Caveats in Generating Medical Imaging Labels from Radiology Reports
Acquiring high-quality annotations in medical imaging is usually a costly process. Automatic label extraction with natural language processing (NLP) has emerged as a promising workaround to bypass the need of expert annotation. Despite the convenience, the limitation of such an approximation has not been carefully examined and is not well understood. With a challenging set of 1,000 chest X-ray studies and their corresponding radiology reports, we show that there exists a surprisingly large discrepancy between what radiologists visually perceive and what they clinically report. Furthermore, with inherently flawed report as ground truth, the state-of-the-art medical NLP fails to produce high-fidelity labels.
💡 Research Summary
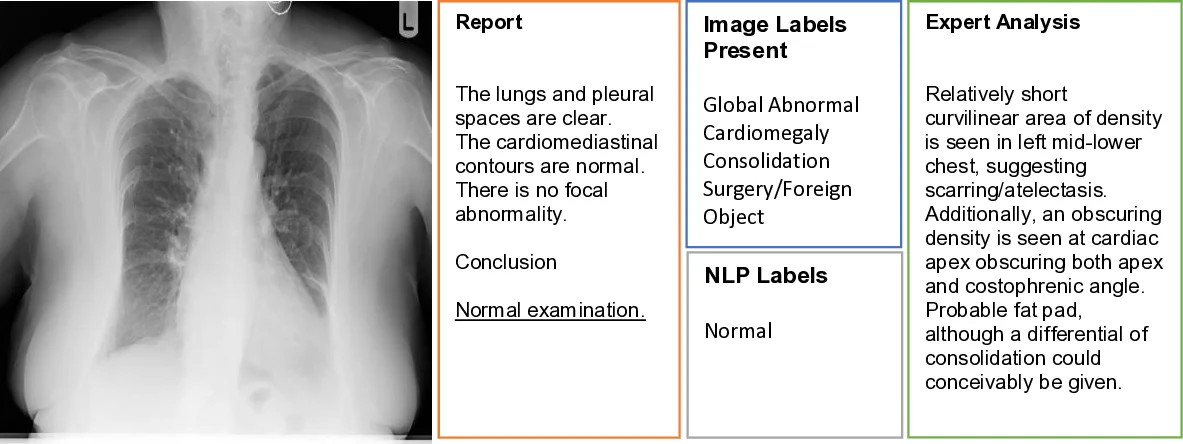
The paper investigates a critical, yet under‑examined, source of noise in medical imaging datasets that are built by automatically extracting labels from radiology reports using natural language processing (NLP). The authors assembled a challenging cohort of 1,000 chest X‑ray (CXR) studies drawn from a non‑screening clinical setting, each paired with its corresponding radiology report. Two board‑certified radiologists performed independent labeling in two distinct modes: (1) viewing only the images (producing the image‑based label set y_rad_img) and (2) viewing only the textual report (producing the report‑based label set y_rad_txt). Both annotators recorded the presence or absence of four abnormality categories—Global Abnormal (ABN 1), Cardiomegaly (ABN 2), Consolidation (ABN 3), and Foreign Body/Medical Device (ABN 4).
A quantitative comparison revealed a surprisingly large disagreement between the two labeling modalities. While the Global Abnormal label achieved an F1 score of 0.69 (the highest among the four categories), the other three categories suffered from markedly lower agreement (F1 = 0.17 for Cardiomegaly, 0.45 for Consolidation, and 0.59 for Foreign Body/Device). The authors attribute most of this gap to “clinically non‑actionable” findings—such as stable medical devices, age‑related degenerative changes, or prior‑study findings—that radiologists routinely omit from the narrative report because they do not affect immediate patient management. Additionally, borderline or nuanced findings (e.g., borderline cardiomegaly) are interpreted inconsistently: the image‑based reader may deem them insignificant, whereas the report‑based reader may mention them out of caution.
To assess the performance of state‑of‑the‑art medical NLP, the authors applied the CheXpert‑style extraction pipeline (Irvin et al., 2019) to the same reports, generating an automated label set y_nlp_txt. When benchmarked against the report‑based human labels, the NLP system achieved high precision (0.81) and recall (0.86) for the Global Abnormal category, but its performance collapsed for the other three categories (precision ranging from 0.13 to 0.24, recall from 0.38 to 0.86). This pattern mirrors the underlying human discrepancy: the NLP can only be as good as the source text, and the source text itself frequently omits or ambiguously describes the findings that are evident on the image.
A detailed failure analysis of the 1,000 cases uncovered that 239 reports (24 %) were labeled “normal” despite the image reader identifying at least one abnormality, while 194 reports (20 %) were labeled “abnormal” though the image reader found none. The authors examined a subset of these discordant cases and identified four principal sources of error:
- Non‑actionable findings – radiologists often exclude stable devices, prior‑study unchanged findings, or age‑related anatomic variations from the report, yet these are still present on the image and therefore constitute valid training signals for AI.
- Borderline or nuanced findings – subtle consolidations or mild cardiomegaly sit near the decision threshold, leading to divergent interpretations between the image‑focused and report‑focused readers.
- Anatomic and technical variability – patient positioning, inspiratory effort, body habitus, overlying structures, and acquisition artifacts can obscure or mimic pathology, increasing the chance that a finding is either missed or over‑reported.
- Human fatigue or oversight – occasional outright misses or misinterpretations were observed, underscoring the need for systematic quality control.
The authors argue that these discrepancies constitute a form of label noise that directly propagates into supervised learning pipelines, potentially degrading model performance, especially for modalities like chest X‑ray that already suffer from low specificity. They propose several practical recommendations for future dataset construction:
- Dual‑mode expert labeling: combine image‑based annotations from multiple radiologists with report‑based annotations to create a more reliable “gold standard.”
- Explicit meta‑labeling of non‑actionable and borderline findings: treat such findings as separate categories rather than discarding them, allowing models to learn nuanced representations.
- Use NLP as a verification tool rather than a primary label source: employ automated extraction to flag inconsistencies and assist human reviewers, rather than trusting it as the sole ground truth.
- Continuous quality monitoring: implement regular inter‑rater agreement checks, error audits, and statistical monitoring of label distributions to catch systematic drifts.
In conclusion, the study demonstrates that the prevailing assumption—“radiology reports provide accurate ground truth for image labeling”—is flawed. Automatic NLP extraction inherits the incompleteness and bias of the reports, leading to substantial gaps between the labels used for training and the true visual findings. Addressing this gap requires a more rigorous, multimodal annotation workflow that acknowledges the intrinsic limitations of report‑centric labeling and leverages both human expertise and NLP assistance in a complementary fashion.
Comments & Academic Discussion
Loading comments...
Leave a Comment