A 64mW DNN-based Visual Navigation Engine for Autonomous Nano-Drones
Fully-autonomous miniaturized robots (e.g., drones), with artificial intelligence (AI) based visual navigation capabilities are extremely challenging drivers of Internet-of-Things edge intelligence capabilities. Visual navigation based on AI approach…
Authors: Daniele Palossi, Antonio Loquercio, Francesco Conti
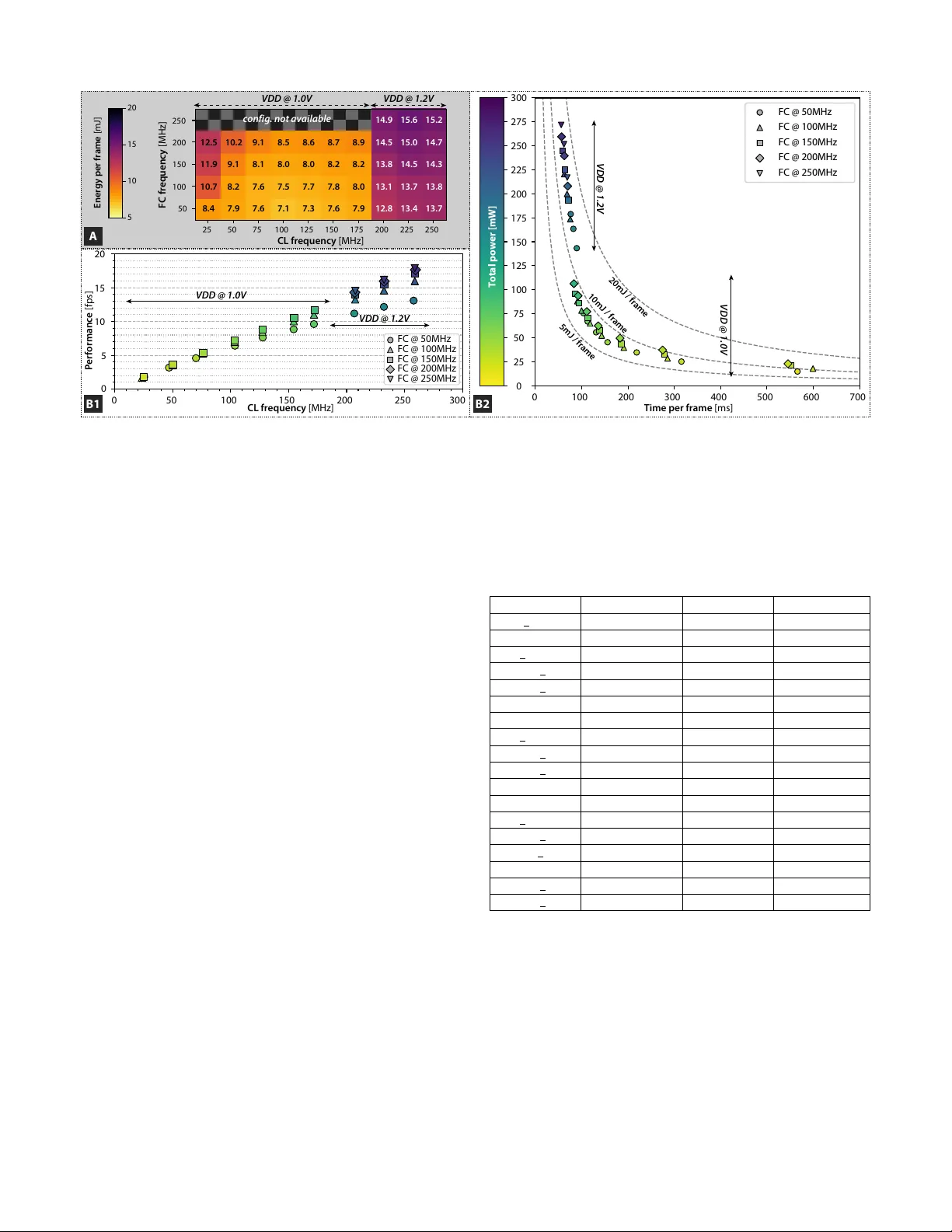
1 A 64mW DNN-based V isual Na vigation Engine for Autonomous Nano-Drones Daniele Palossi, Antonio Loquercio, Francesco Conti, Member , IEEE, Eric Flamand, Davide Scaramuzza, Member , IEEE, Luca Benini, F ellow , IEEE Abstract —Fully-autonomous miniaturized robots (e.g ., drones), with artificial intelligence (AI) based visual navigation capa- bilities, are extremely challenging drivers of Internet-of-Things edge intelligence capabilities. V isual navigation based on AI approaches, such as deep neural networks (DNNs) are becoming pervasi ve for standard-size drones, but are considered out of reach for nano-drones with a size of a few cm 2 . In this work, we present the first (to the best of our knowledge) demon- stration of a navigation engine for autonomous nano-drones capable of closed-loop end-to-end DNN-based visual navigation. T o achieve this goal we developed a complete methodology for parallel execution of complex DNNs dir ectly on board resource- constrained milliwatt-scale nodes. Our system is based on GAP8, a novel parallel ultra-low-power computing platform, and a 27 g commercial, open-source CrazyFlie 2.0 nano-quadr otor . As part of our general methodology , we discuss the software mapping techniques that enable the state-of-the-art deep convolutional neural network presented in [1] to be fully executed aboard within a strict 6 fps real-time constraint with no compromise in terms of flight results, while all pr ocessing is done with only 64 mW on av erage. Our na vigation engine is flexible and can be used to span a wide performance range: at its peak perf ormance corner , it achieves 18 fps while still consuming on av erage just 3.5% of the power en velope of the deployed nano-aircraft. T o share our key findings with the embedded and robotics communities and foster further developments in autonomous nano-U A Vs, we publicly release all our code, datasets, and trained networks. Index T erms —Autonomous U A V , Con volutional Neural Net- works, Ultra-low-power , Nano-U A V , End-to-end Learning S U P P L E M E N T A RY M A T E R I A L Supplementary video at: https://youtu.be/57Vy5cSvnaA. The project’ s code, datasets and trained models are av ailable at: https://github .com/pulp- platform/pulp- dronet. I . I N T R O D U C T I O N This work has been partially funded by projects EC H2020 OPRECOMP (732631) and ALOHA (780788), by the Swiss National Center of Competence Research (NCCR) Robotics and by the SNSF-ERC starting grant. D. Palossi, F . Conti, E. Flamand and L. Benini are with the Inte- grated System Laboratory of ETH Z ¨ urich, ETZ, Gloriastrasse 35, 8092 Z ¨ urich, Switzerland (e-mail: dpalossi@iis.ee.ethz.ch, fconti@iis.ee.ethz.ch, eflamand@iis.ee.ethz.ch, lbenini@iis.ee.ethz.ch). A. Loquercio and D. Scaramuzza are with the Robotic and Perception Group, at both the Dep. of Informatics (Univ ersity of Z ¨ urich) and the Dep. of Neuroinformatics (Univ ersity of Z ¨ urich and ETH Z ¨ urich), Andreasstrasse 15, 8050 Z ¨ urich, Switzerland. F . Conti and L. Benini are also with the Department of Electrical, Electronic and Information Engineering of University of Bologna, V iale del Risorgimento 2, 40136 Bologna, Italy (e-mail: f.conti@unibo.it, luca.benini@unibo.it). E. Flamand is also with GreenW aves T echnologies, P ´ epini ` ere Berg ` es, avenue des Papeteries, 38190 V illard-Bonnot, France (e-mail: eric.flamand@greenwav es-technologies.com). Fig. 1: Our prototype based on the COTS Crazyflie 2.0 nano- quadrotor extended with our PULP-Shield . The system can run the Dr oNet [1] CNN for autonomous visual navig ation up to 18 fps using only onboard resources. W ith the rise of the Internet-of-Things (IoT) era and rapid dev elopment of artificial intelligence (AI), embedded systems ad-hoc programmed to act in relati ve isolation are being progressi vely replaced by AI-based sensor nodes that acquire information, process and understand it, and use it to interact with the environment and with each other . The ”ulti- mate” IoT node will be capable of autonomously navigating the environment and, at the same time, sensing, analyzing, and understanding it [2]. Fully autonomous nano-scale unmanned aerial vehicles (U A Vs) are befitting embodiments for this class of smart sensors: with their speed and agility , they hav e the potential to quickly collect information from both their onboard sensors and from a plethora of devices deployed in the en vironment. Nano-U A Vs could also perform advanced onboard analytics, to pre-select essential information before transmitting it to centralized serv ers [3]. The tiny form-factor of nano-drones is ideal both for indoor applications where they should safely operate near humans (for surveillance, monitoring, ambient awareness, interaction with smart en vironments, etc.) [4] and for highly-populated urban areas, where they can exploit complementary sense-act capabilities to interact with the sur- roundings (e.g., smart-building, smart-cities, etc.) [5]. As an 2 T ABLE I: Rotorcraft UA Vs taxonomy by v ehicle class-size. V ehicle Class : W eight [cm:kg] Power [W] Onboard Device std-size [11] ∼ 50 : ≥ 1 ≥ 100 Desktop micr o-size [12] ∼ 25 : ∼ 0.5 ∼ 50 Embedded nano-size [13] ∼ 10 : ∼ 0.01 ∼ 5 MCU pico-size [14] ∼ 2 : ≤ 0.001 ∼ 0.1 ULP example, in this IoT scenario, a rele vant application for intel- ligent nano-size UA Vs can be the online detection of wireless activity , from edge nodes deployed in the en vironment, via onboard radio packet snif fing [6]. Commercial off-the-shelf (COTS) quadrotors have already started to enter the nano-scale, featuring only fe w centimeters in diameter and a fe w tens of grams in weight [7]. How- ev er , commercial nano-U A Vs still lack the autonomy boasted by their larger counterparts [1], [8], [9], [10], since their computational capabilities, heavily constrained by their tiny power env elopes, have been considered so far to be totally inadequate for the ex ecution of sophisticated AI workloads, as summarized in T able I. The traditional approach to autonomous navigation of a U A V is the so-called localization-mapping-planning cycle, which consists of estimating the robot motion using either offboard (e.g., GPS [15]) or onboard sensors (e.g., visual- inertial sensors [16]), building a local 3D map of the envi- ronment, and planning a safe trajectory through it [10]. These methods, howe ver , are very expensi ve for computationally- constrained platforms. Recent results ha ve shown that much lighter algorithms, based on con volutional neural networks (CNNs), are sufficient for enabling basic reactiv e navigation of small drones, e ven without a map of the en vironment [1], [17], [18], [19], [20]. Ho wever , their computational and power needs are unfortunately still abov e the allotted budget of current navigation engines of nano-drones, which are based on simple, low-po wer microcontroller units (MCUs). In W ood et al. [14], the authors indicate that, for small- size UA Vs, the maximum power budget that can be spent for onboard computation is 5% of the total, the rest being used by the propellers (86%) and the low-le vel control parts (9%). The problem of bringing state-of-the-art navigation capabilities on the challenging classes of nano- and pico-size U A Vs is therefore strictly dependent on the development of energy-ef ficient and computationally capable hardware, highly optimized software and new classes of algorithms combined into a next-generation navigation engine. These constraints and requirements depict the same scenario faced in deploying high-lev el computation capabilities on IoT edge-nodes/sensors. Moreov er, in the case of a flying miniature robot, the challenge is exacerbated by the strict real-time constraint dictated by the need for fast reaction time to pre vent collisions with dynamic obstacles. Whereas standard-size U A Vs with a po wer env elope of sev eral hundred W atts hav e alw ays been able to host powerful high-end embedded computers like Qualcomm Snapdragon 1 , Odroid, NVIDIA Jetson TX1, and TX2, etc., most nano-sized 1 https://dev eloper .qualcomm.com/hardware/qualcomm-flight U A Vs hav e been constrained by the capabilities of micro- controller devices capable of providing a few hundred Mop/s at best. Therefore, CNN-based autonomous vision navigation was so far considered to be out of reach for this class of drones. In this work, we propose a novel visual navigation engine and a general methodology to deploy complex CNN on top of CO TS resources-constrained computational edge-nodes such as a nano-size flying robot. W e present what, to the best of our kno wledge, is the first deployment of a State-of-the- Art (SoA), fully autonomous vision-based navigation system based on deep learning on top of a U A V visual navigation engine consuming less than 284 mW at peak (64 mW in the most energy-ef ficient configuration), fully integrated and in closed-loop control within an open source CO TS CrazyFlie 2.0 nano-U A V . Our visual navigation engine, sho wn on the top of the CrazyFlie 2.0 in Figure 1, lev erages the Gr een- W aves T echnolo gies GAP8 SoC, a high-efficienc y embedded processor taking adv antage of the emerging parallel ultra-low- power (PULP) computing paradigm to enable the e xecution of complex algorithmic flows onto power -constrained devices, such as nano-scale U A Vs. This work provides se veral contributions beyond the SoA of nano-scale U A Vs and serves as a proof-of-concept for a broader class of AI-based applications in the IoT field. In this work: • we de veloped a general methodology for deploying SoA deep learning algorithms on top of ultra-low po wer embedded computation nodes, as well as a miniaturized robot; • we adapted DroNet , the CNN-based approach for au- tonomous navig ation proposed in Loquercio et al. [1] for standard-sized UA Vs, to the computational requirements of a nano-sized U A V , such as fixed-point computation; • we deployed DroNet on the PULP-Shield , an ultra-low power visual navig ation module featuring the GAP8 SoC, an ultra-lo w power camera and off-chip Flash/DRAM memory; the shield is designed as a pluggable PCB for the 27 g CO TS CrazyFlie 2.0 nano-U A V ; • we demonstrate our methodology for the DroNet CNN, achieving a comparable quality of results in terms of U A V control with respect to the standard-sized baseline of [1] within an overall PULP-Shield power budget of just 64 mW, deli vering a throughput of 6 fps and up to 18 fps within 284 mW; • we field-prove our methodology presenting a closed-loop fully working demonstration of vision-dri ven autonomous navigation relying only on onboard resources. Our work demonstrates that parallel ultra-low-po wer com- puting is a viable solution to deploy autonomous navigation capabilities on board nano-U A Vs used as smart, mobile IoT end-nodes, while at the same time sho wcasing a complete hardware/software methodology to implement such complex workloads on a heavily power- and memory-constrained de- vice. W e prov e in the field the efficacy of our methodology by presenting a closed-loop fully functional demonstrator in the supplementary video material. T o foster further research on this field, we release the PULP-Shield design and all code running on GAP8, as well as datasets and trained networks, 3 as publicly av ailable under liberal open-source licenses. The rest of the paper is organized as follows: Section II provides the SoA o verview both in term of nano-UA Vs and low-po wer IoT . Section III introduces the software/hardware background of our work. Section IV presents in detail our CNN mapping methodology , including software tools and optimizations. Section V discusses the design of the visual navigation engine. Section VI-B shows the experimental e val- uation of the work, considering both performance and power consumption, comparing our results with the SoA and also ev aluating the final control accuracy . Finally , Section VII concludes the paper . I I . R E L AT ED W O R K The de velopment of the IoT is fueling a trend to ward edge computing, improving scalability , robustness, and security [2]. While today’ s IoT edge nodes are usually stationary , au- tonomous nano-U A Vs can be seen as perfect examples of next- generation IoT end-nodes, with high mobility and requiring an unprecedented lev el of onboard intelligence. The goal of this work is to make SoA visual autonomous navigation compatible with ultra-low po wer nano-drones, unlocking their deployment for IoT applications. Therefore, this section focuses on related work on nano-aircrafts [14] and the deployment of DNN on top of low-po wer IoT nodes. The traditional approach to autonomous navigation of nano- drones requires to offload computation to some remote, po wer- ful base-station. For instance, the authors of [21] de veloped a visual-inertial simultaneous localization and mapping (SLAM) algorithm, for a 25 g nano quadrotor . The SLAM algorithm was used to stabilize the robot and follo w a reference tra- jectory . All the computation was performed off-board, by streaming video and inertial information from the drone to a remote, power -unconstrained laptop. The main problems with this class of solutions are latency , maximum communication distance, reliability issues due to channel noise, and high onboard power -consumption due to the high-frequency video streaming. Few previous works presented nano-size flying robots with some degree of autonomous na vigation relying on onboard computation. In [13], the authors developed a 4 g stereo- camera and proposed a velocity estimation algorithm able to run on the MCU on board a 40 g flying robot. If on one side this solution allo ws the drone to av oid obstacles during the flight, it still requires fa vorable flight conditions (e.g., low flight speed of 0.3 m/s). In [22], an optical-flow- based guidance system was de veloped for a 46 g nano-size U A V . The proposed ego-motion estimation algorithm did not rely on feature tracking, making it possible to run on the onboard MCU. Unfortunately , the autonomous functionality was limited to hovering, and the method did not reach the accuracy of computationally expensiv e techniques based on feature tracking. In [23], an application-specific integrated circuit (ASIC), called NA VION , for onboard visual-inertial odometry was presented. Although this chip exposes enough computational power to perform state estimation up to 171 fps within 24 mW, this represents only one among other basic functionalities required by any UA V to be fully autonomous. Therefore, in a real use case, the proposed ASIC would still need to be paired with additional circuits, both for complementary onboard computation as well as for interacting with the drone’ s sensors. Moreover , to the date, the NA VION accelerator does not reach the same level of maturity and completeness of our work; in fact, NA VION has not yet been demonstrated on a real-life flying nano-drone. CO TS nano-size quadrotors, like the Bitcraze Crazyflie 2.0 or the W alkera QR LadyBug , embed on board low-po wer sin- gle core MCUs, like the ST Micr oelectr onics STM32F4 [13], [21], [24]. While significant work has been done within academia [25], [26], [27] and industry (e.g., T ensorFlow Lite 2 and ARM Compute Library 3 ) to ease the embedding of deep neural networks on mobile ARM-based SoC’ s, there is no general consensus yet on ho w to “correctly” deploy complex AI-powered algorithms, such a deep neural networks, on this class of low-po wer microcontrollers. This is a “hard” problem both in terms of resource management (in particular av ail- able working memory and storage) and the peak throughput achiev able by single core MCUs. This problem is furthermore exacerbated by a lack of abstraction layers and computing facilities that are taken from granted by common deep learning tools, such as linear algebra libraries (e.g., BLAS, CUBLAS, CUDNN) and preprocessing libraries (e.g., OpenCV). ARM has recently released CMSIS-NN [28], which is meant to shrink this gap by accelerating deep inference compute kernels on Cortex-M microcontroller platforms, providing the equiv alent of a BLAS/CUDNN library (in Section VI-B we present a detailed SoA comparison between our results and CMSIS-NN). Ho wev er , this ef fort does not curtail the difficulty of effecti vely deploying DNNs in memory-scarce platforms, which often requires particular scheduling/tiling [29], [30] and is still widely considered an open problem. Pushing beyond the aforementioned approaches, in this work we propose and demonstrate a visual na vigation engine capable of sophisticated workloads, such as real-time CNN- based autonomous visual na vigation [1], entirely aboard within the limited po wer en velope of nano-scale U A Vs ( ∼ 0.2 W). Such a kind of autonomous na vigation functionality has been previously limited to standard-sized U A Vs, generally equipped with power -hungry processors ( ≥ 10W) or relying on external processing and sensing (e.g., GPS) [6]. Our system relaxes both requirements: we use an onboard ultra-low-po wer pro- cessor and a learning-based navigation approach. I I I . B AC K G RO U N D In this section, we summarize the hardware/software back- ground underlying our visual navigation engine. W e first present the original Dr oNet CNN dev eloped for standard-size U A Vs. Then, we introduce the GAP8 SoC used on board of our nano-drone. A. Dr oNet DroNet is a lightweight residual CNN architecture. By predicting the steering angle and the collision probability , it 2 ttps://www .tensorflow .org/lite 3 https://arm-software.github .io/ComputeLibrary 4 3x3 3x3 /2 B N B N 1x1 /2 3x3 3x3 /2 B N B N 1x1 /2 5x5 /2 3x3 /2 /2 3x3 3x3 /2 B N B N 1x1 /2 RES BLOCK 1 3x3 RES BLOCK 2 RES BLOCK 3 100×100×32 50×50×32 25×25×32 13×13×64 7×7×128 NxN /S Convolution /S: stride factor NxN: lter size /S NxN Max-pooling /S: stride factor NxN: pool size B N Batch Normalization ReL u Sum Dropout F ully connected Sigmoid 7×7×128 13×13×64 25×25×32 Steering angle by-pass by-pass by-pass Prob. collision Input image 200x200x1 Fig. 2: Dr oNet [1] topology . enables safe autonomous flight of a quadrotor in v arious indoor and outdoor en vironments. The DroNet topology , as illustrated in Figure 2, was inspired by residual networks [31] and was reduced in size to minimize the bare image processing time (inference). The two tasks of steering and collision probability prediction share all the residual layers to reduce the network complexity and the frame processing time. Then, two separate fully connected layers independently infer steering and collision probabilities. Mean-squared error (MSE) and binary cross-entropy (BCE) hav e been used to train the two predictions, respectively . A temporal dependent weighting of the two losses ensures the training con vergence despite the dif ferent gradients’ magnitude produced by each loss. Eventually , to make the optimization focus on the samples that are most dif ficult to learn, hard negati ve mining was deployed in the final stages of learning. The two tasks learn from two separate datasets. Steering angle prediction was trained with the Udacity dataset 4 , while the collision probability was trained with the Z ¨ urich bicycle dataset 5 . The outputs of DroNet are used to command the U A V to move on a plane with velocity in forwarding direction v k and steering angle θ k . More specifically , the lo w-pass filtered probability of collision is used to modulate the UA V forward velocity , while the low-pass filtered steering angle is con verted to the drone’ s yaw control. The result is a single relativ ely shallo w network that processes all visual information and directly produces control commands for a flying drone. Learning the coupling between perception and control end-to- end provides se veral advantages, such as a simple, lightweight system and high generalization abilities. Indeed, the method was sho wn to function not only in urban en vironments but also on a set of new application spaces without any initial knowledge about them [1]. More specifically , e ven without a map of the en vironment, the approach generalizes very well to scenarios completely unseen at training time, including indoor corridors, parking lots, and high altitudes. B. GAP8 Ar chitectur e Our deployment target for the b ulk of the DroNet com- putation is GAP8, a commercial embedded RISC-V multi- core processor deriv ed from the PULP open source project 6 . At its heart, GAP8 is composed by an advanced RISC-V microcontroller unit coupled with a programmable octa-core 4 https://www .udacity .com/self-driving-car 5 http://rpg.ifi.uzh.ch/dronet.html 6 http://pulp-platform.org accelerator with RISC-V cores enhanced for digital signal processing and embedded deep inference. SoC