is sim- ilar to image synthesis/transformation: projection of the signal space into a lo w-dimensional latent space (encoding or embedding), modification of the latent coef ficients, and in verse transformation of the modified latent coefficients into the original signal space (decoding). In [7, 8], the authors implemented this principle with au- toencoders to process normalized magnitude spectra. An autoencoder (AE) is a specific type of artificial neural net- work (ANN) architecture which is trained to reconstruct the input at the output layer , after passing through the la- tent space. Evaluation was made by computing the mean squared error (MSE) between the original and the recon- structed magnitude spectra. In [9], NSynth, an audio synthesis method based on a time-domain autoencoder inspired from the W av eNet speech synthesizer [10] was proposed. The authors in vestigated the use of this model to find a high-le vel latent space well- suited for interpolation between instruments. Their au- toencoder is conditioned on pitch and is fed with raw au- dio from their large-scale multi-instrument and multi-pitch database (the NSynth dataset). This approach led to promis- ing results but has a high computational cost. Another technique to synthesize data using deep learning is the so-called v ariational autoencoder (V AE) originally proposed in [11], which is no w popular for image gener- ation. A V AE can be seen as a probabilistic/generati ve version of an AE. Importantly , in a V AE, a prior can be placed on the distribution of the latent v ariables, so that they are well suited for the control of the generation of ne w data. This has been recently e xploited for the modeling and transformation of speech signals [12, 13] and also for mu- sic sounds synthesis [14], incorporating some fitting of the latent space with a perceptual timbre space. V AEs hav e also been recently used for speech enhancement [15–17]. In line with the above-presented studies, the goal of the present paper is i) to provide an extensiv e comparison of sev eral autoencoder architectures including shallow , deep, recurrent and v ariational autoencoders, with a systematic comparison to a linear dimensionality reduction technique, in the present case Principal Component Analysis (PCA) (to the best of our kno wledge, such comparison of non- linear approaches with a linear one has never been done in pre vious studies). This is done using both an objec- Figure 1: Global diagram of the sound analysis-transformation-synthesis process. tiv e physical measure (root mean squared error – RMSE) and an objectiv e perceptual measure (PEMO-Q [18]); ii) to compare the properties of the latent space in terms of correlation between the extracted dimensions; and iii) to illustrate how interpolation in the latent space can be per- formed to create interesting hybrid sounds. 2. METHODOLOGY The global methodology applied for (V)AE-based analysis- transformation-synthesis of audio signals in this study is in line with previous works [7, 8, 12, 13]. It is illustrated in Fig. 1 and is described in the next subsections. 2.1 Analysis-Synthesis First, a Short-T erm Fourier Transform (STFT) analysis is performed on the input audio signal. The magnitude spec- tra are sent to the model (encoder input) on a frame-by- frame basis, and the phase spectra are stored for the syn- thesis stage. After possible modifications of the extracted latent v ariables (at the bottleneck layer output, see next subsection), the output magnitude spectra is provided by the decoder . The output audio signal is synthesized by combining the decoded magnitude spectra with the phase spectra, and by applying in verse STFT with overlap-add. If the latent coefficients are not modified in between en- coding and decoding, the decoded magnitude spectra are close to the original ones and the original phase spectra can be directly used for good quality wa veform reconstruc- tion. If the latent coefficients are modified so that the de- coded magnitude spectra become different from the origi- nal one, then the Griffin & Lim algorithm [19] is used to estimate/refine the phase spectra (the original phase spec- tra are used for initialization) and finally reconstruct the time-domain signal. A few more technical details regard- ing data pre-processing are giv en in Section 3.2. 2.2 Dimensionality Reduction T echniques Principal Component Analysis : As a baseline, we inv es- tigated the use of PCA to reduce the dimensionality of the input v ector x . PCA is the optimal linear orthogonal trans- formation that provides a new coordinate system (i.e. the latent space) in which basis vectors follo w modes of great- est variance in the original data [20]. A utoencoder : An AE is a specific kind of ANN tradition- ally used for dimensionality reduction thanks to its diabolo shape [21], see Fig. 2. It is composed of an encoder and a decoder . The encoder maps a high-dimensional low-le vel input vector x into a low-dimensional higher-le vel latent vector z , which is assumed to nicely encode properties or attributes of x . Similarly , the decoder reconstructs an esti- mate ˆ x of the input vector x from the latent vector z . The model is written as: z = f enc ( W enc x + b enc ) and ˆ x = f dec ( W dec z + b dec ) , where f enc and f dec are (entry-wise) non-linear activ ation functions, W enc and W dec are weight matrices and b enc and b dec are bias vectors. For regression tasks (such as the one considered in this study), a linear activ ation function is generally used for the output layer . At training time, the weight matrices and the bias vec- tors are learned by minimizing some cost function ov er a training dataset. Here we consider the mean squared error (MSE) between the input x and the output ˆ x . The model can be extended by adding hidden layers in both the encoder and decoder to create a so-called deep autoencoder (D AE), as illustrated in Fig. 2. This kind of architecture can be trained globally (end-to-end) or layer- by-layer by considering the D AE as a stack of shallow AEs [1, 22]. Figure 2: General architecture of a (deep) autoencoder . LSTM A utoencoder : In a general manner , a recurrent neural network (RNN) is an ANN where the output of a giv en hidden layer does not depend only on the output of the pre vious layer (as in a feedforward architecture) b ut also on the internal state of the netw ork. Such internal state can be defined as the output of each hidden neuron when processing the previous input observations. They are thus well-suited to process time series of data and capture their time dependencies. Such networks are here expected to ex- tract latent representations that encode some aspects of the sound dynamics. Among different existing RNN architec- tures, in this study we used the Long Short-T erm Memory (LSTM) network [23], which is kno wn to tackle correctly the so-called v anishing gradient problem in RNNs [24]. The structure of the model depicted in Fig. 2 still holds while replacing the classical neuronal cells by LSTM cells, leading to a LSTM-AE. The cost function to optimize re- mains the same, i.e. the MSE between the input x and the output ˆ x . Howe ver , the model is much more complex and has more parameters to train [23]. V ariational A utoencoder : A V AE can be seen as a prob- abilistic AE which delivers a parametric model of the data distribution, such as: p θ ( x , z ) = p θ ( x | z ) p θ ( z ) , where θ denotes the set of distrib ution parameters. In the present context, the likelihood function p θ ( x | z ) plays the role of a probabilistic decoder which models how the gen- eration of observed data x is conditioned on the latent data z . The prior distribution p θ ( z ) is used to structure (or re gu- larize) the latent space. T ypically a standard Gaussian dis- tribution p θ ( z ) = N ( z ; 0 , I ) is used, where I is the identity matrix [11]. This encourages the latent coefficients to be mutually orthogonal and lie on a similar range. Such prop- erties may be of potential interest for using the extracted latent coefficients as control parameters of a music sound generator . The likelihood p θ ( x | z ) is defined as a Gaussian density: p θ ( x | z ) = N ( x ; µ θ ( z ) , σ 2 θ ( z )) , where µ θ ( z ) and σ 2 θ ( z ) are the outputs of the decoder net- work (hence θ = { W dec , b dec } ). Note that σ 2 θ ( z ) indif- ferently denotes the cov ariance matrix of the distribution, which is assumed diagonal, or the vector of its diagonal entries. The exact posterior distribution p θ ( z | x ) corresponding to the abov e model is intractable. It is approximated with a tractable parametric model q φ ( z | x ) that will play the role of the corresponding probabilistic encoder . This model generally has a form similar to the decoder: q φ ( z | x ) = N ( z ; ˜ µ φ ( x ) , ˜ σ 2 φ ( x )) , where ˜ µ φ ( x ) and ˜ σ 2 φ ( x ) are the outputs of the encoder ANN (the parameter set φ is composed of W enc and b enc ; ˜ σ 2 φ ( x ) is a diagonal cov ariance matrix or is the vector of its diagonal entries). T raining of the V AE model, i.e. estimation of θ and φ , is done by maximizing the mar ginal log-likelihood log p θ ( x ) ov er a large training dataset of vectors x . It can be shown that the marginal log-lik elihood can be written as [11]: log p θ ( x ) = D KL ( q φ ( z | x ) | p θ ( z | x )) + L ( φ, θ , x ) , where D KL ≥ 0 denotes the Kullback-Leibler div ergence (KLD) and L ( φ, θ , x ) is the variational lower bound (VLB) giv en by: L ( φ, θ , x ) = − D KL ( q φ ( z | x ) | p θ ( z )) | {z } regularization + E q φ ( z | x ) [ log p θ ( x | z )] | {z } reconstruction accuracy . (1) In practice, the model is trained by maximizing L ( φ, θ , x ) ov er the training dataset with respect to parameters φ and θ . W e can see that the VLB is the sum of two terms. The first term acts as a re gularizer encouraging the approximate posterior q φ ( z | x ) to be close to the prior p θ ( z ) . The second term represents the a verage reconstruction accurac y . Since the expectation w .r .t. q φ ( z | x ) is difficult to compute ana- lytically , it is approximated using a Monte Carlo estimate and samples drawn from q φ ( z | x ) . For other technical de- tails that are not relev ant here, the reader is referred to [11]. As discussed in [12] and [25], a weighting factor , denoted β , can be introduced in (1) to balance the re gularization and reconstruction terms: L ( φ, θ , β , x ) = − β D KL ( q φ ( z | x ) | p θ ( z )) + E q φ ( z | x ) [ log p θ ( x | z )] , (2) This enables the user to better control the trade-of f between output signal quality and compactness/orthogonality of the latent coefficients z . Indeed, if the reconstruction term is too strong relati vely to the regularization term, then the dis- tribution of the latent space will be poorly constrained by the prior p θ ( z ) , turning the V AE into an AE. Conv ersely , if it is too weak, then the model may focus too much on con- straining the latent coef ficients to follo w the prior distrib u- tion while providing poor signal reconstruction [25]. In the present work we used this type of β -V AE and we present the results obtained with dif ferent v alues of β . These latter were selected manually after pilot experiments to ensure that the values of the regularization and the reconstruction accuracy terms in (2) are in the same range. 3. EXPERIMENTS 3.1 Dataset In this study , we used the NSynth dataset introduced in [9]. This is a large database (more than 30 GB) of 4s long monophonic music sounds sampled at 16 kHz. They rep- resent 1 , 006 different instruments generating notes with different pitches (from MIDI 21 to 108) and different ve- locities (5 dif ferent lev els from 25 to 127). T o generate these samples dif ferent methods were used: Some acoustic and electronic instruments were recorded and some oth- ers were synthesized. The dataset is labeled with: i) in- strument family (e.g., keyboard, guitar , synth lead, reed), ii) source (acoustic, electronic or synthetic), iii) instrument index within the instrument family , i v) pitch value, and v) velocity value. Some other labels qualitativ ely describe the samples, e.g. brightness or distortion, b ut the y were not used in our work. T o train our models, we used a subset of 10 , 000 dif ferent sounds randomly chosen from this NSynth database, rep- resenting all families of instruments, dif ferent pitches and different v elocities. W e split this dataset into a training set (80%) and testing set (20%). During the training phase, 20% of the training set was kept for v alidation. In or - der to hav e a statistically robust e v aluation, a k -fold cross- validation procedure with k = 5 was used to train and test all different models (we divided the dataset into 5 folds, used 4 of them for training and the remaining one for test, and repeated this procedure 5 times so that each sound of the initial dataset was used once for testing). 