Analyzing the Impact of GDPR on Storage Systems
The recently introduced General Data Protection Regulation (GDPR) is forcing several companies to make significant changes to their systems to achieve compliance. Motivated by the finding that more than 30% of GDPR articles are related to storage, we investigate the impact of GDPR compliance on storage systems. We illustrate the challenges of retrofitting existing systems into compliance by modifying Redis to be GDPR-compliant. We show that despite needing to introduce a small set of new features, a strict real-time compliance (eg logging every user request synchronously) lowers Redis’ throughput by 20x. Our work reveals how GDPR allows compliance to be a spectrum, and what its implications are for system designers. We discuss the technical challenges that need to be solved before strict compliance can be efficiently achieved.
💡 Research Summary
This paper presents a comprehensive analysis of the technical and performance implications of the General Data Protection Regulation (GDPR) on data storage systems. Motivated by the finding that over 30% of GDPR articles directly pertain to storage, the research investigates what it means for a storage system to be GDPR-compliant, the performance costs involved, and the inherent design trade-offs.
The authors begin by dissecting the GDPR text, translating legal requirements into concrete technical features. They identify six core functionalities mandatory for a compliant storage system: 1) Timely Deletion (for the “right to be forgotten” and data retention limits), 2) Monitoring and Logging (for audit trails and breach notification), 3) Indexing via Metadata (to efficiently access, port, or delete all data related to a user or purpose), 4) Access Control, 5) Encryption (for data at rest and in transit), and 6) Managing Data Location (to comply with geographical restrictions).
A key conceptual contribution is framing GDPR compliance not as a binary state but as a spectrum across two dimensions: response time and capability. The “response time” dimension distinguishes between real-time compliance (synchronously executing GDPR tasks like logging) and eventual compliance (performing tasks asynchronously or in batches). The “capability” dimension differentiates full compliance (native system support for all features) from partial compliance (relying on external infrastructure or policies). This framework captures the intentional vagueness of the regulation, which allows for flexible implementation but creates design choices with significant consequences.
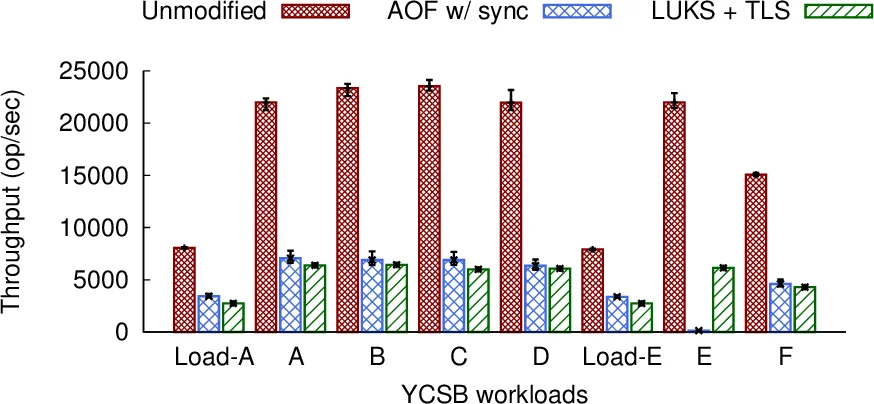
To empirically evaluate the impact, the authors retrofit Redis, a popular in-memory key-value store, into a GDPR-compliant version. While Redis natively supports some features like logging (via Append-Only File), it lacks native encryption and granular access control. The modifications involved approximately 120 lines of code and configuration changes, primarily to enable synchronous logging of all operations (not just writes) and to integrate third-party encryption modules (LUKS for data at rest, TLS for in-transit).
Performance benchmarking using YCSB reveals severe overheads. Enforcing strict, real-time compliance by synchronously logging every operation to disk reduced Redis’s throughput to just 5% of its original performance—a 20x slowdown. Relaxing this requirement to batch log writes every second improved throughput by 6x, but it still remained at only about 30% of the baseline. This starkly illustrates the performance trade-off inherent in the choice between real-time and eventual compliance; the latter offers better performance but carries the risk of losing audit logs in case of a crash.
The paper concludes by highlighting fundamental conflicts between GDPR principles and traditional storage system design goals optimized for performance, cost, and reliability. It identifies three major research challenges that must be addressed to make strict compliance efficient: 1) efficient and complete deletion of data across all replicas and backups, 2) high-performance logging for all data and control path operations, and 3) efficient metadata indexing to quickly query and manage large groups of data based on criteria like user ID or purpose. The work serves as a crucial reality check for system designers and a roadmap for future research in building privacy-preserving storage infrastructure.
Comments & Academic Discussion
Loading comments...
Leave a Comment