Learned human-agent decision-making, communication and joint action in a virtual reality environment
Humans make decisions and act alongside other humans to pursue both short-term and long-term goals. As a result of ongoing progress in areas such as computing science and automation, humans now also interact with non-human agents of varying complexity as part of their day-to-day activities; substantial work is being done to integrate increasingly intelligent machine agents into human work and play. With increases in the cognitive, sensory, and motor capacity of these agents, intelligent machinery for human assistance can now reasonably be considered to engage in joint action with humans—i.e., two or more agents adapting their behaviour and their understanding of each other so as to progress in shared objectives or goals. The mechanisms, conditions, and opportunities for skillful joint action in human-machine partnerships is of great interest to multiple communities. Despite this, human-machine joint action is as yet under-explored, especially in cases where a human and an intelligent machine interact in a persistent way during the course of real-time, daily-life experience. In this work, we contribute a virtual reality environment wherein a human and an agent can adapt their predictions, their actions, and their communication so as to pursue a simple foraging task. In a case study with a single participant, we provide an example of human-agent coordination and decision-making involving prediction learning on the part of the human and the machine agent, and control learning on the part of the machine agent wherein audio communication signals are used to cue its human partner in service of acquiring shared reward. These comparisons suggest the utility of studying human-machine coordination in a virtual reality environment, and identify further research that will expand our understanding of persistent human-machine joint action.
💡 Research Summary
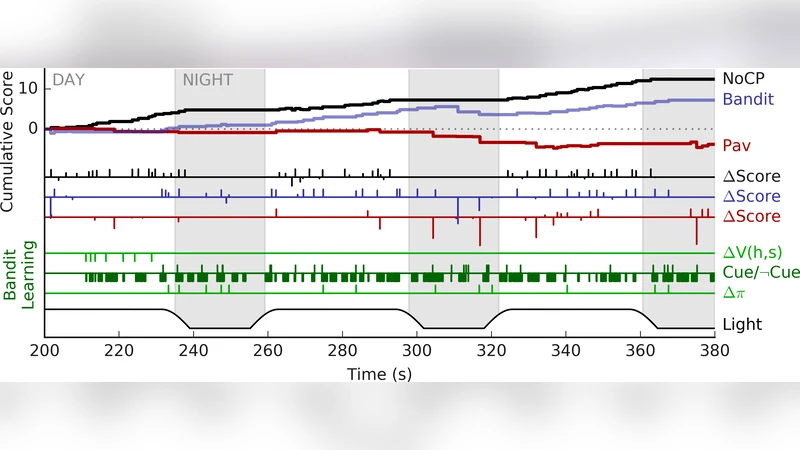
This paper investigates real‑time joint action between a human “pilot” and a learning machine “copilot” using a custom virtual‑reality (VR) foraging task. The authors motivate the study by noting that modern intelligent agents are increasingly embedded in everyday human activities, yet the mechanisms that enable persistent, adaptive human‑machine collaboration remain under‑explored. To fill this gap, they built a VR environment in which six colored “fruit” objects appear on a floating platform. Each fruit follows a deterministic ripening cycle: its hue and saturation change over time, and a sinusoidal reward function maps the fruit’s age to points (positive or negative). The environment alternates between “day” (full lighting) and “night” (darkness), during which the human can no longer perceive color and must rely on auditory cues.
The experiment involved a single participant (one of the co‑authors) who completed three experimental blocks, each containing three 180‑second trials. In each trial the participant could (1) harvest fruit with the right hand controller to gain or lose points, or (2) “teach” the copilot by contacting fruit with the left hand controller, which updates the copilot’s internal value function V(h, s) without affecting the participant’s score. Three conditions were tested:
- No Copilot (NoCP) – The participant acts alone; left‑hand teaching has no effect.
- Pavlovian Control (Pav) – The copilot learns V(h, s) via supervised updates from teaching actions. At every time step it queries V for each fruit; if V > 0 it emits a fruit‑specific audio cue. This is a fixed, prediction‑driven feedback loop (Pavlovian).
- Bandit (Contextual Bandit Policy) – The copilot also learns V, but instead of deterministic cue emission it maintains a stochastic policy π(V). When V predicts a positive outcome, the copilot decides probabilistically whether to cue the participant. The policy is updated using a contextual bandit algorithm based on the actual points the participant receives after harvesting. Positive outcomes increase the probability of cueing in similar states; negative outcomes decrease it.
The authors measured total points, night‑time versus day‑time performance, fruit‑location bias, and learning dynamics (ΔV and Δπ). Key findings include:
- Both copilot conditions increased night‑time foraging compared with NoCP, indicating that auditory cues can compensate for visual loss.
- The Pavlovian copilot produced more “mistakes” (harvesting low‑value fruit) because its cues were fixed and sometimes misleading.
- The Bandit copilot, despite an initial learning curve, yielded the highest net score when negative‑point events were excluded, suggesting that adaptive cueing can eventually support more efficient joint action.
- Teaching actions (ΔV) provided a window into the human’s pattern‑learning process, showing that the participant gradually inferred the hidden reward sinusoid.
The discussion emphasizes two critical challenges for human‑machine joint action: (a) timing of cues relative to human actions, and (b) credit assignment across delayed reward signals. The authors argue that a gradually learned policy (Bandit) is more appropriate than a static Pavlovian mapping, and they propose extending the copilot architecture to incorporate additional modalities such as head pose, gaze direction, and richer sensory streams.
Limitations are acknowledged: the study involved only one participant, the experimental duration was short, and the copilot’s learning algorithms were relatively simple (linear value updates and a basic contextual bandit). Consequently, statistical generalization is limited, and the findings serve primarily as a proof‑of‑concept.
Future work suggested includes scaling to multiple participants, integrating multimodal perception for more precise cue timing, exploring long‑term adaptation across sessions, and transferring the framework from VR to physical robots or augmented‑reality platforms.
In conclusion, the paper demonstrates that a closed‑loop human‑agent learning system can be instantiated in a VR setting: the human learns the hidden reward structure, teaches the agent, and the agent learns to predict and cue the human. The results indicate that adaptive, policy‑based communication can enhance joint performance, especially under sensory constraints, and that VR provides a flexible testbed for systematic investigation of human‑machine joint action.
Comments & Academic Discussion
Loading comments...
Leave a Comment