Multiplication is an important arithmetic operation that is frequently encountered in microprocessing and digital signal processing applications, and multiplication is physically realized using a multiplier. This paper discusses the physical implementation of many indicating asynchronous array multipliers, which are inherently elastic and modular and are robust to timing, process and parametric variations. We consider the physical realization of many indicating asynchronous array multipliers using a 32/28nm CMOS technology. The weak-indication array multipliers comprise strong-indication or weak-indication full adders, and strong-indication 2-input AND functions to realize the partial products. The multipliers were synthesized in a semi-custom ASIC design style using standard library cells including a custom-designed 2-input C-element. 4x4 and 8x8 multiplication operations were considered for the physical implementations. The 4-phase return-to-zero (RTZ) and the 4-phase return-to-one (RTO) handshake protocols were utilized for data communication, and the delay-insensitive dual-rail code was used for data encoding. Among several weak-indication array multipliers, a weak-indication array multiplier utilizing a biased weak-indication full adder and the strong-indication 2-input AND function is found to have reduced cycle time and power-cycle time product with respect to RTZ and RTO handshaking for 4x4 and 8x8 multiplications. Further, the 4-phase RTO handshaking is found to be preferable to the 4-phase RTZ handshaking for achieving enhanced optimizations of the design metrics.
Deep Dive into Indicating Asynchronous Array Multipliers.
Multiplication is an important arithmetic operation that is frequently encountered in microprocessing and digital signal processing applications, and multiplication is physically realized using a multiplier. This paper discusses the physical implementation of many indicating asynchronous array multipliers, which are inherently elastic and modular and are robust to timing, process and parametric variations. We consider the physical realization of many indicating asynchronous array multipliers using a 32/28nm CMOS technology. The weak-indication array multipliers comprise strong-indication or weak-indication full adders, and strong-indication 2-input AND functions to realize the partial products. The multipliers were synthesized in a semi-custom ASIC design style using standard library cells including a custom-designed 2-input C-element. 4x4 and 8x8 multiplication operations were considered for the physical implementations. The 4-phase return-to-zero (RTZ) and the 4-phase return-to-one (
Abstract—Multiplication is an important arithmetic operation
that is frequently encountered in microprocessing and digital signal
processing applications, and multiplication is physically realized
using a multiplier. This paper discusses the physical implementation
of many indicating asynchronous array multipliers, which are
inherently elastic and modular and are robust to timing, process and
parametric variations. We consider the physical realization of many
indicating asynchronous array multipliers using a 32/28nm CMOS
technology. The weak-indication array multipliers comprise strong-
indication or weak-indication full adders, and strong-indication 2-
input AND functions to realize the partial products. The multipliers
were synthesized in a semi-custom ASIC design style using standard
library cells including a custom-designed 2-input C-element. 4×4 and
8×8 multiplication operations were considered for the physical
implementations. The 4-phase return-to-zero (RTZ) and the 4-phase
return-to-one (RTO) handshake protocols were utilized for data
communication, and the delay-insensitive dual-rail code was used for
data encoding. Among several weak-indication array multipliers, a
weak-indication array multiplier utilizing a biased weak-indication
full adder and the strong-indication 2-input AND function is found to
have reduced cycle time and power-cycle time product with respect
to RTZ and RTO handshaking for 4×4 and 8×8 multiplications.
Further, the 4-phase RTO handshaking is found to be preferable to
the 4-phase RTZ handshaking for achieving enhanced optimizations
of the design metrics.
Keywords—Arithmetic circuits, Asynchronous circuits, Digital
circuits, Indication, Multiplier, CMOS, Standard cells.
I. INTRODUCTION
ULTIPLICATION is an important arithmetic operation that
is frequently encountered in microprocessing and digital
signal processing [1], [2]. References [3–9] discuss various
transistor-level and gate-level designs of the asynchronous
multipliers. However, a majority of these multipliers
correspond to the bundled-data handshake protocol, which has
separate request and acknowledge wires besides the data
bundle (i.e., data bus) and features a constant delay element
that governs data communication between the sender and the
receiver. Due to the fixed delay presumed for the data transfer
between
the
sender
and
the
receiver,
bundled-data
asynchronous multipliers are not robust when the presumed
delay gets exceeded, and they are neither indicating nor robust.
This work is supported by the Academic Research Fund Tier-2 research
award of the Ministry of Education, Republic of Singapore under Grant
MOE2017-T2-1-002.
P. Balasubramanian and D.L. Maskell are with the School of Computer
Science and Engineering, Nanyang Technological University, Singapore
639798 (e-mails: balasubramanian@ntu.edu.sg, asdouglas@ntu.edu.sg).