3.2 Data Pre-Processing For magnitude and phase short-term spectra extraction, we applied a 1 , 024 -point STFT to the input signal using a slid- ing Hamming window with 50 % overlap. Frames corre- sponding to silence segments were removed. The corre- sponding 513 -point positive-frequenc y magnitude spectra were then conv erted to log-scale and normalized in energy: W e fixed the maximum of each log-spectrum input vector to 0 dB (the energy coefficient was stored to be used for signal reconstruction). Then, the log-spectra were thresh- olded, i.e. ev ery log-magnitude below a fixed threshold was set to the threshold value. Finally they were normal- ized between − 1 and 1 , which is a usual procedure for ANN inputs. Three threshold values were tested: − 80 dB, − 90 dB and − 100 dB. Corresponding denormalization, log-to-linear con version and energy equalization were ap- plied after the decoder , before signal reconstruction with transmitted phases and in verse STFT with o verlap-add. 3.3 A utoencoder Implementations W e tried different types of autoencoders: AE, DAE, LSTM- AE and V AE. For all the models we in vestigated se veral values for the encoding dimension, i.e. the size of the bot- tleneck layer / latent variable vector , from enc = 4 to 100 (with a fine-grained sampling for enc ≤ 16 ). Dif ferent ar- chitectures were tested for the D AEs: [513, 128, enc , 128, 513], [513, 256, enc , 256, 513] and [513, 256, 128, enc , 128, 256, 513]. Concerning the LSTM-AE, our imple- mentation used two vanilla forward LSTM layers (one for the encoder and one for the decoder) with non-linear ac- tiv ation functions giving the follo wing architecture: [513, enc , 513]. Both LSTM layers were designed for many-to- many sequence learning, meaning that a sequence of in- puts, i.e. of spectral magnitude vectors, is encoded into a sequence of latent vectors of same temporal size and then decoded back to a sequence of reconstructed spectral mag- nitude vectors. The architecture we used for the V AE was [513, 128, enc , 128, 513] and we tested dif ferent v alues of the weight factor β . For all the neural models, we tested different pairs of activ ation functions for the hidden lay- ers and output layer , respectiv ely: (tanh, linear), (sigmoid, linear) and (tanh, sigmoid). AE, D AE, LSTM-AE and V AE models were implemented using the Ker as toolkit [26] (we used the scikit-learn [27] toolkit for the PCA). Training w as performed using the Adam optimizer [28] with a learning rate of 10 − 3 ov er 600 epochs with early stopping criterion (with a patience of 30 epochs) and a batch size of 512 . The D AEs were trained in two dif ferent ways, with and without layer -wise training. 3.4 Experimental Results for Analysis-Resynthesis Fig. 3 sho ws the reconstruction error (RMSE in dB) ob- tained with PCA, AE, D AE and LSTM-AE models on the test set (a veraged over the 5 folds of the cross-validation procedure), as a function of the dimension of the latent space. The results obtained with the V AE (using the same protocol, and for different β v alues) are shown in Fig. 4. For the sake of clarity , we present here only the results obtained for i) a threshold of − 100 dB applied on the log- spectra, and ii) a restricted set of the tested AE, D AE and V AE architectures (listed in the legends of the figures). Similar trends were observed for other thresholds and other tested architectures. For each considered dimension of the latent space, a 95% confidence interv al of each reconstruc- tion error was obtained by conducting paired t-test, consid- ering each sound (i.e. each audio file) of the test set as an independent sample. RMSE provides a global measure of magnitude spectra reconstruction but can be insufficiently correlated to per- ception depending on which spectral components are cor- rectly or poorly reconstructed. T o address this classical is- sue in audio processing, we also calculated objectiv e mea- sures of perceptual audio quality , namely PEMO-Q scores [18]. The results are reported in Fig. 5 and Fig. 6. As expected, the RMSE decreases with the dimension of the latent space for