Interconnect PULP CLUSTER Shared-L1 Interconnect Shared L1 Memory 64KB Shared Instruction Cache HW Sync DBG Unit L2 Memory 512KB DMA I $ L1 ROM CLK Gen DBG DC/DC L VDS UART SPI I2S I2C CPI HYPER GPIO JT AG PMU RTC DMA Fig. 3: Architecture of the GAP8 embedded processor . Figure 3 shows the architecture of GAP8 in detail. The pro- cessor is composed of two separate power and clock domains, the FA B R I C C T R L (FC) and the C L U S T E R (CL). The FC is an advanced microcontroller unit featuring a single RISC-V core coupled with 512 kB of SRAM ( L2 memory ). The FC uses an in-order , DSP-extended four -stage microarchitecture implementing the RISC-V instruction set architecture [32]. The core supports the R V32IMC instruction set consisting of the standard ALU instructions plus the multiply instruc- tion, with the possibility to execute compressed code. In addition to this, the core is extended to include a register - register multiply-accumulate instruction, packed SIMD (single instruction multiple-data) DSP instructions (e.g., fixed-point dot product), bit manipulation instructions and two hardware loops. Moreover , the SoC features an autonomous multi- channel I/O DMA controller ( µD M A ) [33] capable of trans- ferring data between a rich set of peripherals (QSPI, I2S, I2C, HyperBus, Camera Parallel Interf ace) and the L2 memory with no in volvement of the FC. The HyperBus and QSPI interfaces can be used to connect GAP8 with an external DRAM or Flash memory , effecti vely extending the memory hierarchy with an external L3 ha ving a bandwidth of 333 MB/s and capacity up to 128 Mbit. Finally , the GAP8 SoC also includes a DC/DC con verter con verting the battery voltage down to the required operating voltage directly on-chip, as well as two separate frequency-locked loops (FLL) for ultra-low power clock generation [34]. The C L U S T E R is dedicated to the acceleration of com- putationally intensiv e tasks. It contains eight RISC-V cores (identical to the one used in the FC) sharing a 64 kB multi- 5 T ABLE II: DroNet accuracy on PULP . In bold the configuration used for the final deployment. T raining Inference - Fixed16 Dataset Max-Pooling Data T ype Original Dataset HiMax Dataset EV A RMSE Accuracy F1-score Accuracy F1-score Original 3 × 3 Float32 0.758 0.109 0.952 0.888 0.859 0.752 3 × 3 Fixed16 0.746 0.115 0.946 0.878 0.841 0.798 2 × 2 Float32 0.766 0.105 0.945 0.875 0.845 0.712 2 × 2 Fixed16 0.795 0.097 0.935 0.857 0.873 0.774 Original + HiMax 3 × 3 Float32 0.764 0.104 0.949 0.889 0.927 0.884 3 × 3 Fixed16 0.762 0.109 0.956 0.894 0.918 0.870 2 × 2 Float32 0.747 0.109 0.964 0.916 0.900 0.831 2 × 2 Fixed16 0.732 0.110 0.977 0.946 0.891 0.821 banked shar ed L1 scratc hpad memory through a lo w-latency , high-throughput logarithmic interconnect [35]. The shared L1 memory supports single-cycle concurrent access from dif ferent cores requesting memory locations on separate banks and a starvation-free protocol in case of bank contentions (typically < 10% on memory-intensive kernels). The eight cores are fed with instruction streams from a single shared, multi- ported I-cache to maximize the energy efficiency on the data- parallel code. A cluster DMA controller is used to transfer data between the shared L1 scratchpad and the L2 memory; it is capable of 1D and 2D b ulk memory transfer on the L2 side (only 1D on the L1 side). A dedicated har dware synchr onizer is used to support fast ev ent management and parallel thread dispatching/synchronization to enable ultra-fine grain parallelism on the cluster cores. C L U S T E R and FA B R I C C T R L share a single address space and communicate with one another utilizing two 64-bit AXI ports, one per direction. A software runtime resident in the FC o verviews all tasks offloaded to the CL and the µD M A . On a turn, a low-o verhead runtime on the CL cores exploits the hardware synchronizer to implement shared-memory parallelism in the fashion of OpenMP [36]. I V . C N N M A P P I N G M E T H O D O L O G Y In this section, we discuss and characterize the main methodological aspects related to the deployment of Dr oNet on top of the GAP8 embedded processor . This task showcases all the main challenges for a typical deep learning application running on resource-constrained embedded IoT node. There- fore, while our visual navigation engine is application-specific, the underlying methodology we present in the follo wing of this section is general and could also be applied to other resource- bound embedded systems where computationally intensi ve tasks hav e to be performed under a real-time constraint on a parallel architecture. A. Deploying Dr oNet on GAP8 Follo wing an initial characterization phase, we calculated the original con volutional neural network (CNN) to in volv e ∼ 41 MMA C operations per frame (accounting only for con- volutional layers) and more than 1 MB of memory needed solely to store the network’ s weights, yielding a baseline for the number of resources required on our navigation engine 7 . T o successfully deploy the CNN on top of GAP8, the ex ecution of DroNet has to fit within the strict real-time constraints dictated by the target application, while respecting the bounds imposed by the on-chip and onboard resources. Specifically , these constraints can be resumed in three main points: • the minimum r eal-time frame-r ate required to select a ne w trajectory on-the-fly or to detect a suspected obstacle in time to prev ent a potential collision; • the nativ e quality-of-results must be maintained when using an embedded ultra-low power camera (in our pro- totype, the HiMax – see Section V for details) instead of the high-resolution camera used by the original DroNet; • the amount of available memory on the GAP8 SoC, as reported in Section III-B we can rely on 512 kB of L2 SRAM and 64 kB of shared L1 scratchpad (TCDM), sets an upper bound to the size of operating set and dictates ad-hoc memory management strategy . Therefore, it is clear there is a strong need for a strategy aimed at reducing the memory footprint and computational load to more easily fit within the av ailable resources while exploiting the architectural parallelism at best to meet the real-time constraint. The original DroNet network [1] has been modified to ease its final deployment; we operated incrementally on the model and training flo w pro vided by the original DroNet, based on Keras/T ensorFlow 8 . The first change we performed is the reduction of the numerical representation of weights and activ ations from the nativ e one, 32-bit floating point ( Float32 ), down to a more economical and hardware-friendly 16-bit fixed point one ( Fixed16 ) that is better suited for the deployment on any MUC-class processor without floating point unit (FPU), like in our GAP8 SoC. By analyzing the native Float32 network post-training, we determined that a dynamic range of ± 8 is sufficient to represent all weights and intermediate activ ations with realistic inputs. Accordingly , we selected a Fixed16 Q4.12 representation, using 4 bits for the integer part (includ- ing sign) and 12 bits for the fractional part of both acti vations and weights (rounding down to a precision of 2 − 12 ). Then, 7 The baseline MMAC count does not correspond to the final implemen- tation’ s instruction count, because it does not account for implementation details such as data marshaling operations to feed the processing elements; howe ver , it can be used to set an upper bound to the minimum ex ecution performance that is necessary to deploy DroNet at a giv en target frame rate. 8 https://github .com/uzh-rpg/rpg public dronet 6 we retrained the network from scratch replacing the nativ e con volutional layers from K eras to make them “quantization- aware”, using the methodology proposed by Hubara et al. [37]. The second significant change with respect to the original version of DroNet is the extension of the collision dataset used in [1] (named Original dataset) with ∼ 1300 images (1122 for training and 228 for test/validation) acquired with the same camera that is av ailable aboard the nano-drone (named Hi- Max dataset). Fine-tuning approaches, like dataset extension, hav e prov ed to be particularly effecti ve at improving network generalization capability [38]. In our case, the original dataset is built starting form high-resolution color cameras whose images are significantly different from the ones acquired by the ULP low-resolution grayscale camera av ailable in our navigation engine, particularly in terms of contrast. Therefore, we extended the training set and we ev aluate our CNN for both datasets separately . Finally , we modified the recepti ve field of max-pooling layers from 3 × 3 to 2 × 2, which yields essentially the same final results while reducing the execution time of max-pooling layers by 2.2 × and simplifying their final implementation on GAP8. T able II summarizes the results in terms of accuracy for all these changes. Explained variance 9 (EV A) and root-mean- squared error (RMSE) refer to the regression problem (i.e., steering angle) whereas Accuracy and F1-score 10 are related to the classification problem (i.e., collision probability), e valuated on both the Original and HiMax datasets. Regarding the Original dataset, it is clear that the proposed modifications are not penalizing the overall network’ s capabilities. Moreover , fine-tuning increases performance for almost all cases (both regression and classification), considering the test on the HiMax dataset, there is a definite impro vement in term of collision accuracy when training is done with the extended dataset. If we consider paired configurations, the fine-tuned one based is always outperforming its counterpart, up to 8% in accuracy (i.e., max-pooling 3 × 3, Fixed16 ). In T able II we also highlight (in bold) the scores achiev ed by the final version of DroNet deployed on GAP8. B. AutoT iler One of the most significant constraints in ULP embedded SoC’ s without caches is the explicit management of the memory hierarchy; that is, ho w to marshal data between the bigger - and slower - memories and the smaller - but faster - ones tightly coupled to the processing elements. A common technique is tiling [39], which in volv es i ) partitioning the input and output data spaces in portions or tiles small enough to fit within the smallest memory in the hierarchy (in our case, the shared L1) and ii ) setting up an outer loop iterating on tiles, with each iteration comprising the loading of an input tile into the L1, the production of an output tile, and the storage of the output tile into the higher lev els of the memory hierarchy . T iling is particularly effecti ve for algorithms like deep neural networks exposing very regular execution and data access patterns. As part of this w ork, we propose a tiling methodology that optimizes memory utilization on GAP8, while at the same 9 EV A = V ar [ y true − y pred ] V ar [ y true ] 10 F-1 = 2 precision × r ecall precision + r ecall time relieving the user from tedious and error-prone manual coding of the tiling loop and of the data mov ement mechanism. L2 Memory (512KB) L1 Memory (64KB) Input tensor DMA DMA DMA Output tensor F ilters Output tile tile 2 tile 1 tile 2 tile 3 tile 4 K in W in H in tile 1 tile 2 tile 3 tile 4 K out W out H out K in × K out conv F ilter H f W f Input tile tile 2 Fig. 4: Con volutional layer tiling. Considering Figure 4 as a reference, each layer in a CNN operates on a three-dimensional input tensor representing a featur e space (with one feature map per channel) and produces a new 3D tensor of activ ations as output. Con volutional layers, in particular , are composed of a linear transformation that maps K in input feature maps into K out output feature maps employing of K in × K out con volutional filters (or weight ma- trices). Therefore, in any con volutional layer , we can identify three different data spaces which can be partitioned in tiles in one or more of the three dimensions (i.e., W , H , and K in Figure 4). Similar considerations can also be made for the other layers in a CNN, allowing to treating them in the same fashion. As the design space defined by all possible tiling schemes is very large, we de veloped a tool called AutoT iler to help explore a subset of this space, choose an optimal tiling configuration, and produce C wrapping code that orchestrates the computation in a pipelined fashion as well as double- buf fered memory transfers, taking adv antage of the cluster DMA controller to efficiently mov e data between the L2 and L1 memories. The fundamental unit of computation assumed by the A utoT iler tool is the basic kernel , a function considering that all its working data is already located in the L1 shared memory . Examples of basic kernels include con volution, max- pooling, ReLU rectification, addition. T o map the overall high- lev el algorithm to a set of basic kernels that operate iteratively on tiles, the AutoT iler introduces a second le vel of abstraction: the node kernel . The structure of the target algorithm is coded by the dev eloper as a dependency graph, where each node (a node kernel) is a composition of one or more basic kernels together with a specification of the related iteration space ov er W , H , K in , K out . For example, a node kernel for a con volutional layer can be composed of a first basic kernel for setting the initial bias, a central one to perform con volutions and a final one for ReLU rectification: in the pr ologue , body , and epilogue , respectiv ely . The A utoT iler treats the tiling of each node kernel as an independent optimization problem con- strained by the node kernel specification and the memory sizes. This approach allo ws to build complex e xecution flo ws reusing hand-optimized basic kernels and abstracting the underneath complexity from the developer . 7 Listing 1 Example of spatial ex ecution scheme. x , w , y are the multi-dimensional input, weight and output tensors in L2 memory; b x , b w , and b y are their respective tiles in L1 memory . # weight DMA-in DMA_Copy( b w ← w ) for t in range (nb_tiles_H): # tiling over H # prologue operation (set bias value) b y ← BasicKernel_SetBias( b y ) for j in range (nb_tiles_Kin): # tiling over K in # input tile DMA-in DMA_Copy( b x ← x [ j, t ] ) for i in range ( K out ): # body operation (convolution) b y ← BasicKernel_Conv_Spatial( b y ) b y ← BasicKernel_ReLU( b y ) # output tile DMA-out DMA_Copy( y [ i, t ] ← b y ) Listing 2 Example of featur e-wise execution scheme. x , w , y are the multi-dimensional input, weight and output tensors in L2 memory; b x , b w , and b y are their respectiv e tiles in L1 memory . for i in range (nb_tiles_Kout): # tiling over K out # weight DMA-in DMA_Copy( b w ← w [ i ] ) # prologue operation (set bias value) b y ← BasicKernel_SetBias( b y ) for j in range (nb_tiles_Kin): # tiling over K in # input tile DMA-in DMA_Copy( b x ← x [ j ] ) # body operation (convolution) b y ← BasicKernel_Conv_FeatWise( b w , b x, b y ) # epilogue operation (ReLU) b y ← BasicKernel_ReLU( b y ) # output tile DMA-out DMA_Copy( y [ i ] ← b y ) C. T iling, P arallelization & Optimization As introduced in Section III, the GAP8 SoC features 8+1 RISC-V cores with DSP-oriented e xtensions. T o de velop an optimized, high-performance and energy-efficient application for GAP8 and meet the required real-time constraint it is paramount that the most computationally intensive kernels of the algorithm are parallelized to take advantage of the 8-core cluster and are entirely using the av ailable specialized instruc- tions. For the purpose of this work, we used the AutoT iler to fully implement the structure of the modified DroNet, therefore these optimization steps are reduced to hand-tuned parallelization and optimization of the basic kernels. T o exploit the av ailable computational/memory resources at best, we constrain the AutoT iler to target the follo wing general scheme: the input tensor is tiled along the H in and K in dimensions, while the output tensor is tiled along H out and K out ones. The stripes along H in are partially ov erlapped with one another to take into account the receptiv e field of con volutional kernels at the tile border . Execution of the node kernel happens in either a spatial or featur e-wise fashion, which differ in the ordering of the tiling loops and in the parallelization scheme that is applied. In the spatial scheme, work is split among parallel cores along the W out dimension; Figure 4 and 5-A refer to this scheme, which is also ex emplified in Listing 1. In the feature-wise scheme, which we only apply on full feature maps (i.e., the number of tiles in the GAP8 - CLUSTER Spatial scheme A Output tensor W out 0 1 2 3 4 5 6 7 K out -1 K out H out Feature-wise scheme B Output tensor Cores K out H out W out 0 1 2 3 4 5 6 7 Fig. 5: P arallelization schemes utilized in the Dr oNet layers for deployment on GAP8; the different colors represent allocation to a different core. H out direction is 1), work is split among cores along the K out dimension; this scheme is shown in Figure 5-B and Listing 2. The choice of one scheme ov er the other is influenced mostly by the parallelization efficienc y: after an exploration phase, we found the best performance arose when using the spatial scheme for the first node kernel of DroNet (first conv olution + max-pooling) while using the feature-wise approach for the rest. This choice is related to the fact that in deeper layers the feature map size drops rapidly and the spatial scheme becomes suboptimal because the width of each stripe turns too small to achiev e full utilization of the cores. T o further optimize the DroNet execution, we made use of all the optimized signal processing instructions av ailable in GAP8. These include packed-SIMD in- structions capable of exploiting sub-word parallelism, as well as bit-le vel manipulation and shuffling, which can be accessed by means of compiler intrinsics such as __builtin_pulp_dotsp2 (for 16-bit dot product with 32-bit accumulation), __builtin_shuffle (permutation of elements within two input vectors), __builtin_pulp_pack2 (packing two scalars into a vector). D. L2 Memory Management Str ategy Giv en i) the residual-network topology of DroNet, which requires to increase the lifetime of the output tensors of some of the layers (due to bypass layers), and ii) the “scarcity” of L2 memory as a resource to store all weights and temporary feature maps (we would need more than 1 MB in view of 512 kB av ailable), an ad-hoc memory management strategy for the L2 memory is required, similar to what is done between L2 and L1 using the GAP8 A utoT iler . Due to the high energy cost of data transfers between L3 and L2, the strategy needs to be aimed at the maximization of the L2 reuse. At boot time, before the actual computation loop starts, i) we load all the weights, stored in the external flash memory as binary files, in the L3 DRAM memory and ii) we call from the fabric controller the runtime allocator to reserve two L2 allocation stacks (sho wn in Figure 7) where intermediate buf fers will be allocated and deallocated in a linear fashion. The choice to use two allocation stacks instead of a single one is because in the latter case, we would need to keep ali ve up to 665 kB in L2 due to data dependencies, which is more than the available space. Our allocation strategy updates the pointer of the next free location in the pre-allocated L2 stack, avoiding the runtime ov erhead of library allocation/free functions. W e 8 NxN /S Convolution /S: stride factor NxN: lter size /S NxN Max-pooling /S: stride factor NxN: pool size R eLu Sum F ully connected Sigmoid L3-L2 memory managment Node ker nel I 1 =image; Alloc (O 1 ,0); Alloc (w 1 ,0); Free (w 1 ,0); I 2 =O 1 ; O 2 =O 1 ; # Node kernel 5x5 /2 3x3 /2 /2 3x3 I 1 w 1 O 1 Alloc (O 17 ,1); Alloc (w 11 ,1); Free (w 11 ,1); I 18 =O 16 ; Alloc (O 18 ,1); Alloc (w 12 ,1); I 17 w 11 O 17 # Node kernel I 18 w 12 O 18 # Node kernel image RES BL OCK 1 x3 Free (w 2 ,1); I 4 =O 3 ; Alloc (O 4 ,0); Alloc (w 3 ,1); I 3 =O 2 ; Alloc (O 3 ,1); Alloc (w 2 ,1); 3x3 Free (w 3 ,1); Free (O 3 ,1); I 5 =O 1 ; Alloc (O 5 ,1); Alloc (w 4 ,1); Free (w 4 ,1); I 6 =O 4 ; O 6 =O 5 ; Free (O 4 ,0); Free (O 1 ,0); I 7 =O 6 ; O 7 =O 6 ; # Node kernel # Node kernel # Node kernel # Node kernel # Node kernel I 2 O 2 I 3 w 2 O 3 I 4 w 3 O 4 I 5 w 4 O 5 I 6 O 6 O 6 /2 3x3 /2 1x1 Execution ow # DMA w 1 copy # DMA w 2 copy # DMA w 3 copy # DMA w 4 copy # DMA w 11 copy # DMA w 12 copy Basic k ernels Fig. 6: Dr oNet on PULP execution graph (with pseudo-code). differentiate our strategy between weights and feature maps: for the former , we allocate space just before their related layer and deallocate it just after the layer execution, as also shown in the pseudo-code blocks of Figure 6. For the latter , due to the residual network bypasses, we often ha ve to prolongate the lifetime of a feature map during the execution of the two following layers (node kernels in Figure 6). Therefore, for Allocation stack 0 O 1 O 1 O 8 O 8 O 10 O 10 O 10 O 10 w 1 w 5 w 6 w 7 w 8 w 9 O 15 O 4 162kB 200kB 59kB 