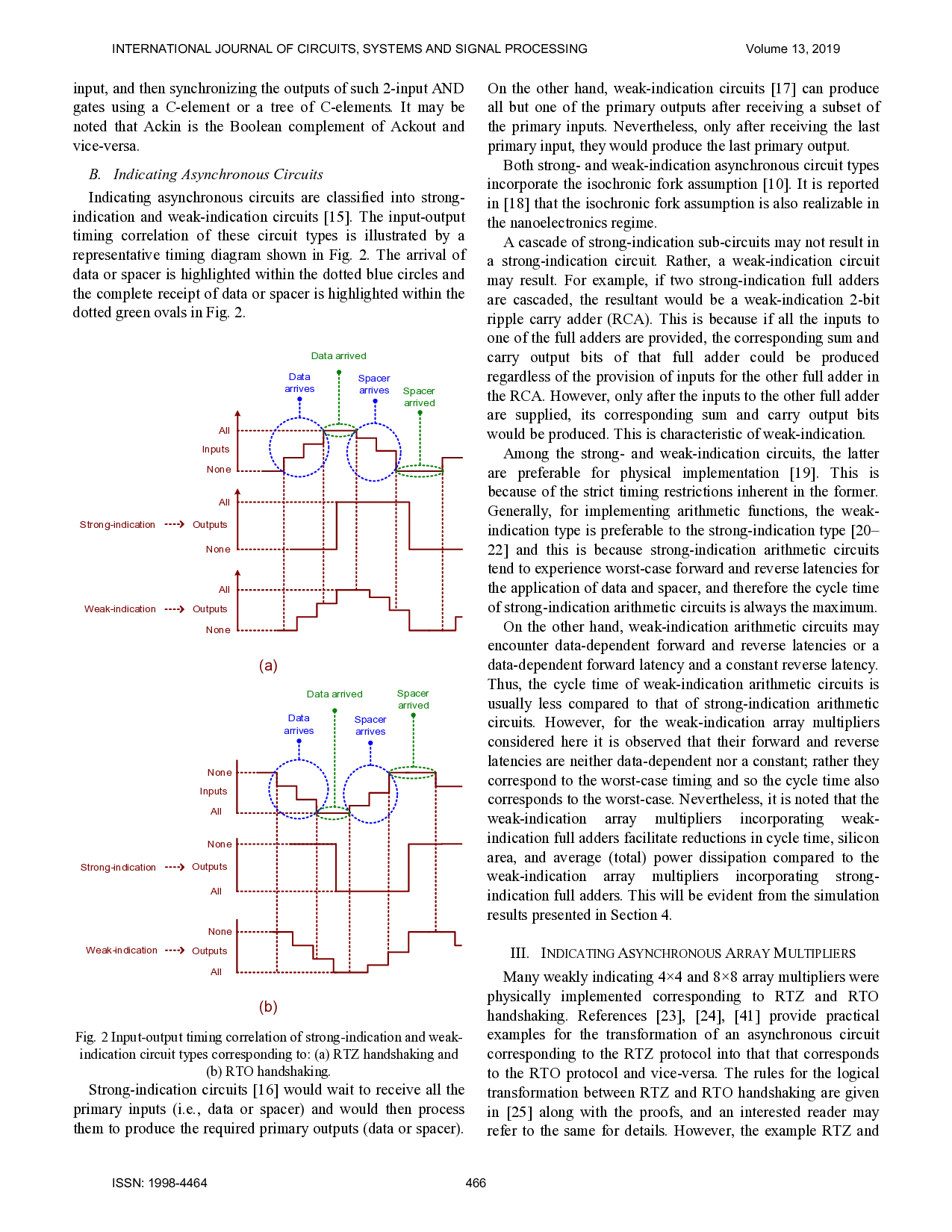
In this work, we consider the robust class of indicating
asynchronous multipliers whose product bits acknowledge the
arrival of all the primary inputs and the completion of internal
computation. Indicating asynchronous circuits are quasi-delay-
insensitive circuits, which are the practically realizable delay-
insensitive circuits which include the weakest compromise of
isochronic fork(s) [10]. All the wires branching out from an
isochronic node or junction are assumed to experience signal
transitions i.e., rising or falling concurrently. In this work, we
consider the array multiplier architecture for an example,
which
corresponds
to
the
well-known
shift-and-add
multiplication approach. We realize indicating asynchronous
realizations of 4×4 and 8×8 array multipliers, which utilize
asynchronous components pertaining to strong-indication and
weak-indication asynchronous logic design methods.
The rest of the article is organized into 4 sections. Section 2
gives background information about the design of indicating
asynchronous circuits. Section 3 discusses various indicating
asynchronous implementations of the 4×4 and 8×8 array
multipliers by following the semi-custom ASIC design style.
Section 4 presents the design metrics estimated for the array
multipliers based on physical realization using a 32/28nm
CMOS process. The (normalized) power-cycle time product of
the multipliers is also provided. Finally, some conclusions and
a scope for further work are mentioned in Section 5.
II. INDICATING ASYNCHRONOUS CIRCUITS – A BACKGROUND
A. Data Encoding and Handshaking
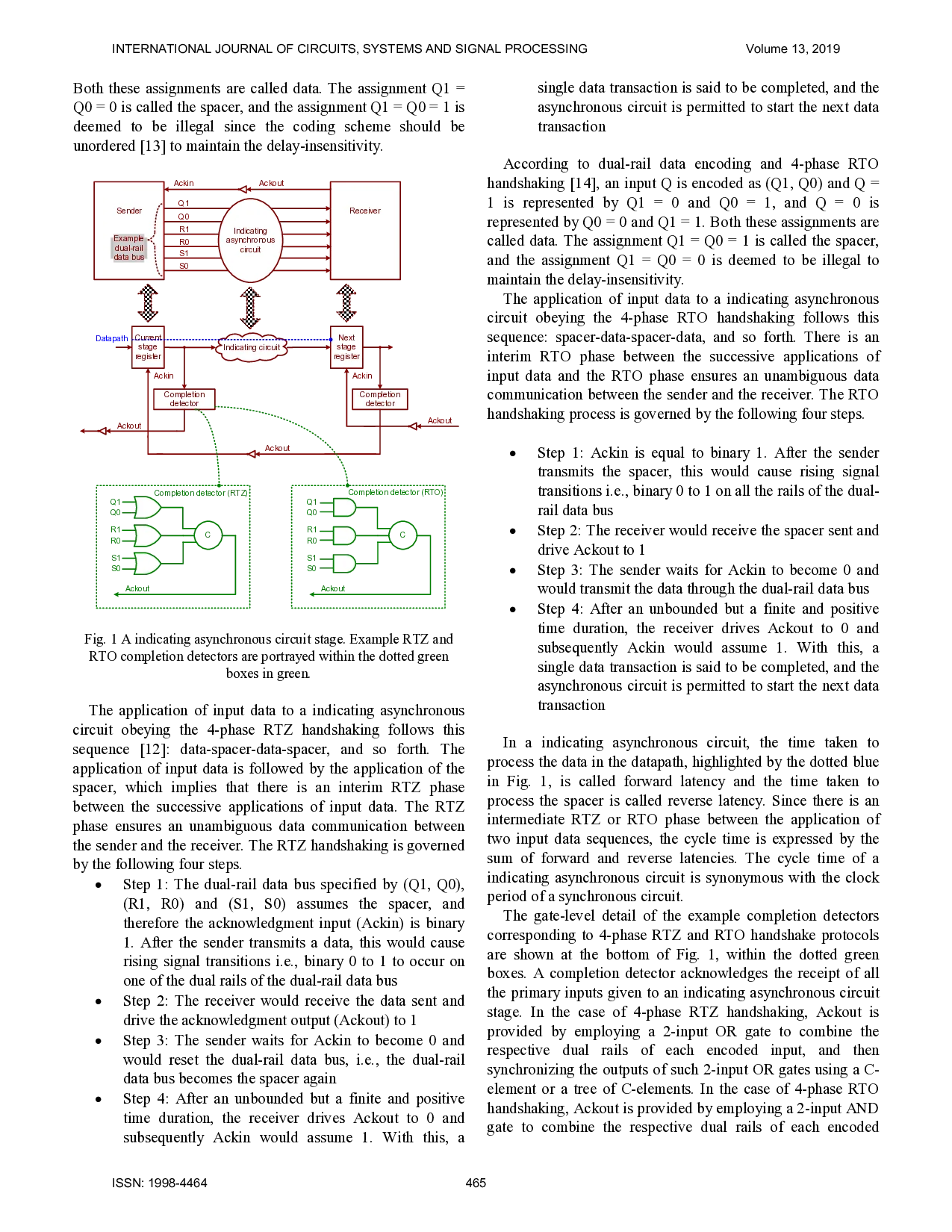
The schematic of an indicating asynchronous circuit stage is
shown in Fig. 1, which is correlated with the sender-receiver
analogy. In Fig. 1, the current stage and the next stage registers
are analogous to the sender and the receiver, and the indicating
asynchronous circuit is sandwiched between the current stage
and the next stage register banks. The register bank comprises
a series of registers, with one register allotted for each of
…(Full text truncated)…
This content is AI-processed based on ArXiv data.