Articulatory and bottleneck features for speaker-independent ASR of dysarthric speech
The rapid population aging has stimulated the development of assistive devices that provide personalized medical support to the needies suffering from various etiologies. One prominent clinical application is a computer-assisted speech training system which enables personalized speech therapy to patients impaired by communicative disorders in the patient’s home environment. Such a system relies on the robust automatic speech recognition (ASR) technology to be able to provide accurate articulation feedback. With the long-term aim of developing off-the-shelf ASR systems that can be incorporated in clinical context without prior speaker information, we compare the ASR performance of speaker-independent bottleneck and articulatory features on dysarthric speech used in conjunction with dedicated neural network-based acoustic models that have been shown to be robust against spectrotemporal deviations. We report ASR performance of these systems on two dysarthric speech datasets of different characteristics to quantify the achieved performance gains. Despite the remaining performance gap between the dysarthric and normal speech, significant improvements have been reported on both datasets using speaker-independent ASR architectures.
💡 Research Summary
The paper addresses a pressing need in the growing field of assistive speech technologies for older adults with neurological disorders such as Parkinson’s disease, stroke, and traumatic brain injury. These conditions often cause dysarthria—a motor speech disorder that severely degrades intelligibility and hampers communication. While computer‑assisted speech‑training systems have shown promise for home‑based therapy, their effectiveness hinges on robust automatic speech recognition (ASR) that can operate without prior knowledge of the speaker’s voice characteristics.
To this end, the authors evaluate two speaker‑independent feature extraction strategies: (1) bottleneck (BN) features derived from a deep neural network with a dedicated bottleneck layer, and (2) continuous articulatory features (AF) that model vocal‑tract kinematics. Both strategies are combined with modern acoustic front‑ends—standard mel‑filterbank (MF) and perceptually motivated gammatone (GT) filterbanks—to assess which acoustic representation best captures the spectral irregularities typical of dysarthric speech.
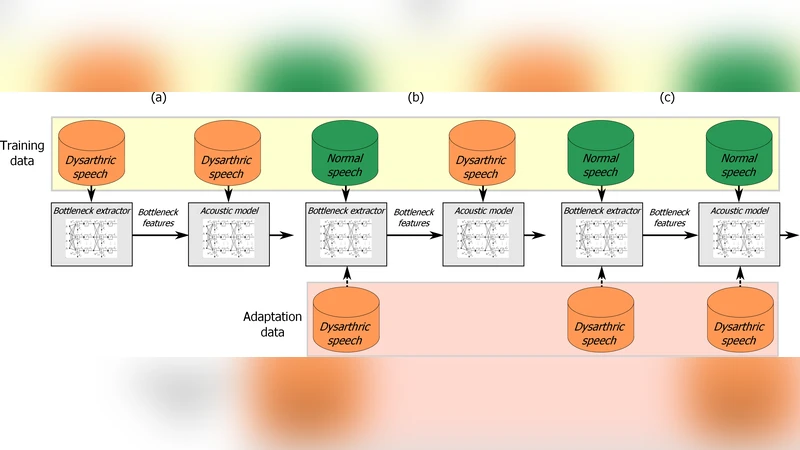
The acoustic models themselves are built on three neural architectures: a conventional DNN‑HMM, a convolutional neural network (CNN)‑HMM, and a novel time‑frequency convolutional neural network (TFCNN). The TFCNN incorporates the bottleneck layer directly into its convolutional stack, enabling joint learning of a compact, speaker‑independent sub‑word representation and the surrounding time‑frequency context. This joint learning is expected to mitigate over‑fitting when training data are scarce—a common situation for pathological speech corpora.
Two dysarthric corpora are used for evaluation. The Dutch EST corpus provides 4 h 47 min of training data from 16 speakers with a range of etiologies (Parkinson’s, cerebrovascular accident, traumatic brain injury, and a birth defect) and varying severity. The CHASING01 corpus supplies an additional 55 min of test material from five speakers recorded across six therapy sessions. For acoustic model pre‑training, large normal‑speech datasets (255 h of Dutch and 186 h of Flemish) are employed, reflecting a low‑resource scenario for the pathological domain.
Key experimental findings include:
- GT vs. MF – Gammatone filterbanks consistently outperform mel‑filterbanks by 0.8–1.5 % absolute reduction in word error rate (WER), confirming that higher spectral resolution better captures dysarthric deviations.
- BN vs. AF – Bottleneck features yield lower WER than the concatenated articulatory features across both corpora, with gains ranging from 1.2 % to 2.5 % absolute. The continuous AFs, however, provide complementary information and improve robustness when fused with GT features.
- Model adaptation – A multi‑stage DNN adaptation procedure (initial training on normal speech, followed by fine‑tuning on dysarthric data, and finally stage‑wise refinement of the bottleneck layer) delivers an additional 5 %–7 % WER reduction for both BN and AF systems.
- TFCNN superiority – The TFCNN architecture, which learns BN representations jointly with convolutional feature maps, achieves the best overall performance, especially when combined with GT‑BN inputs.
The authors enumerate four concrete contributions: (1) a systematic comparison of GT and MF front‑ends for dysarthric ASR, (2) the introduction of continuous articulatory kinematic features derived from both synthetic and real speech inversion models, (3) joint learning of bottleneck layers and feature‑map fusion within a TFCNN framework, and (4) an extensive analysis of multi‑stage model adaptation on both acoustic and bottleneck extraction pipelines.
In discussion, the paper highlights that while the performance gap between dysarthric and healthy speech remains substantial, the proposed speaker‑independent pipelines dramatically narrow this gap without requiring speaker‑specific enrollment data. The results suggest that perceptually grounded filterbanks, physiologically informed articulatory representations, and deep bottleneck embeddings together form a robust foundation for clinical ASR systems.
The study concludes that these techniques can be directly integrated into existing computer‑assisted speech‑therapy platforms—such as the serious game developed within the CHASING project—enabling real‑time, home‑based articulation feedback for patients who cannot regularly attend in‑person therapy. Future work is proposed to explore larger multilingual pathological corpora, end‑to‑end training of speech‑inversion and ASR components, and on‑device deployment to meet privacy and latency requirements in clinical settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment