Many-to-Many Voice Conversion with Out-of-Dataset Speaker Support
We present a Cycle-GAN based many-to-many voice conversion method that can convert between speakers that are not in the training set. This property is enabled through speaker embeddings generated by a neural network that is jointly trained with the Cycle-GAN. In contrast to prior work in this domain, our method enables conversion between an out-of-dataset speaker and a target speaker in either direction and does not require re-training. Out-of-dataset speaker conversion quality is evaluated using an independently trained speaker identification model, and shows good style conversion characteristics for previously unheard speakers. Subjective tests on human listeners show style conversion quality for in-dataset speakers is comparable to the state-of-the-art baseline model.
💡 Research Summary
The paper introduces a many‑to‑many voice conversion system that can handle speakers not seen during training, a capability the authors refer to as “out‑of‑dataset speaker support.” The core of the system is a Cycle‑GAN architecture augmented with a learnable speaker embedding extractor (Feature Extractor, FE). Unlike prior works that condition the generator on a one‑hot speaker identifier, the FE processes a short utterance from any speaker and outputs a continuous embedding vector (1 × 8 × 8) that captures the speaker’s style. This embedding is concatenated with the latent representation of the source utterance inside the generator’s bottleneck, enabling the generator to synthesize the source content in the target speaker’s style.
The model consists of three jointly trained components:
-
Feature Extractor (FE) – a 2‑D convolutional neural network that maps mel‑spectrograms to speaker embeddings. It is trained on a large, diverse set of speakers (251 speakers from Librispeech train‑clean‑100) and learns to produce discriminative embeddings that generalize to unseen speakers.
-
Generator (G) – also a 2‑D CNN with a U‑Net‑like skip‑connection architecture. It receives the source mel‑spectrogram and the target speaker embedding, merges them in the bottleneck, and outputs a converted mel‑spectrogram.
-
Discriminator (D) – a single multi‑class discriminator that predicts 2 N logits (real/fake for each of the N training speakers). It processes three temporal patches of different lengths to capture both short‑term and longer‑term patterns.
Training uses the standard Cycle‑GAN losses: an adversarial loss for G and D (L_G, L_D), and a cycle‑consistency L1 loss (L_cycle) to enforce content preservation. The adversarial loss is formulated for the multi‑class setting, encouraging G to generate samples that D classifies as “real” for the target speaker.
Key innovations
- Replacing one‑hot speaker IDs with learned continuous embeddings, which enables the system to infer embeddings for speakers never seen during training.
- Using a single multi‑class discriminator instead of two separate discriminators, simplifying the architecture while still providing strong adversarial feedback.
- Demonstrating scalability to over 290 speakers (251 training + 40 test) – far more than prior many‑to‑many Cycle‑GAN works that typically handle 4–5 speakers.
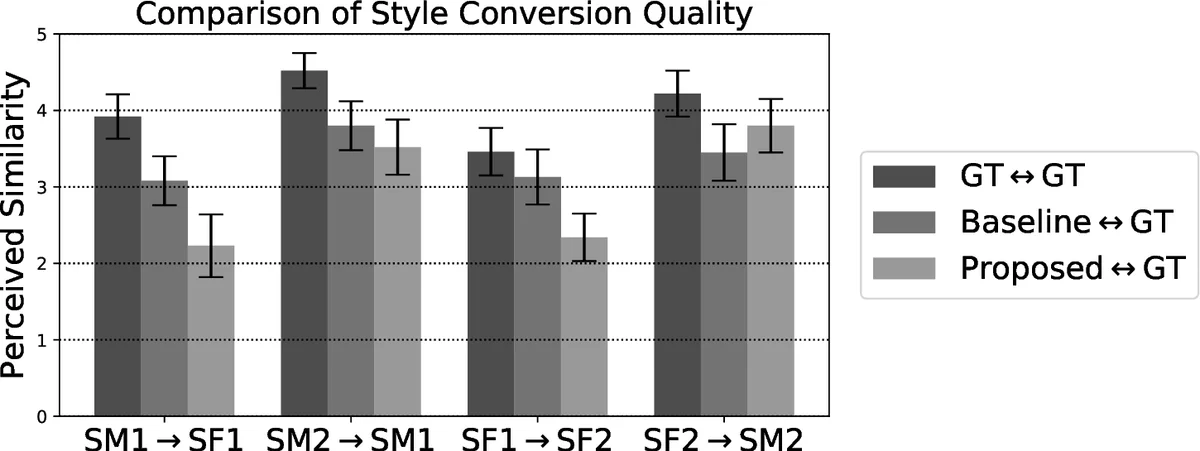
Experimental evaluation
- In‑dataset speakers: The authors compare their model against the state‑of‑the‑art Cycle‑GAN baseline from
Comments & Academic Discussion
Loading comments...
Leave a Comment