all methods. Interestingly , PCA sys- tematically outperforms (or at worst equals) shallow AE. This somehow contradicts recent studies on image com- pression for which a better reconstruction is obtained with AE compared to PCA [1]. T o confirm this unexpected result, we replicated our PCA vs. AE experiment on the MNIST image dataset [29], using the same AE implemen- tation and a standard image preprocessing (i.e. vectoriza- tion of each 28 × 28 pixels gray-scale image into a 784 - dimensional feature vector). In accordance with the lit- erature, the best performance was systematically obtained with AE (for an y considered dimension of the latent space). This difference of AE’ s behavior when considering audio and image data was unexpected and, to our knowledge, it has nev er been reported in the literature. Then, contrary to (shallo w) AE, D AEs systematically out- perform PCA (and thus AE), with up to almost 20% im- prov ement (for enc = 12 and enc = 16 ). Our e xperiments did not rev eal notable benefit of layer-by-layer D AE train- ing ov er end-to-end training. Importantly , for small di- mensions of the latent space (e.g. smaller than 16), RMSE obtained with D AE decreases much faster than with PCA and AE. This is e ven more the case for LSTM-AE which shows an impro vement of the reconstruction error of more than 23% ov er PCA (for enc = 12 and enc = 16 ). These results confirm the benefits of using a more complex ar- chitecture than shallow AE, here deep or recurrent, to effi- ciently extract high-level abstractions and compress the au- dio space. This is of great interest for sound synthesis for which the latent space has to be kept as lo w-dimensional as possible (while maintaining a good reconstruction accu- racy) in order to be “controlled” by a musician. Fig. 4 shows that the ov erall performance of V AEs is in between the performance of D AEs (ev en equals D AEs for lower encoding dimensions, say smaller than 12) and the performances of PCA and AE. Let us recall that minimiz- ing the reconstruction accuracy is not the only goal of V AE which also aims at constraining the distribution of the la- tent space. As sho wn in Fig. 4, the parameter β , which balances regularization and reconstruction accurac y in (2), plays a major role. As e xpected, high β values foster re gu- larization at the expense of reconstruction accuracy . How- ev er , with β 6 2 . 10 − 6 the V AE clearly outperforms PCA, e.g. up to 20% for enc = 12 . It can be noticed that when the encoding dimension is high ( enc = 100 ), PCA seems to outperform all the other models. Hence, in that case, the simpler (linear model) Figure 3: Reconstruction error (RMSE in dB) obtained with PCA, AE, D AE (with and without layer-wise training) and LSTM-AE, as a function of latent space dimension. Figure 4: Reconstruction error (RMSE in dB) obtained with V AEs as a function of latent space dimension (RMSE obtained with PCA is also recalled). seems to be the best (we can conjecture that achie ving the same le vel of performance with autoencoders would re- quire more training data, since the number of free parame- ters of these model increases drastically). Howe ver , using such high-dimensional latent space as control parameters of a music sound generator is impractical. Similar conclusions can be drawn from Fig. 5 and Fig. 6 in terms of audio quality . Indeed, in a general manner, the PEMO-Q scores are well correlated with RMSE mea- sures in our experiments. PEMO-Q measures for PCA and AE are very close, but PCA still slightly outperforms the shallow AE. The D AEs and the V AEs both outperform the PCA (up to about 11% for enc = 12 and enc = 16 ) with the audio quality provided by the D AEs being a little bet- ter than for the V AEs. Surprisingly , and contrary to RMSE scores, the LSTM-AE led to a (slightly) lo wer PEMO-Q scores, for all considered latent dimensions. Further in- vestigations will be done to assess the relev ance of such differences at the perceptual le vel. 3.5 Decorrelation of the Latent Dimensions Now we report further analyses aiming at in vestigating how the extracted latent dimensions may be used as contr ol pa- rameters by the musician. In the present sound synthe- sis frame work, such control parameters are e xpected to