Inferring Javascript types using Graph Neural Networks
The recent use of `Big Code’ with state-of-the-art deep learning methods offers promising avenues to ease program source code writing and correction. As a first step towards automatic code repair, we implemented a graph neural network model that predicts token types for Javascript programs. The predictions achieve an accuracy above $90%$, which improves on previous similar work.
💡 Research Summary
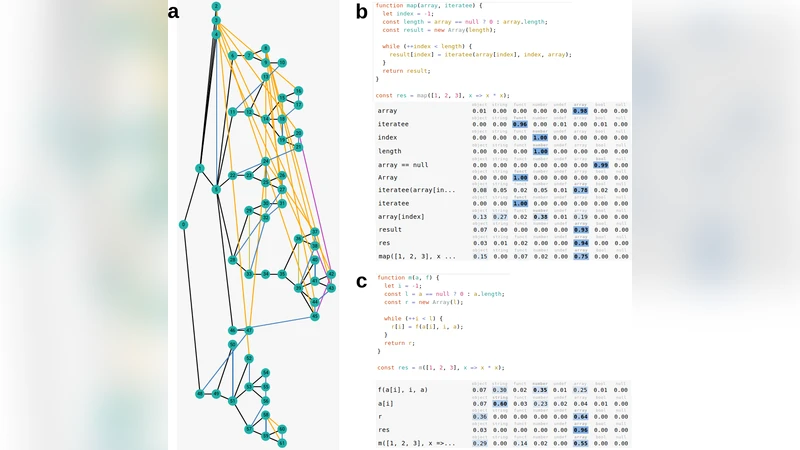
The paper tackles the problem of inferring static types for JavaScript, a dynamically‑typed language that lacks built‑in type annotations. Leveraging the “Big Code” paradigm, the authors collect a sizable corpus from GitHub (10,268 training files from 660 repositories and 3,539 test files from 136 repositories) and construct a graph representation for each source file. Nodes correspond to AST tokens; each node carries three kinds of features: (1) an AST node type (144 possible values), (2) a property descriptor (107 possible values), and (3) a string literal (up to 16 characters) that is embedded via a lookup table and processed by a GRU. Edges encode both syntactic relationships (AST child links) and semantic relationships (e.g., “defined‑by”, “next‑use”, “next‑sibling”), amounting to 96 distinct edge types, which are grouped into two broad categories for implementation simplicity.
Two graph neural network architectures are evaluated: a Graph Convolutional Network (GCN) and a Gated Graph Neural Network (GGNN). In the GCN, messages from each edge category are linearly transformed, summed, and passed through a ReLU activation. In the GGNN, messages are fed into a GRU cell that updates node states; weight matrices are tied across layers. Both models incorporate a “master node” that can read from and write to any other node, providing a mechanism for long‑range information flow. Dropout is applied not only to node features but also to the master‑node connections, creating stochastic skip‑connections that improve regularisation and enable Bayesian‑style uncertainty estimation.
Node embeddings are first passed through dedicated embedding layers (type embedding, property linear projection, string GRU) and concatenated. The concatenated vector then traverses several feed‑forward blocks consisting of batch‑norm, linear transformation, dropout, and ReLU. Training uses the Adam optimizer with a manually chosen initial learning rate; a scheduler reduces the learning rate by a factor of 0.1 upon validation plateaus. Mini‑batches contain up to 50 graphs or 20,000 nodes, whichever is reached first. The evaluation metric is micro‑averaged F1 score over tokens that have a ground‑truth type label (object, string, function, number, undefined, array, boolean, null). Tokens without a label are masked during training to avoid bias toward the “unknown” class; tokens with explicit type‑label correspondence are used for training but excluded from test evaluation to ensure a fair assessment.
Results show that the GGNN achieves 90.79 % micro‑F1 on the test set, while the GCN reaches 87.25 %. Both substantially outperform the 81 % reported by Raychev et al. (2015), which used older, non‑deep‑learning methods and focused only on function‑parameter types. Detailed analysis reveals that the “null” class suffers from lower recall due to its scarcity in the training data, and that removing variable‑name information degrades performance on certain tokens (e.g., array indexing), indicating the model’s reliance on lexical cues. The authors also discuss the potential of using dropout‑based Bayesian approximation to obtain calibrated uncertainty estimates, which could be integrated into a type‑mismatch warning system for developers.
In the discussion, the authors acknowledge that the task—predicting a small, fixed set of generic types—is relatively simple, which partly explains the high accuracy. They propose future work to expand the label set (e.g., adding RegExp, Date, user‑defined types), to increase the granularity of edge categories, and to incorporate additional semantic edges such as “return” relationships that have proven beneficial in prior work. They also plan to explore uncertainty‑aware predictions and to embed domain‑specific rules to further boost performance.
Overall, the paper demonstrates that representing source code as richly‑annotated graphs and applying state‑of‑the‑art graph neural networks can effectively infer JavaScript token types at scale, offering a practical component for IDEs, code review tools, and automated repair pipelines. The methodology is reproducible, the dataset will be released publicly, and the work opens several avenues for extending type inference to more complex and project‑specific type systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment