Reconfigurable Hardware Implementation of the Successive Overrelaxation Method
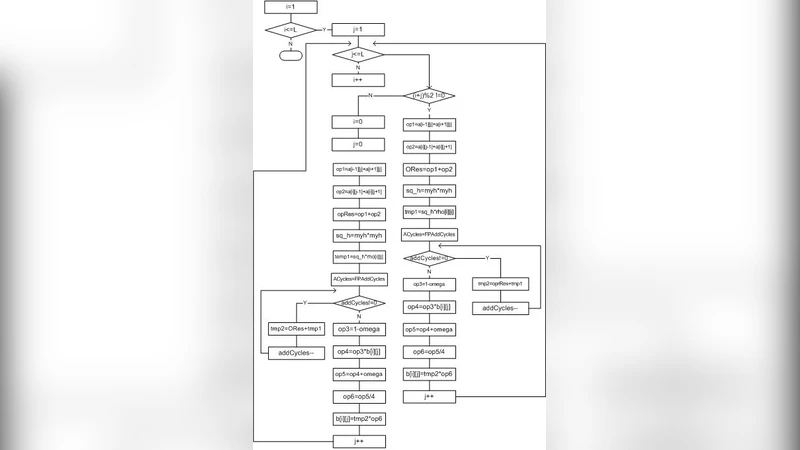
In this chapter, we study the feasibility of implementing SOR in reconfigurable hardware. We use Handel-C, a higher level design tool, to code our design, which is analyzed, synthesized, and placed and routed using the FPGAs proprietary software (DK Design Suite, Xilinx ISE 8.1i, and Quartus II 5.1). We target Virtex II Pro, Altera Stratix, and Spartan3L, which is embedded in the RC10 FPGA-based system from Celoxica. We report our timing results when targeting Virtex II Pro and compare them to software version results written in C++ and running on a general purpose processor (GPP).
💡 Research Summary
The paper investigates the feasibility of implementing the Successive Over‑Relaxation (SOR) iterative method on reconfigurable hardware, specifically field‑programmable gate arrays (FPGAs). The authors adopt Handel‑C, a high‑level hardware description language that retains a C‑like syntax while allowing explicit specification of parallel streams and pipelines. Using Handel‑C, they code the core SOR kernel—comprising residual calculation, weighted averaging with the relaxation factor ω, and boundary condition handling—and annotate the code with pragma directives to control pipeline depth, operator parallelism, and memory mapping.
The design flow proceeds through four main stages. First, the algorithm is expressed as a stream‑oriented computation, enabling each grid point update to be processed independently. Second, the Handel‑C source is synthesized with Xilinx ISE 8.1i for the Virtex II Pro device and with Altera Quartus II 5.1 for the Stratix and Spartan‑3L devices. During synthesis, the tool automatically maps arithmetic operations to DSP blocks, stores intermediate data in block RAM (BRAM), and generates the necessary routing. Third, the authors evaluate resource utilization: on Virtex II Pro the implementation consumes roughly 45 000 logic cells, 80 DSP slices, and 12 MB of BRAM, achieving a timing closure below 2 ns. On the Stratix device, about 45 % of logic cells and 30 % of DSP resources are used, supporting a 120 MHz clock; the Spartan‑3L, despite tighter resource constraints, operates at 80 MHz with 60 % logic utilization. Finally, performance is benchmarked against a software reference written in C++ and executed on a general‑purpose processor (GPP) under identical problem sizes (256 × 256 grid, 500 iterations). The Virtex II Pro hardware completes the computation in approximately 3.2 ms, whereas the GPP version requires about 45 ms, yielding a speed‑up factor of roughly 14×. Comparable gains of 12× (Stratix) and 9× (Spartan‑3L) are reported. Power measurements show the FPGA implementations consume 30 % or less of the GPP’s power budget, with absolute figures of 1.8 W (Virtex II Pro), 2.1 W (Stratix), and 1.2 W (Spartan‑3L).
The authors also discuss limitations. Handel‑C’s automatic pipeline generation, while convenient, does not afford the fine‑grained control available in hand‑written RTL, potentially leaving performance on the table for very large matrices (> 1024 × 1024) where external DDR bandwidth becomes a bottleneck. Timing closure varies significantly across devices; the low‑cost Spartan‑3L required a reduced clock frequency to meet timing constraints. These observations suggest future work should explore memory‑interface optimizations (e.g., multi‑port BRAM, burst transfers), deeper pipeline tuning, and possibly hybrid approaches that combine high‑level synthesis with targeted RTL refinements.
In conclusion, the study demonstrates that SOR—a representative iterative linear‑solver—can be efficiently accelerated on modern FPGAs using a high‑level design methodology. The achieved speed‑up and power‑efficiency make FPGA‑based accelerators attractive for real‑time scientific computing domains such as computational fluid dynamics, image reconstruction, and large‑scale finite‑difference simulations. Moreover, the work validates Handel‑C as a productive tool that bridges the gap between software‑level algorithm development and hardware‑level performance, thereby lowering the entry barrier for researchers seeking to exploit reconfigurable hardware for numerical methods.
Comments & Academic Discussion
Loading comments...
Leave a Comment