re- spect (at least) the following two constraints i) to be as decorrelated as possible in order to limit the redundancy in the spectrum encoding, ii) to hav e a clear and easy-to- understand perceptual meaning. In the present study , we focus on the first constraint by comparing PCA, D AEs, LSTM-AE and V AEs in terms of correlation of the latent dimensions. More specifically , the absolute v alues of the correlation coefficient matrices of the latent vector z were computed on each sound from the test dataset and Fig. 7 reports the mean v alues averaged over all the sounds of the test dataset. For the sake of clarity , we present here these results only for a latent space of dimension 16 for one model of D AE ([513, 128, 16, 128, 513] (tanh & lin) with end-to-end training) and for V AEs with the same architec- ture ([513, 128, 16, 128, 513] (tanh & lin)) and different values of β (from 1 . 10 − 6 to 2 . 10 − 5 ). As could be expected from the complexity of its structure, we can see that the LSTM-AE extracts a latent space where the dimensions are significantly correlated with each other . Such additional correlations may come from the sound dy- namics which provide redundancy in the prediction. W e can also see that PCA and V AEs present similar behaviors with much less correlation of the latent dimensions, which is an implicit property of these models. Interestingly , and in accordance with (2), we can notice that the higher the β , the more regularized the V AE and hence the more decor- related the latent dimensions. Importantly , Fig. 7 clearly shows that for a well-chosen β v alue, the V AE can both extract latent dimensions that are much less correlated than for corresponding DAEs, which mak es it a better candidate for e xtracting good control parameters, while allo wing fair to good reconstruction accuracy (see Fig. 4). The β v alue has thus to be chosen wisely in order to find the optimal trade-off between decorrelation of the latent dimensions and reconstruction accuracy . 3.6 Examples of Sound Interpolation As a first step towards the practical use of the extracted latent space for navig ating through the sound space and creating ne w sounds, we illustrate how it can be used to interpolate between sounds, in the spirit of what was done for instrument hybridization in [9]. W e selected a series of pairs of sounds from the NSynth dataset with the two sounds in a pair having different characteristics. For each pair , we proceeded to separate encoding, entry-wise lin- ear interpolation of the two resulting latent vectors, decod- ing, and finally indi vidual signal reconstruction with in- verse STFT and the Griffin and Lim algorithm to recon- struct the phase spectrogram [19]. W e experimented dif- Figure 5: PEMO-Q measures obtained with PCA, AE, D AEs (with and without layer-wise training) and LSTM- AE, as a function of latent space dimension. Figure 6: PEMO-Q measures obtained with V AEs as a function of latent space dimension (measures obtained with PCA are also recalled). Figure 7: Correlation matrices of the latent dimensions (av erage absolute correlation coefficients) for PCA, D AE, LSTM-AE and V AEs. ferent degrees of interpolation between the two sounds: ˆ z = α z 1 + (1 − α ) z 2 , with z i the latent vector of sound i , ˆ z the ne w interpolated latent vector , and α ∈ [0 , 0 . 25 , 0 . 5 , 0 . 75 , 1] (this interpolation is processed inde- pendently on each pair of vectors of the time sequence). The same process was applied using the different AE mod- els we introduced earlier . Fig. 8 displays one example of results obtained with PCA, with the LSTM-AE and with the V AE (with β = 1 . 10 − 6 ), with an encoding dimension of 32 . Qualitatively , we note that interpolations in the latent space lead to a smooth tran- sition between source and target sound. By increasing se- quentially the degree of interpolation, we can clearly go from one sound to another in a consistent manner , and cre- ate interesting hybrid sounds. The results obtained using PCA interpolation are (again qualitati vely) belo w the qual- ity of the other models. The example spectrogram obtained with interpolated PCA coef ficients is blurrier around the harmonics and some audible artifacts appear . On the oppo- site, the LSTM-AE seems to outperform the other models by better preserving the note attacks (see comparison with V AE in Fig. 8). More interpolation examples along with corresponding audio samples can be found at https:// goo.gl/Tvvb9e . 4. CONCLUSIONS AND PERSPECTIVES In this study , we inv estigated dimensionality reduction based on autoencoders to extract latent dimensions from a large music sound dataset. Our goal is to provide a musician with a new way to generate sound textures by exploring a low-dimensional space. From the experiments conducted on a subset of the publicly available database NSynth, we can draw the following conclusions: i) Contrary to the lit- erature on image processing, shallo w autoencoders (AEs) do not here outperform principal component analysis (in terms of reconstruction accurac y); ii) The best performance in terms of signal reconstruction is always obtained with deep or recurrent autoencoders (D AEs or LSTM-AE); iii) V ariational autoencoders (V AEs) lead to a fair-to-good re- construction accuracy while constraining the statistical prop- erties of the latent space, ensuring some amount of decor- relation across latent coefficients and limiting their range. These latter properties make the V AEs good candidates for our targeted sound synthesis application. In line with the last conclusion, future works will mainly focus on V AEs. First, we will in vestigate recurrent archi- tecture for V AE such as the one proposed in [30]. Such ap- proach may lead to latent dimensions encoding separately the sound texture and its dynamics, which may be of po- tential interest for the musician. Then, we will address the crucial question of the percep- tual meaning/relev ance of the latent dimensions. Indeed using a non-informativ e prior distribution of z such as a standard normal distribution does not ensure that each di- mension of z represents an interesting perceptual dimen- sion of the sound space, although this is a desirable objec- (a) Original samples - Left : bass electronic 010-055-100, Right : brass acoustic 050-055-100 (b) PCA (c) LSTM-AE (d) V AE Figure 8: Examples of decoded magnitude spectrograms after sound interpolation of 2 samples (top) in the latent space using respectively PCA (2nd ro w), LSTM-AE (3rd row) and V AE (bottom). A more detailed version of the figure can be found at https://goo.gl/Tvvb9e . tiv e. In [14], the authors recently proposed a first solution to this issue in the conte xt of a restricted set of acoustic in- struments. They introduced in the variational lower bound (2) of the V AE loss an additional regularization term en- couraging the latent space to respect the structure of the instrument timbre. In the same spirit, our future works will in vestigate different strategies to model the complex rela- tionships between sound te xtures and their perception, and introduce these models at the V AE latent space level. 5. A CKNO WLEDGMENT The authors would like to thank Simon Leglaiv e for our fruitful discussions. This w ork was supported by ANR T in the framew ork of the PhD program CIFRE 2016/0942. 6. REFERENCES [1] G. Hinton and R. Salakhutdinov , “Reducing the dimen- sionality of data with neural networks, ” Science , v ol. 313, no. 5786, pp. 504–507, 2006. [2] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farley , S. Ozair , A. Courville, and Y . Ben- gio, “Generati ve adversarial nets, ” in Advances in Neu- ral Information Pr ocess. Systems , Montreal, Canada, 2014. [3] S. Reed, Z. Akata, X. Y an, L. Logeswaran, B. Schiele, and H. Lee, “Generative adv ersarial text to image syn- thesis, ” in Pr oc. of the Int. Conf. on Mac hine Learning , New Y ork, NY , 2016. [4] S. Mehri, K. Kumar , I. Gulrajani, R. Kumar , S. Jain, J. Sotelo, A. Courville, and Y . Bengio, “SampleRNN: An unconditional end-to-end neural audio generation model. ” in Int. Conf. on Learning Repr esentations , 2017. [5] S. T ulyakov , M.-Y . Liu, X. Y ang, and J. Kautz, “Moco- gan: Decomposing motion and content for video gen- eration, ” in Pr oc. of the IEEE conf. on computer vision and pattern reco gnition , 2018. [6] E. Miranda, Computer Sound Design: Synthesis T ech- niques and Pr ogr amming , ser . Music T echnology se- ries. Focal Press, 2002. [7] A. Sarroff and M. Casey , “Musical audio synthesis us- ing autoencoding neural nets, ” in Joint Int. Computer Music Conf. and Sound and Music Computing Conf. , Athens, Greece, 2014. [8] J. Colonel, C. Curro, and S. Keene, “Improving neural net auto encoders for music synthesis, ” in Audio Engi- neering Society Con vention , New-Y ork, NY , 2017. [9] J. Engel, C. Resnick, A. Roberts, S. Dieleman, D. Eck, K. Simonyan, and M. Norouzi, “Neural audio synthe- sis of musical notes with wa venet autoencoders, ” arXiv pr eprint arXiv:1704.01279 , 2017. [10] A. V an Den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Grav es, N. Kalchbrenner, A. Senior , and K. Ka vukcuoglu, “W av enet: A generativ e model for raw audio, ” arXiv pr eprint arXiv:1609.03499 , 2016. [11] D. P . Kingma and M. W elling, “ Auto-encoding varia- tional bayes, ” arXiv pr eprint arXiv:1312.6114 , 2013. [12] M. Blaauw and J. Bonada, “Modeling and transform- ing speech using variational autoencoders. ” in Conf. of the Int. Speech Comm. Association (Interspeech) , San Francisco, CA, 2016. [13] W .-N. Hsu, Y . Zhang, and J. Glass, “Learning latent representations for speech generation and transforma- tion, ” arXiv pr eprint arXiv:1704.04222 , 2017. [14] P . Esling, A. Chemla-Romeu-Santos, and A. Bitton, “Generativ e timbre spaces with v ariational audio syn- thesis, ” in Pr oc. of the Int. Conf. on Digital Audio Ef- fects 2018 , A veiro, Portugal, 2018. [15] S. Le glai ve, L. Girin, and R. Horaud, “ A v ariance mod- eling framew ork based on variational autoencoders for speech enhancement, ” in IEEE Int. W orkshop on Ma- chine Learning for Signal Pr ocess. , Aalbor g, Denmark, 2018. [16] ——, “Semi-supervised multichannel speech enhance- ment with v ariational autoencoders and non-ne gativ e matrix factorization, ” in IEEE Int. Conf. on Acoustics, Speech and Signal Process. , Brighton, UK, 2019. [17] L. Li, H. Kameoka, and S. Makino, “F ast MV AE: Joint separation and classification of mixed sources based on multichannel variational autoencoder with auxiliary classifier , ” in IEEE Int. Conf. on Acoustics, Speech and Signal Process. , Brighton, UK, 2019. [18] R. Huber and B. K ollmeier , “PEMO-Q: A ne w method for objecti ve audio quality assessment using a model of auditory perception, ” IEEE T ransactions on Audio, Speech, and Language Pr ocess. , vol. 14, no. 6, pp. 1902–1911, 2006. [19] D. Griffin and J. Lim, “Signal estimation from modi- fied short-time fourier transform, ” IEEE T ransactions on Acoustics, Speech, and Signal Pr ocess. , vol. 32, no. 2, pp. 236–243, 1984. [20] C. M. Bishop, P attern reco gnition and machine learn- ing . Springer , 2006. [21] I. Goodfellow , Y . Bengio, and A. Courville, Deep Learning . MIT Press, 2016. [22] Y . Bengio, P . Lamblin, D. Popovici, and H. Larochelle, “Greedy layer-wise training of deep networks, ” in Ad- vances in Neural Information Pr ocess. Systems , V an- couver , Canada, 2007. [23] S. Hochreiter and J. Schmidhuber , “Long short-term memory , ” Neural computation , v ol. 9, no. 8, pp. 1735– 1780, 1997. [24] Y . Bengio, P . Simard, and P . Frasconi, “Learning long- term dependencies with gradient descent is difficult, ” IEEE transactions on neural networks , vol. 5, no. 2, pp. 157–166, 1994. [25] I. Higgins, L. Matthey , A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner , “ β -V AE: learning basic visual concepts with a constrained vari- ational frame work. ” in Int. Conf. on Learning Repr e- sentations , 2017. [26] F . Chollet et al. , “K eras, ” https://keras.io, 2015. [27] F . Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V . Dubourg, J. V anderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duches- nay , “Scikit-learn: Machine learning in Python, ” Jour - nal of machine learning r esear ch , vol. 12, no. Oct, pp. 2825–2830, 2011. [28] D. P . Kingma and J. Ba, “ Adam: A method for stochas- tic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014. [29] Y . LeCun, C. Cortes, and C. Bur ges, “The MNIST database of handwritten digits, ” http://yann.lecun.com/exdb/mnist/, 1998. [30] J. Chung, K. Kastner , L. Dinh, K. Goel, A. C. Courville, and Y . Bengio, “ A recurrent latent variable model for sequential data, ” in Advances in Neural In- formation Process. Systems , 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment