Densifying Assumed-sparse Tensors: Improving Memory Efficiency and MPI Collective Performance during Tensor Accumulation for Parallelized Training of Neural Machine Translation Models
Neural machine translation - using neural networks to translate human language - is an area of active research exploring new neuron types and network topologies with the goal of dramatically improving machine translation performance. Current state-of-the-art approaches, such as the multi-head attention-based transformer, require very large translation corpuses and many epochs to produce models of reasonable quality. Recent attempts to parallelize the official TensorFlow “Transformer” model across multiple nodes have hit roadblocks due to excessive memory use and resulting out of memory errors when performing MPI collectives. This paper describes modifications made to the Horovod MPI-based distributed training framework to reduce memory usage for transformer models by converting assumed-sparse tensors to dense tensors, and subsequently replacing sparse gradient gather with dense gradient reduction. The result is a dramatic increase in scale-out capability, with CPU-only scaling tests achieving 91% weak scaling efficiency up to 1200 MPI processes (300 nodes), and up to 65% strong scaling efficiency up to 400 MPI processes (200 nodes) using the Stampede2 supercomputer.
💡 Research Summary
The paper addresses a critical bottleneck in distributed training of Transformer‑based neural machine translation (NMT) models: excessive memory consumption and poor MPI collective performance caused by TensorFlow’s handling of “assumed‑sparse” gradients. In the standard TensorFlow implementation, gradients from the embedding layer (which are naturally sparse) and from the projection matrix (which are dense) are both converted into IndexedSlices objects. Consequently, TensorFlow’s gradient accumulation algorithm treats the whole set of gradients as sparse, performing a gather‑style concatenation across all workers. This leads to massive MPI message buffers—exceeding 11 GB in the authors’ experiments—and quickly triggers out‑of‑memory (OOM) errors once more than 32 MPI processes are used, severely limiting scalability.
To solve this, the authors modify Horovod’s DistributedOptimizer by forcing all gradients to be dense tensors (using the sparse_as_dense=True flag). This simple change forces TensorFlow to use a reduction‑based accumulation (MPI Reduce) instead of a gather. The impact is dramatic: memory required for gradient exchange drops from 11.4 GB to 139 MB (an 82× reduction), and the time spent in the accumulation operation falls from 4.32 seconds to 0.169 seconds (≈25× speed‑up). By shrinking the per‑process memory footprint, the authors can increase both the number of MPI processes and the per‑process batch size without hitting OOM, enabling far larger scale‑out experiments.
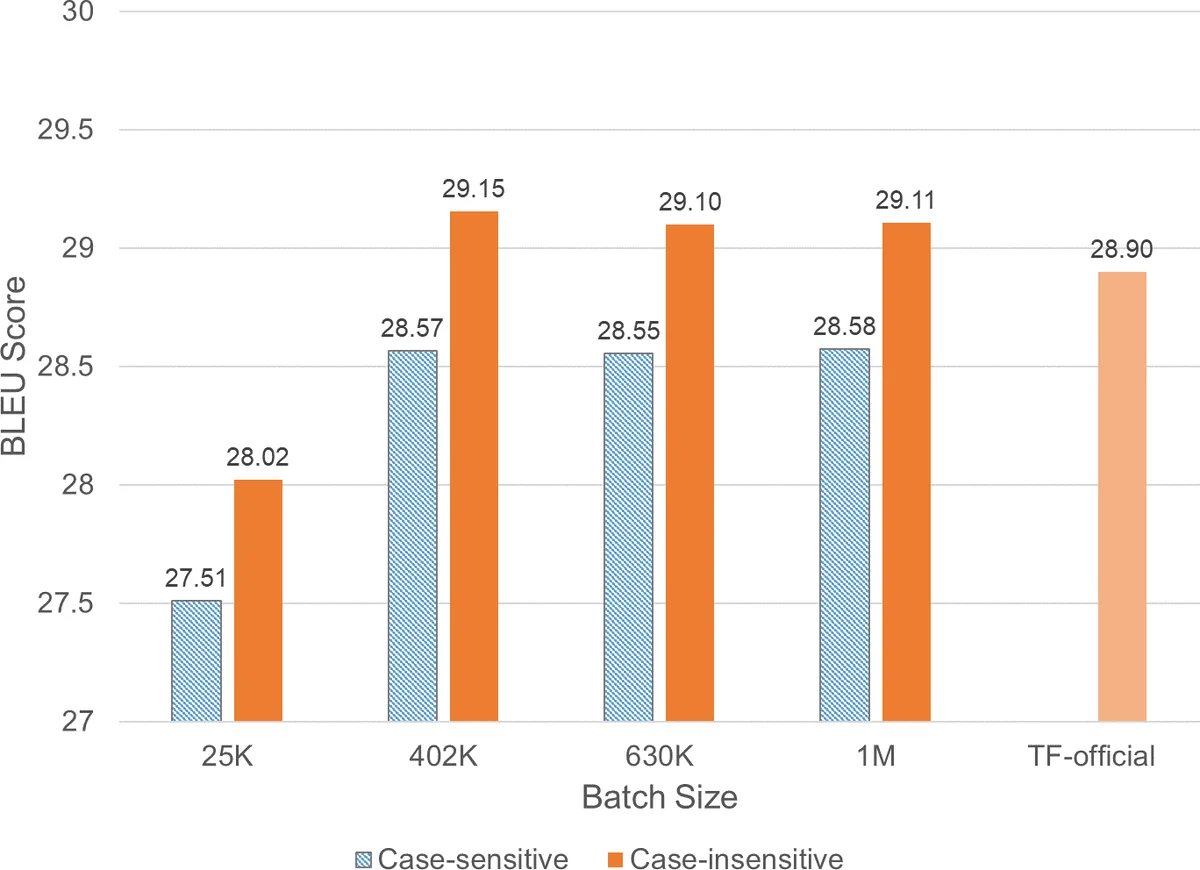
The experimental evaluation uses two large‑scale HPC systems: the Dell EMC “Zenith” cluster (dual Intel Xeon Gold 6148 CPUs, 100 Gbps Omni‑Path interconnect) and the Texas Advanced Computing Center’s Stampede2 supercomputer (dual Intel Xeon Platinum 8160 CPUs, also 100 Gbps Omni‑Path). Both systems run TensorFlow 1.12 with Intel MKL optimizations and Horovod 0.15.2. The authors train a standard Transformer on the WMT‑17 English‑German corpus (4.5 M sentence pairs) and evaluate translation quality on newstest2014 using BLEU, matching the official TensorFlow benchmark.
Weak scaling results show that with the dense‑gradient strategy the system maintains near‑linear scaling up to 1200 MPI processes (300 nodes) on Zenith, achieving 91.5 % efficiency (versus ~75 % with the default sparse strategy). Throughput rises from ~3.6 k tokens/s on a single node to over 274 k tokens/s on 300 nodes, with a global batch size of 6 M tokens. Strong scaling experiments fix the global batch size at 819 200 tokens (producing a BLEU of 27.5) and scale from 16 to 200 nodes on Zenith and up to 256 nodes on Stampede2. The authors report up to an 8× increase in throughput, reducing training time from roughly one month on a single node to under six hours on 200 nodes—a 121× speed‑up. Strong‑scaling efficiency remains respectable (≈65 % at 400 MPI processes on Stampede2), demonstrating that the memory‑saving densification also benefits cases where per‑worker batch size shrinks.
The paper also provides a clear algorithmic description (Algorithm 1) of TensorFlow’s original accumulation logic, a code snippet (Listing 1) showing how Horovod converts IndexedSlices to tensors, and detailed performance graphs (Figures 3‑10) that illustrate the memory and time reductions. The authors note that the sparse_as_dense option has been incorporated into Horovod 0.15.2, making the technique readily available to the community. They argue that any model with mixed sparse/dense gradients can benefit from the same approach, opening the door to more efficient large‑scale training on CPU‑only HPC resources.
In summary, by forcibly densifying assumed‑sparse tensors and switching from MPI gather to MPI reduce, the authors achieve an 82× reduction in gradient communication size, a 25× speed‑up in accumulation, and enable Transformer training at unprecedented scale on commodity CPU clusters, all while preserving translation quality. This work provides a practical, low‑effort solution for researchers facing OOM and poor scaling in distributed deep‑learning workloads.
Comments & Academic Discussion
Loading comments...
Leave a Comment