Human Vocal Sentiment Analysis
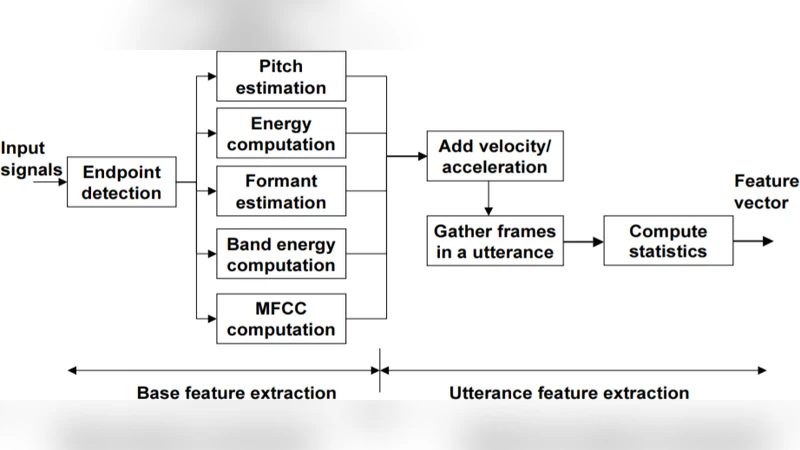
In this paper, we use several techniques with conventional vocal feature extraction (MFCC, STFT), along with deep-learning approaches such as CNN, and also context-level analysis, by providing the textual data, and combining different approaches for improved emotion-level classification. We explore models that have not been tested to gauge the difference in performance and accuracy. We apply hyperparameter sweeps and data augmentation to improve performance. Finally, we see if a real-time approach is feasible, and can be readily integrated into existing systems.
💡 Research Summary
The paper “Human Vocal Sentiment Analysis” investigates the problem of classifying emotions from spoken audio by combining conventional acoustic feature extraction with modern deep‑learning techniques and contextual text information. The authors explore three methodological families: (1) classic feature‑based classification using pitch, MFCC, formants, etc., fed into traditional classifiers such as Support Vector Machines (SVM) and Hidden Markov Models (HMM); (2) segment‑level approaches that treat short audio windows (MFCC, STFT) as inputs to lightweight machine‑learning models like SVM and Extreme Learning Machines (ELM); and (3) deep neural networks (CNN, LSTM) that operate on 2‑D MFCC spectrograms, with experiments also incorporating recent architectural variants such as DropConnect and ResNet.
Two public corpora are used for evaluation: the RAVDESS dataset (1,440 speech‑only samples covering eight emotions) and the TESS dataset (2,800 utterances from two actresses covering seven emotions). Because the focus is on speech, the authors restrict themselves to audio‑only data, normalizing each sample for loudness and length and padding to a uniform size. They adopt a 13‑by‑26 MFCC window as the primary representation, arguing that 13 coefficients capture sufficient spectral information while keeping computational cost low.
Baseline SVM experiments test both radial‑basis‑function (RBF) and linear kernels (C = 10, γ = scale) across a sweep of MFCC counts (10–120). The best SVM configuration (linear kernel with 100 MFCCs) yields only 48.11 % accuracy, confirming that hand‑crafted acoustic features alone struggle with multi‑class emotion discrimination.
The primary deep‑learning model is a modest CNN inspired by AlexNet, consisting of two convolutional blocks (Conv‑2D → MaxPool → Dropout) followed by two fully‑connected layers and a softmax output over eight classes. The network processes the 13 × 26 MFCC matrix directly, using RMSProp (learning rate = 1e‑4, decay = 1e‑6) and categorical cross‑entropy loss. After 500 epochs with a 60/20/20 train/validation/test split, the CNN achieves a Top‑1 accuracy of 85 %, outperforming the SVM baseline and a previously reported three‑layer DNN. The authors also train a 1‑D convolutional variant, which reaches comparable performance, and note that the spatial nature of MFCC spectrograms makes 2‑D convolutions especially effective.
To improve results, the authors conduct hyper‑parameter sweeps, add residual connections, skip connections, and batch‑normalization layers, but observe no further gains. They attribute this to the low variance of the MFCC data: additional depth leads to over‑fitting rather than better generalization. Data augmentation experiments—reversing audio polarity and mixing original with inverted versions—do not improve accuracy, suggesting that MFCCs already discard much of the phase information that image‑style augmentations exploit.
Error analysis via precision, recall, F1‑score, ROC curves, and a confusion matrix reveals that “angry,” “disgust,” and “calm” are the most reliably detected emotions (86.8 %, 78 %, and 72 % respectively), while “neutral,” “calm” (as a separate class), and “happy” suffer from lower recall and precision. The authors hypothesize that these confusions stem from the similarity of spectral patterns for low‑energy, monotone speech, which MFCCs alone cannot disambiguate.
The paper briefly discusses real‑time feasibility, noting that inference speed and memory footprint were not quantitatively measured. For deployment in voice assistants, model compression (e.g., pruning, quantization, lightweight architectures such as MobileNet) and streaming MFCC extraction pipelines would be required.
Future work outlined includes: (i) enriching the feature set with pitch, prosody, and energy descriptors; (ii) employing bidirectional LSTM or Transformer‑based attention mechanisms to capture longer temporal dependencies; (iii) leveraging cross‑modal distillation from pretrained video‑emotion networks to generate pseudo‑labels for audio; and (iv) constructing ensembles of heterogeneous models to improve robustness. The authors also suggest that larger, more diverse datasets and greater computational resources would enable deeper architectures without over‑fitting.
In summary, the study provides a systematic comparison of classic acoustic feature classifiers versus CNN‑based deep learning for vocal emotion recognition. While the CNN achieves promising 85 % accuracy on the RAVDESS corpus, the work highlights persistent challenges: limited variance in MFCC representations, difficulty in distinguishing subtle emotions, modest benefit from data augmentation, and the need for thorough real‑time performance evaluation before practical integration into speech‑enabled systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment