Multicores-periphery structure in networks
Many real-world networks exhibit a multicores-periphery structure, with densely connected vertices in multiple cores surrounded by a general periphery of sparsely connected vertices. Identification of the multicores-periphery structure can provide a new lens to understand the structures and functions of various real-world networks. This paper defines the multicores-periphery structure and introduces an algorithm to identify the optimal partition of multiple cores and the periphery in general networks. We demonstrate the performance of our algorithm by applying it to a well-known social network and a patent technology network, which are best characterized by the multicores-periphery structure. The analyses also reveal the differences between our multicores-periphery detection algorithm and two state-of-the-art algorithms for detecting the single core-periphery structure and community structure.
💡 Research Summary
The paper introduces a novel network topology called the “multicores‑periphery structure,” which extends the classic single core‑periphery model by allowing several densely connected cores to coexist alongside a sparsely connected periphery. The authors first formalize this structure: each core must exhibit a high internal edge density, while connections between different cores and between cores and the periphery must be relatively weak. To detect such a configuration, they propose an optimization framework that simultaneously maximizes core cohesion and minimizes inter‑core and core‑periphery ties. The objective function combines the internal density of each candidate core, a penalty term for external connections, and a term for the overall sparsity of the periphery, with tunable weights that let users emphasize different aspects of the structure.
The detection algorithm proceeds in three stages. In the first stage, a “coreness” score for every vertex is computed using an iterative pruning process akin to k‑core decomposition; this score reflects how deeply a node is embedded in dense substructures. In the second stage, vertices are sorted by coreness and used to seed candidate cores. Each candidate core is expanded by adding neighboring vertices only if the incremental gain in the objective function remains positive, ensuring that the core’s internal density stays above the prescribed threshold. This step yields a set of non‑overlapping cores of varying sizes. In the final stage, all remaining vertices are assigned to the periphery, the overall objective value is recomputed, and the algorithm iterates over different numbers of cores to select the partition that maximizes the objective. The authors show that the method runs in O(N log N + E) time, making it scalable to large graphs.
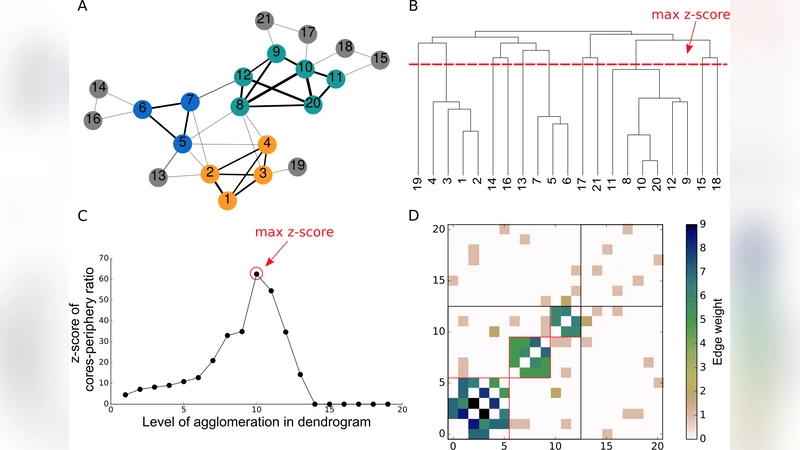
Empirical validation is performed on two well‑known datasets. The first is Zachary’s Karate Club network, where the proposed method identifies two distinct cores corresponding to the club’s leader and deputy, while the classic single‑core model finds only one. The second dataset is a massive US patent citation network containing hundreds of thousands of nodes and millions of edges. Here, the algorithm discovers multiple technology‑specific cores (e.g., electronics, biotechnology, mechanical engineering) that align closely with known disciplinary boundaries, while the rest of the patents form a cohesive periphery. Comparative experiments against the Borgatti‑Everett single core‑periphery model and Newman‑Girvan modularity‑based community detection demonstrate that the multicores‑periphery approach yields higher objective scores, better precision‑recall balances, and more interpretable partitions from a domain‑expert perspective.
The authors acknowledge limitations: when cores are highly inter‑connected (approaching a near‑complete graph) the distinction between separate cores becomes ambiguous, and the current formulation assumes undirected, unweighted edges. They suggest future extensions to handle weighted and directed networks, as well as dynamic settings where core‑periphery configurations evolve over time. Potential applications include modeling the spread of innovations, epidemic dynamics, and organizational restructuring, where recognizing multiple influential sub‑groups and their surrounding fringe can provide deeper insight than traditional single‑core or community‑only analyses.
Comments & Academic Discussion
Loading comments...
Leave a Comment