96kB 26kB 169kB 308kB 26kB Allocation stack 1 O 3 O 3 O 5 O 5 O 13 O 13 O 17 O 17 w 2 w 4 w 11 O 18 58kB 58kB 42kB 62kB 26kB 42kB 13kB 13kB w 3 O 9 O 14 O 14 w 9 w 9 T ime Fig. 7: L2 memory allocation sequence. each RES block, there will be an amount of time where three tensors hav e to be stored at the same time. Figure 6 shows the full e xecution flow of DroNet related to our solution, annotated with the sequence of node kernels and the L3/L2 memory management blocks. For the sake of readability , in Figure 6, we report only the first RES block, but this can be generalized also to the others with fe w minor modifications and updating input, output and weights id. In the pseudo-code of Figure 6, the second parameter of the Alloc and Free function specifies the allocation buf fer (i.e., Allocation stack 0 or Allocation stack 1 in Figure 7). Note that, the µ DMA copies the weights from L3 to L2 just after the destination L2 area is allocated. The buf fers’ memory allocation sequence is reported in Figure 7 (from left to right) for the entire DroNet execution. The columns of the two stacks represent the data needed at each ex ecution step, where O i and w j represent the input/output feature maps and weights, respectiv ely . The last ro w of each stack reports the total amount of L2 memory required at each step. Thus, the final dimension of each stack is given by the column with the biggest occupancy (highlighted in light blue in Figure 7), resulting in 370 kB of L2 memory . Therefore, our solution not only allows to the DroNet execution within the L2 memory budget constraint but results in leaving 142 kB of the L2 still av ailable (i.e., ∼ 28% of the total) for additional onboard tasks like tar get following [40], etc. V . T H E P U L P - S H I E L D T o host our visual navigation algorithm, we designed a lightweight, modular and configurable printed circuit board (PCB) with highly optimized layout and a form factor com- patible with our nano-size quadrotor . It features a PULP-based GAP8 SoC, two Cypress HyperBus Memories 11 and an ultra- low power HiMax CMOS image sensor 12 able to run up to 60 fps with a gray-scale resolution of 320 × 240 pixels with just 4.5 mW of power . Our pluggable PCB, named PULP- Shield , has been designed to be compatible with the Crazyflie 2.0 (CF) nano-quadrotor 13 . This vehicle has been chosen due to its reduced size (i.e., 27 g of weight and 10 cm of diameter) 11 http://www .cypress.com/products/hyperbus-memory 12 http://www .himax.com.tw/products/cmos-image-sensor/image-sensors 13 https://www .bitcraze.io/crazyflie-2 9 A B Fig. 8: The PULP-Shield pluggable PCB. T op view (A) and bottom view (B). and its open-source and open-hardware philosophy . The com- munication between the PULP chip and the main MCU aboard the nano-drone (i.e., ST Micr oelectr onics STM32F405 14 ) is realized via an SPI interface and two GPIO signals. In Figure 8 the schematic of the proposed PULP-Shield is shown. T wo BGA memory slots allow all possible combina- tions of HyperRAM , HyperFlash , and hybrid HyperFlash/RAM packages. In this way , we can select the most appropriate memory configuration given a target application. W e mounted on one slot a 64 Mbit HyperRAM (DRAM) chip and on the other a 128 Mbit HyperFlash memory , embodying the system L3 and the external storage, respecti vely . On the PCB (Figure 8-B) there is also a camera connector that allo ws the HiMax camera to communicate with the rest of the system through the parallel camera interface (PCI) proto- col. T wo mounting holes, on the side of the camera connector, allow plugging a 3D-printed camera holder that can be set either in front-looking or down-looking configuration. Those two configurations are representative of the most common visual sensors layouts typically embedded in any autonomous flying vehicles. The front-looking configuration can be used for many navig ation tasks like path planning [41], obstacle av oidance [42], trajectory optimization [9], to name a few . Instead, the do wn-looking camera configuration is usually chosen for stabilization tasks like distance estimation [43], way-point tracking, and positioning [44], etc. On the shield, there are also a JT A G connector for debug purposes and an external I2C plug for future development. T wo headers, located on both sides of the PCB, grant a steady physical connection with the drone and at the same time, they bring the shield power supply and allow communication with the CF through the GPIOs and the SPI interf ace. The form factor of our final PULP-Shield prototype is 30 × 28 mm, and it weighs ∼ 5 g (including all components), well belo w the payload limit imposed by the nano-quadcopter . Similarly to what has been presented in [36], the PULP- Shield embodies the Host-Accelerator architectural paradigm, where the CF’ s MCU offloads the intensi ve visual navigation workload to the PULP accelerator . As depicted in Figure 9 the interaction starts from the host, which wakes up the accelerator with a GPIO interrupt 1 . Then, the accelerator fetches from its external HyperFlash storage the kernel (stored as a binary 14 http://www .st.com/en/microcontrollers/stm32f405-415.html 1 6 7 Host/Drone PULP-Shield 1 Init interrupt (GPIO) 2 Load binary 3 Configure camera (I2C) 4 Grab frames ( DMA) 5 LD Weights and Exec 6 Write-back results (SPI) 7 Result ready (ack) Fig. 9: Example of interaction between the PULP-Shield and the drone. file) to be executed: DroNet in our case 2 . Note that, in this first part of the protocol the host can also specify which kernel should be e xecuted, as well as a sequence of se veral pre-loaded ones av ailable on the external Flash storage. At this point, the GAP8 SoC can configure the HiMax camera via an internal I2C 3 and start to transfer the frames from the sensor to the L2 shared memory through the µ DMA 4 . All additional data, like the weights used in our CNN, can be loaded from the DRAM/Flash memory and parallel ex ecution is started on the accelerator 5 . Lastly , the results of the computation are returned to the drone’ s MCU via SPI 6 , and the same host is acknowledged about the av ailable results with a final interrupt ov er GPIO 7 . Note that, the transfer of a new frame is performed by the µ DMA overlapping the CNN computation on the previous frame performed in the C L U S T E R . Even if the PULP-Shield has been developed specifically to fit the CF quadcopter , its basic concept and the functionality it provides are quite general, and portable to any drone based on an SPI-equipped MCU and more generally to a generic IoT node requiring visual processing capabilities. The system-level architectural template it is based on is meant for minimizing data transfers (i.e., exploiting locality of data) and communi- cation overhead between the main MCU and the accelerator – without depending on the internal microarchitecture of either one. V I . E X P E R I M E N TA L R E S U LT S In this section we present the experimental ev aluation of our visual navigation engine, considering three primary metrics: i) the capability of respecting a giv en real-time deadline, ii) the ability of performing all the required computations within the allowed power budget and iii) the final accuracy of the closed-loop control, given as reaction time w .r .t. an unexpected obstacle. All the results are based on the PULP- Shield configuration presented in Section V. A. P erformance & P ower Consumption W e measured wall-time performance and po wer consump- tion by sweeping between several operating modes on GAP8. 10 0 25 50 75 100 125 150 175 200 225 250 275 300 Total power [mW] 0 50 100 150 200 250 300 0 5 10 15 20 0 100 200 300 400 500 600 700 FC @ 50MHz FC @ 100MHz FC @ 150MHz FC @ 200MHz FC @ 250MHz Time per frame [ms] FC @ 50MHz FC @ 100MHz FC @ 150MHz FC @ 200MHz FC @ 250MHz Performance [fps] FC @ 50MHz FC @ 100MHz FC @ 150MHz FC @ 200MHz FC @ 250MHz 25 50 75 100 125 150 175 200 225 250 CL frequency [MHz] 50 100 150 200 FC frequency [MHz] 14.9 15.6 15.2 12.5 10.2 9.1 8.5 8.6 8.7 8.9 14.5 15.0 14.7 11.9 9.1 8.1 8.0 8.0 8.2 8.2 13.8 14.5 14.3 10.7 8.2 7.6 7.5 7.7 7.8 8.0 13.1 13.7 13.8 8.4 7.9 7.6 7.1 7.3 7.6 7.9 12.8 13.4 13.7 Energy per frame [mJ] 5 10 15 20 VDD @ 1.0V VDD @ 1.2V VDD @ 1.0V VDD @ 1.2V VDD @ 1.2V VDD @ 1.0V 20mJ / fr ame 10mJ / fr ame 5mJ / fr ame CL frequency [MHz] 250 c onfig . not av a ilable A B1 B2 Fig. 10: A) Heat map sho wing the energy per frame in all tested configurations of GAP8 with VDD@1.0 V and VDD@1.2 V; B1) DroNet performance in frames per second (fps) in all tested configurations (coloring is proportional to total system power); B2) DroNet total system power vs. time per frame in all tested configurations; dashed gray lines show the lev els of energy efficienc y in mJ/frame. W e focused on operating at the lo west (1.0 V) and highest (1.2 V) supported core VDD voltages. W e swept the oper- ating frequency between 50 and 250 MHz, well be yond the GAP8 officially supported configuration 15 . Figure 10 provides a complete view of the po wer consumption in all experi- mentally possible operating modes of GAP8 on the DroNet application while sweeping both F A B R I C C T R L (FC) and C L U S T E R (CL) clock frequency , both at 1.0 V and 1.2 V and the related achiev able frame-rate. Figure 10-A sho ws the energy-efficienc y of all av ailable configurations as a heat map, where VDD@1.0 V, FC@50 MHz, and CL@100 MHz represent the most energy efficient one. In Figure 10-B1 we report performance as frame-rate and total power consumption measured before the internal DC/DC conv erter utilized on the SoC. Selecting a VDD operating point of 1.2 V would increase both power and performance up to 272 mW and 18 fps. W e found the SoC to be working correctly @ 1.0 V for frequencies up to ∼ 175 MHz; we note that as expected when operating @ 1.0 V there is a definite advantage in terms of energy efficienc y . Therefore, for the sake of readability , in Figure 10 we av oid showing configurations of VDD 1.2 V that would reach the same performance of VDD 1.0 V at a higher cost in term of power . Similarly , in Figure 10-B2 we report power consumption vs time to compute one frame. In Figure 11 we present the power traces for full end- to-end ex ecution of DroNet, measured using a bench DC power analyzer 16 . The power traces are measured by powering the GAP8 SoC, with the most energy-efficient configuration at 1.0 V core voltage and operating at 50 MHz on FC and 100 MHz on CL. The detailed average power consumption (including both the F C and C L domains) is reported in T able III. The peak power consumption of 47 mW is associated 15 https://greenwav es-technologies.com/gap8-datasheet 16 www .keysight.com/en/pd-1842303-pn-N6705B T ABLE III: Power consumption & Ex ecution time per frame of Dr oNet on GAP8 VDD@1.0 V, FC@50 MHz, CL@100 MHz. Layer A VG Power [mW] Exec Time [ms] L3-L2 Time [ms] con v 1 + pool 47.1 22.6 0.1 ReLU 24.8 0.9 — con v 2 + ReLU 38.7 17.3 0.6 con v 3 38.0 14.3 0.6 con v 4 43.6 7.3 0.1 add 38.9 0.3 — ReLU 27.6 0.2 — con v 5 + ReLU 37.7 9.3 1.2 con v 6 34.8 17.0 2.4 con v 7 32.7 4.2 0.2 add 24.3 0.3 — ReLU 20.5 0.3 — con v 8 + ReLU 33.1 13.0 4.7 con v 9 31.9 24.8 9.4 con v 10 41.9 5.4 0.5 add + ReLU 24.4 0.3 — fully 1 13.0 0.1 0.4 fully 2 13.0 0.1 0.4 to the 1 st con volutional layer; we used this value to compute the overall power en velope of our node. Instead, the minimum power consumption is giv en by the two last fully connected layers consuming 13 mW each. The average power consump- tion, weighted throughout each layer , is 39 mW, which grows to 45 mW including also the losses on the internal DC/DC con verter (not included in Figure 11). In the full DroNet ex ecution, layers are interposed with L3-L2 data transfers, happening with the CL cores in a clock-gated state, which accounts for ∼ 7% of the overall ex ecution time. Therefore, power consumption for the entire board settles to 64 mW if we 11 FC CL P ower consumption [mW] 0 10 0 10 20 40 RES BLOCK 1 - 32 Ch 30 50 0 20 Ex ecution time [ms] 40 60 80 100 120 140 160 RES BLOCK 2 - 64 Ch F ully connected Sum CLUSTER FABRIC CTRL RES BLOCK 3 - 128 Ch R eLu 3x3 3x3 1x1 3x3 3x3 1x1 5x5 2x2 /2 3x3 3x3 1x1 1x1 /2 /2 /2 /2 /2 /2 /2 Convolution /S: stride factor NxN: lter size NxN /S Max pooling /S: stride factor NxN: pool size NxN /S DMA DMA DMA DMA DMA DMA DMA L3-L2 DMA read DMA Fig. 11: Power traces per layer of Dr oNet , measured at VDD@1.0 V, FC@50 MHz, CL@100 MHz, the symbols on top of the plot indicate the computation stage associated with each visible phase in the power trace. Measurements are taken after internal DC/DC con verter (i.e., accounting for both FA B R I C C T R L and C L U S T E R ). also consider the cost of L3 memory access and the onboard ULP camera. VDD 1.0V - FC@50MHz / CL@100MHz VDD 1.2V - FC@250MHz / CL@250MHz CF Electronics PULP-Shield Motors FC+CL+DCDC DRAM Camera 0.28 W / 3.5% 0.28 W / 3.5% 8 mW / 2.8% 4 mW / 1.4% 0.28 W / 3.6% 0.06 W / 0.8% A B 272 mW / 95.8% 7.32 W / 93.0% 7.32 W / 95.6% Fig. 12: Power en velope break-down of the entire cyber - physical system running at FC@50 MHz-CL@100 MHz (A) and FC@250 MHz-CL@250 MHz (B) with PULP-Shield zoom-in (on the right). In Figure 12 is reported the power break-do wn for the complete c yber-physical system and proposed PULP-Shield. Our nano-quadcopter is equipped with a 240 mA h 3.7 V LiPo battery enabling a flight time of 7 minutes under standard conditions, which results in av erage power consumption of 7.6 W. The po wer consumption of all the electronics aboard the original drone amounts to 277 mW leaving ∼ 7.3 W for the four rotors. The electronics consumption is given by the 2 MCUs included in the quadrotor and all the additional devices (e.g., sensors, LEDs, etc.). In addition to that, introducing the PULP-Shield, we increase the peak power en velope by 64 mW using the most energy-efficient configuration and by 284 mW selecting the fastest setting (0.8% and 3.5% of the total, re- spectiv ely). On the PULP-Shield we consider the HyperRAM is operating at full speed only for the time required for L3-L2 data transfers (as shown in T able III) with an av erage power consumption of 8 mW for the fastest configuration, as reported in Figure 12-B. Notice that this is a worst-case figure, taking account of both the GAP8 SoC and the HyperRAM operating at full speed simultaneously . The po wer break-down of our visual na vigation module can be seen on the right of Figure 12- B, where we include the computational unit, the L3 external DRAM memory , and the ultra-low power camera. As onboard computation accounts for roughly 5% of the overall power consumption (propellers, sensors, computation and control, cfr Section I), our PULP-Shield enables the ex ecution of the DroNet network (and potentially more) in all configurations within the giv en power env elope. T ABLE IV: CrazyFlie (CF) lifetime with and without PULP- Shield (both turned off and running Dr oNet at VDD@1.0 V, FC@50 MHz, CL@100 MHz). Original CF CF + PULP-Shield (off) CF + PULP-Shield (on) Lifetime ∼ 440 s ∼ 350 s ∼ 340 s Finally , in our last experiment, we ev aluate the cost in terms of operating lifetime of carrying the physical payload of the PULP-Shield and of executing the DroNet workload. T o ensure a fair measurement, we decoupled the DroNet output from the nano-drone control and statically set it to hover (i.e., keep constant hight over time) at 0.5 m from the ground. W e targeted three dif ferent configurations: i ) the original Cr azyFlie (CF) without any PULP-Shield; ii ) PULP-Shield plugged but nev er turned on, to ev aluate the lifetime reduction due to the additional weight introduced; iii ) PULP-Shield turned on exe- cuting DroNet at VDD@1.0 V, FC@50 MHz, CL@100 MHz. Our results are summarized in T able IV and as expected the 12 biggest reduction in the lifetime is giv en by the increased weight. The flight time of the original nano-drone, with one battery fully charged, is ∼ 440 s. This lifetime drops to ∼ 350 s when the drone is carrying the PULP-Shield (turned of f) and to ∼ 340 s when the shield is executing DroNet. Ultimately , the price for our visual navigation engine is ∼ 22% of the original lifetime. B. State-of-the-Art Comparison & Discussion T o compare and validate our experimental results with respect to the current state-of-the-art, we targeted the most efficient CNN implementation currently av ailable for micro- controllers, namely CMSIS-NN [28]. At peak performance in a synthetic test, this fully optimized library can achieve as much as 0.69 MA C/cycle on con volutions, operating on F ixed8 data that is internally con verted to F ixed16 in the inner loop. By contrast, we operate directly on F ixed16 and achie ve a peak performance of 0.64 MA C/cycle/core in a similar scenario (on the 6 th layer of DroNet, 3 × 3 conv olution). The bypasses and the final layers are a bit less efficient, yielding an o verall weighted peak throughput of 0.53 MAC/c ycle/core on con volutional layers, which constitute the v ast majority of the ex ecution time. T ABLE V: C L U S T E R -cycle break-down for processing one frame on the GAP8 both FC and CL @ 50 MHz. µDM A L3/L2 DM A L2/L1 Computation T otal Cycles 1.03 M 0.11 M 13.47 M 14.61 M In T able V we report the e xecution breakdown per frame for all activities performed by our CNN. W e can see how the L3-L2 transfers (not o verlapped to computation) and the non- ov erlapping part of L2-L1 transfers account for ∼ 1.14 Mc ycles of the ov erall ex ecution time. Then, considering ∼ 41 MMA C for the original CNN, in the ideal peak-throughput case of 4.28 MA C/cycle we would need ∼ 10 Mcycles for computing one frame, instead of our measured 13.47 Mcycles. The ov erhead is due to inevitable non-idealities such as sub- optimal load balancing in layers exposing limited spatial parallelism as well as tiling control loops and the marshaling stage required by padded con volutions. Considering all of the effects mentioned above (i.e., computation non-idealities as well as memory transfers), we achieve a real throughput of 2.81 MA C/cycle in the DroNet execution – still 4 × better than the CMSIS-NN peak performance. T o further concretize the comparison, we take as an ex- ample target a top-notch high-performance microcontroller: an STM32H7 17 sporting a Cortex-M7 core and capable of operating at up to 400 MHz. W ithout considering any data mov ement overhead, and taking into account only peak per- formance, this would be able to achiev e up to 276 MMAC/s @ 346 mW. By comparison, our system can achieve an average performance of 281 MMA C/s with the most power -efficient configuration @ 45 mW, i.e. same performance within a 5.4 × smaller power budget. Moreover , if we consider our peak- throughput configuration (where both FC and CL are running 17 http://www .st.com/en/microcontrollers/stm32h7-series.html @ 250 MHz) we can deliv er up to 702 MMA C/s @ 272 mW: 2.5 × better with 21% less po wer . Even if it were possible to linearly up-scale the performance of this microcontroller to the same lev el of our system, it would consume ∼ 880 mW, which w ould constitute lar gely more than the 5% of power en velope typically dedicated to onboard computation on nano- U A V systems [14]. This confirms that the parallel-ultra-low power approach adopted in our visual navigation engine significantly outperforms sequential processing in terms of energy efficienc y , without compromising programmability and flexibility . C. Contr ol Accuracy T o fully exploit the natural inertial agility of a lightweight nano-quadrotor as the Crazyflie 2.0 used in our prototype, fast onboard perception is required. T o e valuate the agility of our integrated system, we perform an experiment in which our fly- ing platform is required to react to a sudden obstacle occluding its way . With this experiment, we aim to demonstrate that the PULP-Shield computational resources are enough to make full use of the platform agility . As mentioned in Section IV -A, for the final deployment of DroNet on the PULP-Shield, we select the network trained with Fixed16 quantization, 2 × 2 max-pool recepti ve field, and fine-tuning dataset. The choice is justified by both the quantization requirement of the GAP8 SoC and the model performance, superior to other viable alternativ es (see T able II). The experimental setting is as follo ws: we collect a dataset of images by manually flying the drone ov er a straight path of 20 m at an average speed of 4 m/s. At the beginning of the test, the path is entirely free from obstacles. At T = 4 s after the start of the experiment, an obstacle appears at the end of the track, leaving 4 m free for breaking and stopping. The system is then required to raise a stop signal soon enough to a void the collision. As we sho w in the additional video, our integrated system can control the nano-drone in closed- loop. Ho wever , for safety reasons and to avoid damaging the platform, we don’t control the nano-drone in closed- loop during this experiment. Instead, we process the frames collected with manual flight offline. The collected dataset is used to study the relation between the system operational frequencies and the drone’ s reaction time. As in the original implementation of [1], network’ s predic- tions are low-pass filtered to decrease high-frequency noise. In detail, the collision probability p k is a low-pass filtered v ersion of the raw network output c k ( α = 0 . 7 ): p k = (1 − α ) p k − 1 + αc k , (1) Figure 13 (A3-B3) illustrates the predicted collision proba- bility of the original and quantized DroNet CNN as a function of time. In the plots, we show both c k and p k at different frequencies, the former reported as markers, whereas the latter is sho wn as a continuous line. A horizontal dashed orange line shows the threshold for sending a stop signal to the control loop ( p k > 0 . 7 ), and a vertical red dashed line highlights the time at which the obstacle becomes visible ( T = 4 s). T o quantitati vely ev aluate the performance of our system at different operational frequencies, we computed the maximum 13 4 . 0 1 . 0 0 . 8 0 . 6 0 . 4 5 1 0 1 5 2 0 2 5 3 0 F r e q u e n c y [ H z ] 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 D is t a n ce f r o m o b st a c le [ m ] 5 1 0 1 5 2 0 2 5 3 0 F r e q u e n c y [ H z ] 0 . 0 0 . 5 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 D is t a n ce f r o m o b st a c le [ m ] 5 1 0 1 5 2 0 2 5 3 0 F r e q u e n c y [ H z ] 4 . 0 4 . 2 4 . 4 4 . 6 4 . 8 5 . 0 T im e [ s ] max stop time 5 1 0 1 5 2 0 2 5 3 0 F r e q u e n c y [ H z ] 4 . 0 4 . 2 4 . 4 4 . 6 4 . 8 5 . 0 T im e [ s ] max stop time 3 . 6 3 .8 4 . 0 4 .2 4 . 4 4 .6 4 . 8 5 .0 T im e [ s ] 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C ol li s io n P r o b a b il it y [ -] 3 . 6 3 .8 4 .2 4 .4 4 .6 4 .8 5 .0 T im e [ s ] 0 . 0 0 . 2 1 . 0 C ol li s io n P r o b a b il it y [ -] stop threshold LP lter probability ( p k ) 5 Hz 10 Hz 20 Hz DroNet probability ( c k ) 5 Hz 10 Hz 20 Hz stop threshold LP lter probability ( p k ) 5 Hz 10 Hz 20 Hz DroNet probability ( c k ) 5 Hz 10 Hz 20 Hz A1 A2 A3 B1 B2 B3 DroNet on PULP ( xed16 ) Original DroNet ( oat32 ) obstacle obstacle braking distance braking distance Fig. 13: Performance comparison between the original (A1-3) and quantized (B1-3) Dr oNet architectures. Stop command time (A1 and B1), minimum distance from the obstacle (A2 and B2) and collision probability as the output of both CNN and low-pass filter (A3 and B3). time and the minimum distance from the object at which the stop command should be gi ven to av oid the collision. W e deployed the Crazyflie 2.0 parameters from [45] and the classical quadrotor motion model from [46] to analytically compute those two quantities. From this analysis, we deriv ed a minimum stopping time of 400 ms and a braking distance of 0.7 m, assuming the platform mov es with a speed of 4 m/s when it detects the obstacle. In Figure 13 (A1-2, B1-2) we illustrate a performance comparison between our quantized system and the original implementation of [1]. Despite quantization, our network outperforms [1] in term of collision detection, and can react more quickly to sudden obstacles ev en at low operational frequencies. This is in accordance with the results of T able II, and mainly due to the fine-tuning of our network to the HiMax camera images. Both the quantized and original architecture share how- ev er a similar behaviour at different operational frequencies. More specifically , both fail to detect obstacles at very low frequencies (i.e., 5 Hz), b ut successfully avoid the collision at higher rates. Interestingly , increasing the system frequencies does not alw ays improve performance; it can be observed in Figure 13-B2, where performance at 20 Hz is better than at 25 Hz. From Figure 13 we can observe that inference at 10 Hz allo ws the drone to brake in time and avoid the collision. This confirms that our system, processing up to 18 fps, can i) make use of the agility of the Crazyflie 2.0 and ii) be deployed in the same way as the original method to navigate in indoor/outdoor environments while avoiding dynamic obstacles. A video sho wing the performance of the system controlled in closed-loop can be seen at the following link: https://youtu.be/57Vy5cSvnaA. V I I . C O N C L U S I O N Nano- and pico-sized U A Vs are ideal IoT nodes; due to their size and physical footprint, they can act as mobile IoT hubs, smart sensors and data collectors for tasks such as surveillance, inspection, etc. Howe ver , to be able to perform these tasks, they must be capable of autonomous navigation of en vironments such as urban streets, industrial facilities and other hazardous or otherwise challenging areas. In this work, we present a complete deployment methodology tar geted at en- abling execution of complex deep learning algorithms directly aboard resource-constrained milliwatt-scale nodes. W e provide the first (to the best of our kno wledge) completely vertically integrated hardware/software visual navigation engine for au- tonomous nano-UA Vs with completely onboard computation – and thus potentially able to operate in conditions in which the latency or the additional power cost of a wirelessly-connected centralized solution. Our system, based on a Gr eenW aves T echnologies GAP8 SoC used as an accelerator coupled with the STM32 MCU on the CrazyFlie 2.0 nano-U A V , supports real-time computation of DroNet, an advanced CNN-based autonomous navigation algorithm. Experimental results sho w a performance of 6 fps @ 64 mW selecting the most energy-efficient SoC configura- 14 tion, that can scale up to 18 fps within an av erage po wer budget for computation of 284 mW. This is achie ved without quality- of-results loss with respect to the baseline system on which DroNet was deployed: a COTS standard-size U A V connected with a remote PC, on which the CNN was running at 20 fps. Our results show that both systems can detect obstacles fast enough to be able to safely fly at high speed, 4 m/s in the case of the CrazyFlie 2.0 . T o further pa ving the way for a vast number of advanced use-cases of autonomous nano-U A Vs as IoT -connected mobile smart sensors, we release open-source our PULP-Shield design and all code running on it, as well as datasets and trained networks. A C K N O W L E D G M E N T S The authors thank Hanna M ¨ uller for her contribution in designing the PULP-Shield , No ´ e Brun for his support in making the camera-holder , and Frank K. G ¨ urkaynak for his assistance in making the supplementary videos. R E F E R E N C E S [1] A. Loquercio, A. I. Maqueda, C. R. del Blanco, and D. Scaramuzza, “Dronet: Learning to fly by driving, ” IEEE Robotics and Automation Letters , vol. 3, no. 2, April 2018. [2] N. H. Motlagh, T . T aleb, and O. Arouk, “Low-altitude unmanned aerial vehicles-based internet of things services: Comprehensi ve survey and future perspecti ves, ” IEEE Internet of Things Journal , v ol. 3, no. 6, Dec 2016. [3] F . Conti, R. Schilling, P . D. Schiav one, A. Pullini, D. Rossi, F . K. G ¨ urkaynak, M. Muehlberghuber , M. Gautschi, I. Loi, G. Haugou, S. Mangard, and L. Benini, “ An IoT Endpoint System-on-Chip for Secure and Energy-Ef ficient Near-Sensor Analytics, ” IEEE T ransactions on Circuits and Systems I: Re gular P apers , vol. 64, no. 9, pp. 2481– 2494, Sep. 2017. [4] D. Palossi, A. Gomez, S. Draskovic, A. Marongiu, L. Thiele, and L. Benini, “Extending the lifetime of nano-blimps via dynamic motor control, ” Journal of Signal Pr ocessing Systems , Feb 2018. [5] D. Floreano and R. J. W ood, “Science, technology and the future of small autonomous drones, ” Natur e , vol. 521, no. 7553, pp. 460–466, may 2015. [6] Z. Liu, Y . Chen, B. Liu, C. Cao, and X. Fu, “Hawk: An unmanned mini- helicopter-based aerial wireless kit for localization, ” IEEE T ransactions on Mobile Computing , vol. 13, no. 2, pp. 287–298, Feb 2014. [7] M. Piccoli and M. Y im, “Piccolissimo: The smallest micro aerial vehicle, ” in 2017 IEEE International Confer ence on Robotics and Automation (ICRA) . IEEE, may 2017. [8] Y . Lin, F . Gao, T . Qin, W . Gao, T . Liu, W . Wu, Z. Y ang, and S. Shen, “ Autonomous aerial navigation using monocular visual-inertial fusion, ” Journal of Field Robotics , vol. 35, no. 1, pp. 23–51, jul 2017. [9] D. Falanga, E. Mueggler , M. Faessler , and D. Scaramuzza, “ Aggressiv e quadrotor flight through narro w gaps with onboard sensing and com- puting using active vision, ” in 2017 IEEE International Conference on Robotics and Automation (ICRA) , May 2017. [10] G. Loianno, D. Scaramuzza, and V . Kumar , “Special issue on high-speed vision-based autonomous navigation of uavs, ” Journal of Field Robotics , vol. 35, no. 1, pp. 3–4, 2018. [11] Y . Y ang, Z. Zheng, K. Bian, L. Song, and Z. Han, “Real-time profiling of fine-grained air quality index distribution using uav sensing, ” IEEE Internet of Things Journal , vol. 5, no. 1, Feb 2018. [12] J. Conroy , G. Gremillion, B. Ranganathan, and J. S. Humbert, “Im- plementation of wide-field integration of optic flow for autonomous quadrotor navigation, ” Autonomous robots , vol. 27, no. 3, 2009. [13] K. McGuire, G. de Croon, C. D. W agter, K. Tuyls, and H. Kappen, “Efficient optical flow and stereo vision for velocity estimation and obstacle av oidance on an autonomous pocket drone, ” IEEE Robotics and Automation Letters , vol. 2, no. 2, April 2017. [14] R. J. W ood, B. Finio, M. Karpelson, K. Ma, N. O. P ´ erez-Arancibia, P . S. Sreetharan, H. T anaka, and J. P . Whitney , Pr ogr ess on “Pico” Air V ehicles . Cham: Springer International Publishing, 2017. [15] S. Scherer , J. Rehder, S. Achar , H. Cov er, A. Chambers, S. Nuske, and S. Singh, “River mapping from a flying robot: state estimation, ri ver detection, and obstacle mapping, ” Autonomous Robots , vol. 33, no. 1-2, 2012. [16] D. Scaramuzza, M. C. Achtelik, L. Doitsidis, F . Friedrich, E. Kos- matopoulos, A. Martinelli, M. W . Achtelik, M. Chli, S. Chatzichristofis, L. Kneip, D. Gurdan, L. Heng, G. H. Lee, S. Lynen, M. Pollefeys, A. Renzaglia, R. Siegwart, J. C. Stumpf, P . T anskanen, C. Troiani, S. W eiss, and L. Meier, “V ision-controlled micro flying robots: From system design to autonomous navigation and mapping in GPS-denied en vironments, ” IEEE Robotics & Automation Magazine , vol. 21, no. 3, pp. 26–40, sep 2014. [17] D. Gandhi, L. Pinto, and A. Gupta, “Learning to fly by crashing, ” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS) , sep 2017. [18] F . Sadeghi and S. Levine, “CAD2rl: Real single-image flight without a single real image, ” in Robotics: Science and Systems XIII , jul 2017. [19] N. Smolyanskiy , A. Kamenev , J. Smith, and S. Birchfield, “T oward low- flying autonomous mav trail navigation using deep neural networks for en vironmental awareness, ” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS) , Sept 2017. [20] S. Ross, N. Melik-Barkhudarov , K. S. Shankar, A. W endel, D. Dey , J. A. Bagnell, and M. Hebert, “Learning monocular reactiv e uav control in cluttered natural environments, ” in 2013 IEEE International Conference on Robotics and Automation , May 2013. [21] O. Dunkley , J. Engel, J. Sturm, and D. Cremers, “V isual-inertial navi- gation for a camera-equipped 25g nano-quadrotor, ” in IROS2014 Aerial Open Sour ce Robotics W orkshop , 2014. [22] A. Briod, J.