Semantic Segmentation of Seismic Images
Almost all work to understand Earth’s subsurface on a large scale relies on the interpretation of seismic surveys by experts who segment the survey (usually a cube) into layers; a process that is very time demanding. In this paper, we present a new deep neural network architecture specially designed to semantically segment seismic images with a minimal amount of training data. To achieve this, we make use of a transposed residual unit that replaces the traditional dilated convolution for the decode block. Also, instead of using a predefined shape for up-scaling, our network learns all the steps to upscale the features from the encoder. We train our neural network using the Penobscot 3D dataset; a real seismic dataset acquired offshore Nova Scotia, Canada. We compare our approach with two well-known deep neural network topologies: Fully Convolutional Network and U-Net. In our experiments, we show that our approach can achieve more than 99 percent of the mean intersection over union (mIOU) metric, outperforming the existing topologies. Moreover, our qualitative results show that the obtained model can produce masks very close to human interpretation with very little discontinuity.
💡 Research Summary
The paper addresses the labor‑intensive task of manually segmenting seismic volumes into geological layers (horizons) by proposing two novel deep neural network architectures—Danet‑FCN2 and Danet‑FCN3—specifically engineered for semantic segmentation of seismic images when only a small amount of labeled data is available. The authors begin by reviewing prior work in seismic facies analysis, noting that earlier approaches relied on classical computer‑vision techniques (e.g., GLCM, LBP) or on generic deep learning models such as FCN‑8, FCN‑16, and U‑Net, which either lacked detailed architectural analysis or required substantial training data.
The experimental dataset is the publicly available Penobscot 3D seismic survey from offshore Nova Scotia, Canada. The volume contains 601 inline and 481 crossline slices; the authors use only the inline slices, discard corrupted images, and end up with 459 high‑quality slices. Expert geologists annotated seven horizons, which the authors merge into seven classes (by combining two thin layers). To make the problem tractable for deep learning, the images are rescaled from a floating‑point range of roughly –30 000 to 33 000 to an 8‑bit grayscale range (0‑255) and then divided into overlapping tiles of size 80 × 120 and 128 × 128 pixels. The tiling strategy reduces memory requirements and enables training on very few slices (as few as five).
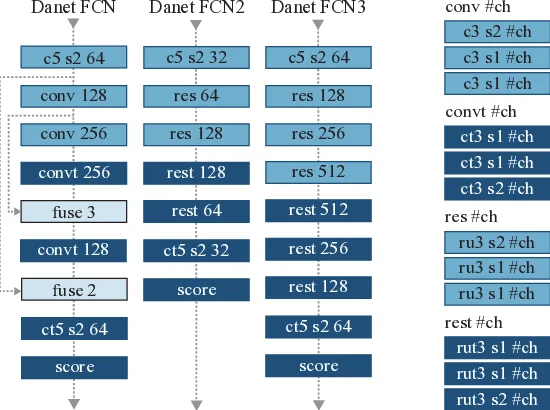
Architecturally, both models adopt a residual‑block encoder inspired by ResNet, but they replace the conventional decoder (which typically uses fixed up‑sampling such as bilinear interpolation or dilated convolutions) with a “transposed residual unit.” This unit consists of a transposed convolution followed by batch normalization, a ReLU activation, and a residual shortcut that adds the input to the transformed output. By learning the up‑sampling operation, the network can produce smoother, more coherent boundaries compared with fixed up‑sampling. Moreover, because each residual block already contains an internal shortcut, the authors argue that explicit skip connections between encoder and decoder (as in U‑Net) become unnecessary, reducing overall parameter count.
Danet‑FCN2 is the compact version: it contains a modest number of residual blocks and filters, making it fast to train and suitable for limited‑data regimes. Danet‑FCN3 expands the architecture with additional residual blocks and a larger number of filters, aiming for higher capacity when more training data is available.
The experimental protocol varies the number of training slices (100, 13, 9, and 5) to simulate realistic constraints in the oil‑and‑gas industry where labeling is expensive. Models are trained with the Adam optimizer, cross‑entropy loss, and standard data augmentation (overlapping tiles). Evaluation uses mean Intersection‑over‑Union (mIoU) and pixel accuracy. Results show that Danet‑FCN2 consistently achieves mIoU > 99 % even with only five training slices, outperforming baseline FCN‑8, FCN‑16, and U‑Net, which plateau around 95 % under the same conditions. Danet‑FCN3 matches or slightly exceeds Danet‑FCN2 when 100 slices are used, but its performance degrades more sharply when training data is scarce, indicating over‑parameterization for the limited‑data scenario. Training speed is also highlighted: Danet‑FCN2 converges 30‑40 % faster than U‑Net due to its streamlined architecture.
The authors discuss the implications of their findings. The transposed residual decoder demonstrates that learning the up‑sampling process can reduce discontinuities at layer boundaries—a critical factor for geological interpretation. The residual‑only design simplifies the network while preserving the benefits of skip connections implicitly. However, the study is limited to a single seismic dataset and to 2‑D inline slices; generalization to other geological settings, 3‑D volumetric segmentation, or real‑time field deployment remains to be validated. Additionally, transposed convolutions are computationally heavier than dilated convolutions, which may affect deployment on resource‑constrained hardware.
In conclusion, the paper contributes a lightweight, high‑performance segmentation framework tailored for seismic imaging under severe labeling constraints. By integrating transposed residual units and a residual‑only encoder‑decoder pipeline, the proposed models achieve state‑of‑the‑art accuracy with minimal training data, offering a practical tool for geoscientists and a methodological blueprint for other domains where annotated data are scarce. Future work could explore multi‑scale fusion, 3‑D extensions, and hardware‑aware optimizations to broaden applicability.
Comments & Academic Discussion
Loading comments...
Leave a Comment