End-to-End Sound Source Separation Conditioned On Instrument Labels
Can we perform an end-to-end music source separation with a variable number of sources using a deep learning model? We present an extension of the Wave-U-Net model which allows end-to-end monaural source separation with a non-fixed number of sources. Furthermore, we propose multiplicative conditioning with instrument labels at the bottleneck of the Wave-U-Net and show its effect on the separation results. This approach leads to other types of conditioning such as audio-visual source separation and score-informed source separation.
💡 Research Summary
The paper addresses the problem of monaural music source separation when the number of sources is not fixed in advance. Building on the Wave‑U‑Net architecture—a 1‑D convolutional encoder‑decoder network that operates directly on raw waveforms—the authors propose two extensions. The first, called Exp‑Wave‑U‑Net, fixes the output dimensionality to the total number of distinct instruments present in the dataset (13 in the URMP corpus) and trains the network to emit a silent audio track for any instrument that is absent in a given mixture. This allows a single model to handle mixtures ranging from duets to quintets without retraining separate models for each possible source count.
The second extension, CExp‑Wave‑U‑Net, adds a conditioning mechanism that incorporates instrument presence information. A binary label vector indicating which instruments are playing is multiplied element‑wise with the bottleneck representation (the most compressed latent space) of the Wave‑U‑Net. This multiplicative “middle‑fusion” conditioning amplifies the latent features of active instruments while suppressing those of inactive ones, thereby guiding the decoder toward more accurate separation. Early‑fusion (at the encoder input) and late‑fusion (after the decoder) were considered but rejected due to higher memory/computational costs; additive bias and concatenation conditioning are left for future work.
Experiments were conducted on the University of Rochester Musical Performance (URMP) dataset, which contains 44 classical chamber pieces (duets, trios, quartets, quintets) performed by 13 instruments. The authors used 33 pieces for training/validation and 11 for testing. As a baseline they employed an informed Non‑Negative Matrix Factorization (NMF) method that uses pre‑learned timbre templates for each instrument. All models were implemented in TensorFlow, trained on a single Google Cloud TPU for 200 k steps (≈23 h), and benefited from half‑precision training to accelerate computation.
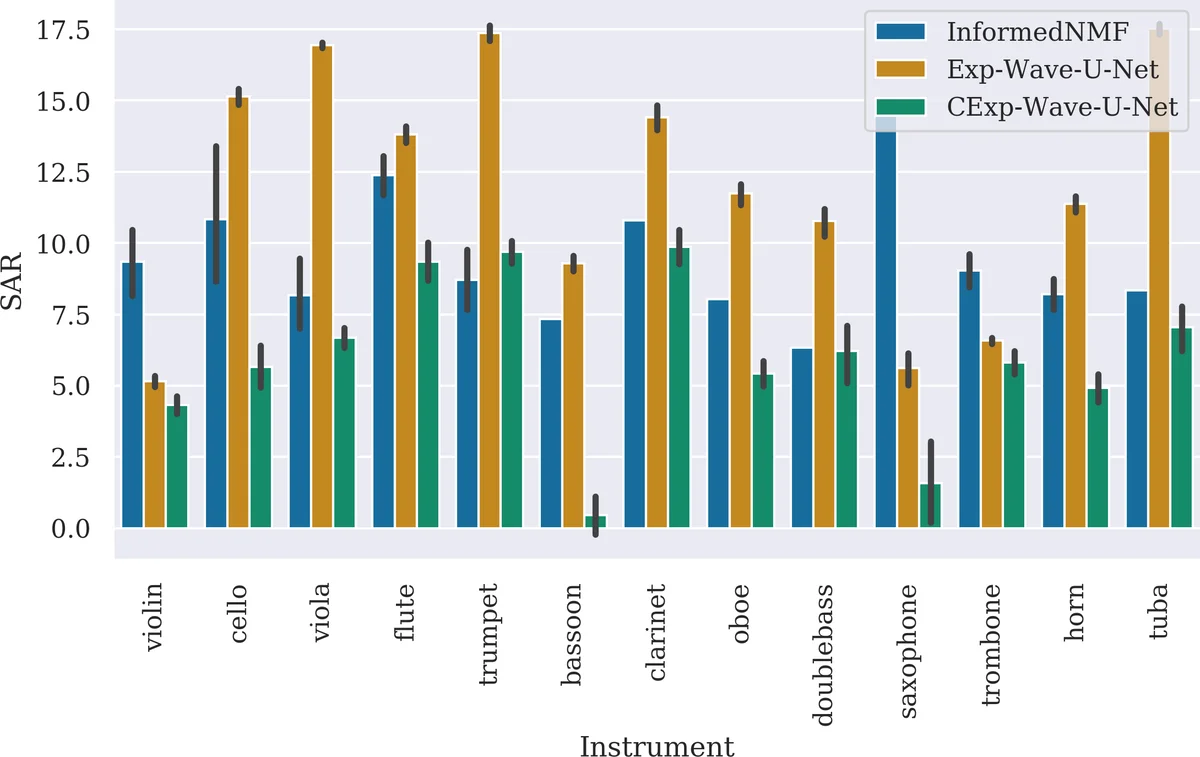
Performance was evaluated with standard blind source separation metrics: Source‑to‑Distortion Ratio (SDR), Source‑to‑Interference Ratio (SIR), and Source‑to‑Artifacts Ratio (SAR). The informed NMF achieved the highest average SDR (−0.16 dB) but lagged behind the deep models in SIR and SAR. Exp‑Wave‑U‑Net obtained the best SAR (12.18 dB) indicating fewer artifacts, while CExp‑Wave‑U‑Net achieved the best SIR (2.16 dB) and competitive SDR (−1.37 dB). Notably, as the number of simultaneous instruments increased from 2 to 4, the degradation in SDR and SIR was much less severe for the conditioned model than for the unconditioned model or the NMF baseline, demonstrating the robustness of label conditioning in more complex mixtures. Instrument‑wise analysis showed that CExp‑Wave‑U‑Net performed especially well on low‑frequency instruments such as tuba, double‑bass, saxophone, and viola, whereas its SAR was generally lower than the other methods, suggesting more residual artifacts.
The authors acknowledge several limitations: (1) the model cannot separate multiple parts of the same instrument (e.g., two violins) because each output channel is tied to a distinct instrument class; (2) the binary label does not convey dynamic playing intensity or articulation; (3) standard BSS metrics are undefined for silent sources, making it difficult to quantify how well the network suppresses non‑present instruments.
Future work will explore alternative conditioning schemes (additive bias, concatenation), integrate visual cues from video streams to obtain both instrument identity and playing state, and develop mechanisms (e.g., attention) to disentangle multiple instances of the same instrument. The authors also plan to release code and audio samples to facilitate reproducibility.
In summary, this paper demonstrates that a modest extension of Wave‑U‑Net combined with multiplicative label conditioning can handle variable‑source‑count music separation in an end‑to‑end fashion, achieving performance comparable to or better than a strong timbre‑informed NMF baseline while requiring far less prior information at inference time. This opens avenues for more flexible, multimodal source separation systems applicable to real‑world music recordings.
Comments & Academic Discussion
Loading comments...
Leave a Comment