-C. Zufferey , and D. Floreano, “Optic-flo w based control of a 46g quadrotor, ” in W orkshop on V ision-based Closed-Loop Contr ol and Navigation of Micr o Helicopters in GPS-denied En vir onments, IROS 2013 , no. EPFL-CONF-189879, 2013. [23] A. Suleiman, Z. Zhang, L. Carlone, S. Karaman, and V . Sze, “Navion: A fully integrated energy-ef ficient visual-inertial odometry accelerator for autonomous navigation of nano drones, ” in 2018 IEEE Symposium on VLSI Cir cuits , June 2018, pp. 133–134. [24] K. McGuire, G. de Croon, C. de W agter , B. Remes, K. T uyls, and H. Kappen, “Local histogram matching for efficient optical flo w com- putation applied to velocity estimation on pocket drones, ” in 2016 IEEE International Conference on Robotics and Automation (ICRA) , May 2016. [25] G. Hegde, Siddhartha, N. Ramasamy , and N. Kapre, “CaffePresso: An optimized library for Deep Learning on embedded accelerator-based platforms, ” in 2016 International Conference on Compliers, Arc hitec- tur es, and Sythesis of Embedded Systems (CASES) , Oct. 2016, pp. 1–10. [26] D. Kang, E. Kim, I. Bae, B. Egger, and S. Ha, “C-GOOD: C-code Generation Framework for Optimized On-device Deep Learning, ” in Pr oceedings of the International Conference on Computer-Aided Design , ser . ICCAD ’18. New Y ork, NY , USA: ACM, 2018, pp. 105:1–105:8. [27] A. Lokhmotov , N. Chunosov , F . V ella, and G. Fursin, “Multi-objective Autotuning of MobileNets Across the Full Software/Hardware Stack, ” in Pr oceedings of the 1st on Repr oducible Quality-Efficient Systems T our- nament on Co-Designing P areto-Ef ficient Deep Learning , ser . ReQuEST ’18. New Y ork, NY , USA: ACM, 2018. [28] L. Lai, N. Suda, and V . Chandra, “CMSIS-NN: Efficient Neural Netw ork Kernels for Arm Cortex-M CPUs, ” arXiv:1801.06601 [cs] , Jan. 2018. [29] M. Peemen, A. Setio, B. Mesman, and H. Corporaal, “Memory-centric accelerator design for Con volutional Neural Networks, ” in 2013 IEEE 31st International Confer ence on Computer Design (ICCD) , Oct. 2013, pp. 13–19. [30] C. Zhang, P . Li, G. Sun, Y . Guan, B. Xiao, and J. Cong, “Optimiz- ing FPGA-based Accelerator Design for Deep Conv olutional Neural Networks, ” in Proceedings of the 2015 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays , ser. FPGA ’15. New Y ork, NY , USA: ACM, 2015, pp. 161–170. [31] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , 2016. [32] M. Gautschi, P . D. Schiav one, A. T raber, I. Loi, A. Pullini, D. Rossi, E. Flamand, F . K. G ¨ urkaynak, and L. Benini, “Near-threshold risc- v core with dsp extensions for scalable iot endpoint devices, ” IEEE T ransactions on V ery Larg e Scale Integr ation (VLSI) Systems , vol. 25, no. 10, Oct 2017. [33] A. Pullini, D. Rossi, G. Haugou, and L. Benini, “uDMA: An autonomous I/O subsystem for IoT end-nodes, ” in 2017 27th International Sym- posium on P ower and T iming Modeling, Optimization and Simulation (P ATMOS) , Sep. 2017, pp. 1–8. 15 [34] D. E. Bellasi and L. Benini, “Smart energy-ef ficient clock synthesizer for duty-cycled sensor socs in 65 nm/28nm cmos, ” IEEE T ransactions on Cir cuits and Systems I: Re gular P apers , vol. 64, no. 9, pp. 2322–2333, Sept 2017. [35] A. Rahimi, I. Loi, M. R. Kakoee, and L. Benini, “ A Fully-Synthesizable Single-Cycle Interconnection Network for Shared-L1 Processor Clus- ters, ” in 2011 Design, Automation & T est in Eur ope . IEEE, Mar . 2011, pp. 1–6. [36] F . Conti, D. Palossi, A. Marongiu, D. Rossi, and L. Benini, “Enabling the heterogeneous accelerator model on ultra-low power microcontroller platforms, ” in 2016 Design, Automation T est in Europe Conference Exhibition (D ATE) , March 2016. [37] I. Hubara, M. Courbariaux, D. Soudry , R. El-Y aniv, and Y . Bengio, “Quantized Neural Networks: Training Neural Networks with Low Precision W eights and Activ ations, ” arXiv:1609.07061 [cs] , Sep. 2016. [38] A. S. Razavian, H. Azizpour , J. Sulli van, and S. Carlsson, “CNN features off-the-shelf: An astounding baseline for recognition, ” in IEEE Confer ence on Computer V ision and P attern Recognition W orkshops (CVPRW) , jun 2014. [39] L. Cecconi, S. Smets, L. Benini, and M. V erhelst, “Optimal tiling strat- egy for memory bandwidth reduction for cnns, ” in Advanced Concepts for Intelligent V ision Systems , J. Blanc-T alon, R. Penne, W . Philips, D. Popescu, and P . Scheunders, Eds. Cham: Springer International Publishing, 2017. [40] D. Palossi, J. Singh, M. Magno, and L. Benini, “T arget following on nano-scale unmanned aerial vehicles, ” in 2017 7th IEEE International W orkshop on Advances in Sensors and Interfaces (IW ASI) , June 2017, pp. 170–175. [41] P . Kumar , S. Garg, A. Singh, S. Batra, N. Kumar , and I. Y ou, “Mvo- based two-dimensional path planning scheme for providing quality of service in uav environment, ” IEEE Internet of Things Journal , 2018. [42] C. Y in, Z. Xiao, X. Cao, X. Xi, P . Y ang, and D. W u, “Offline and online search: Uav multiobjective path planning under dynamic urban en vironment, ” IEEE Internet of Things Journal , vol. 5, no. 2, April 2018. [43] D. Palossi, A. Marongiu, and L. Benini, “Ultra low-po wer visual odom- etry for nano-scale unmanned aerial vehicles, ” in Design, Automation T est in Eur ope Conference Exhibition (DA TE), 2017 , March 2017. [44] D. Falanga, A. Zanchettin, A. Simovic, J. Delmerico, and D. Scara- muzza, “V ision-based autonomous quadrotor landing on a moving platform, ” in 2017 IEEE International Symposium on Safety , Security and Rescue Robotics (SSRR) , Oct 2017. [45] J. F ¨ orster , M. Hamer, and R. D’Andrea, “System identification of the crazyflie 2.0 nano quadrocopter , ” B.S. thesis, 2015. [46] R. Mahony , V . Kumar, and P . Corke, “Multirotor aerial vehicles: Model- ing, estimation, and control of quadrotor, ” IEEE Robotics & Automation Magazine , vol. 19, no. 3, sep 2012. Daniele Palossi is a Ph.D. student at the Dept. of In- formation T echnology and Electrical Engineering at the Swiss Federal Institute of T echnology in Z ¨ urich (ETH Z ¨ urich). He received his B.S. and M.S. in Computer Science Engineering from the University of Bologna, Italy . In 2012 he spent six months as a research intern at ST Microelectronics, Agrate Brianza, Milano, working on 3D computer vision algorithms for the STM STHORM project. In 2013 he won a one-year research grant at the Univ ersity of Bologna, with a focus on design methodologies for high-performance embedded systems. He is currently working on energy- efficient algorithms for autonomous vehicles and adv anced driver assistance systems. Antonio Loquercio receiv ed the MSc de gree in Robotics, Systems and Control from ETH Z ¨ urich in 2017. He is working toward the Ph.D. degree in the Robotics and Perception Group at the Univ ersity of Z ¨ urich under the supervision of Prof. Davide Scara- muzza. His main interests are data-dri ven methods for perception and control in robotics. He is a recipient of the ETH Medal for outstanding master thesis (2017). Francesco Conti recei ved the Ph.D. degree from the University of Bologna in 2016 and is cur- rently a post-doctoral researcher at the Integrated Systems Laboratory , ETH Z ¨ urich, Switzerland, and the Energy-Efficient Embedded Systems Laboratory , Univ ersity of Bologna, Italy . His research focuses on energy-efficient multicore architectures and ap- plications of deep learning to low po wer digital systems. He has co-authored more than 30 papers in international conferences and journals, and he has been the recipient of three best paper awards (ASAP’14, EVW’14, ESWEEK’18) and the 2018 HiPEAC T ech Transfer A ward. Eric Flamand got his Ph.D. in Computer Science from INPG, France, in 1982. For the first part of his career, he work ed as a researcher with CNET and CNRS in France, on architectural automatic synthesis, design and architecture, compiler infras- tructure for highly constrained heterogeneous small parallel processors. He then held different technical management in the semiconductor industry , first with Motorola where he was in volved in the architecture definition and tooling of the StarCore DSP . Then with ST Microelectronics first being in charge of all the software development of the Nomadik Application Processor and then in charge of the P2012 corporate initiative aiming at the dev elopment of a many- core device. He is now co-founder and CTO of Greenwaves T echnologies a French-based startup developing an IoT processor deriv ed from the PULP project. He is also acting as a part-time research consultant for the ETH Z ¨ urich. Davide Scaramuzza (1980, Italy) recei ved the Ph.D. degree in robotics and computer vision from ETH Z ¨ urich, Z ¨ urich, Switzerland, in 2008, and a Post- doc at University of Pennsylvania, Philadelphia, P A, USA. He is a Professor of Robotics with Univ ersity of Z ¨ urich, where he does research at the intersec- tion of robotics, computer vision, and neuroscience. From 2009 to 2012, he led the European project sFly , which introduced the world’ s first autonomous navigation of microdrones in GPS-denied en viron- ments using visual-inertial sensors as the only sensor modality . He coauthored the book Introduction to Autonomous Mobile Robots (MIT Press). Dr . Scaramuzza received an SNSF-ERC Starting Grant, the IEEE Robotics and Automation Early Career A ward, and a Google Research A ward for his research contributions. Luca Benini holds the chair of Digital Circuits and Systems at ETH Z ¨ urich and is Full Professor at the Univ ersit ` a di Bologna. Dr . Benini’ s research interests are in energy-ef ficient system design for embedded and high-performance computing. He is also active in the area of energy-ef ficient smart sensors and ultra-low power VLSI design. He has published more than 1000 papers, fiv e books and se veral book chapters. He is a Fellow of the IEEE and the ACM and a member of the Academia Europaea. He is the recipient of the 2016 IEEE CAS Mac V an V alkenburg A ward.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment