Speeding up Deep Learning with Transient Servers
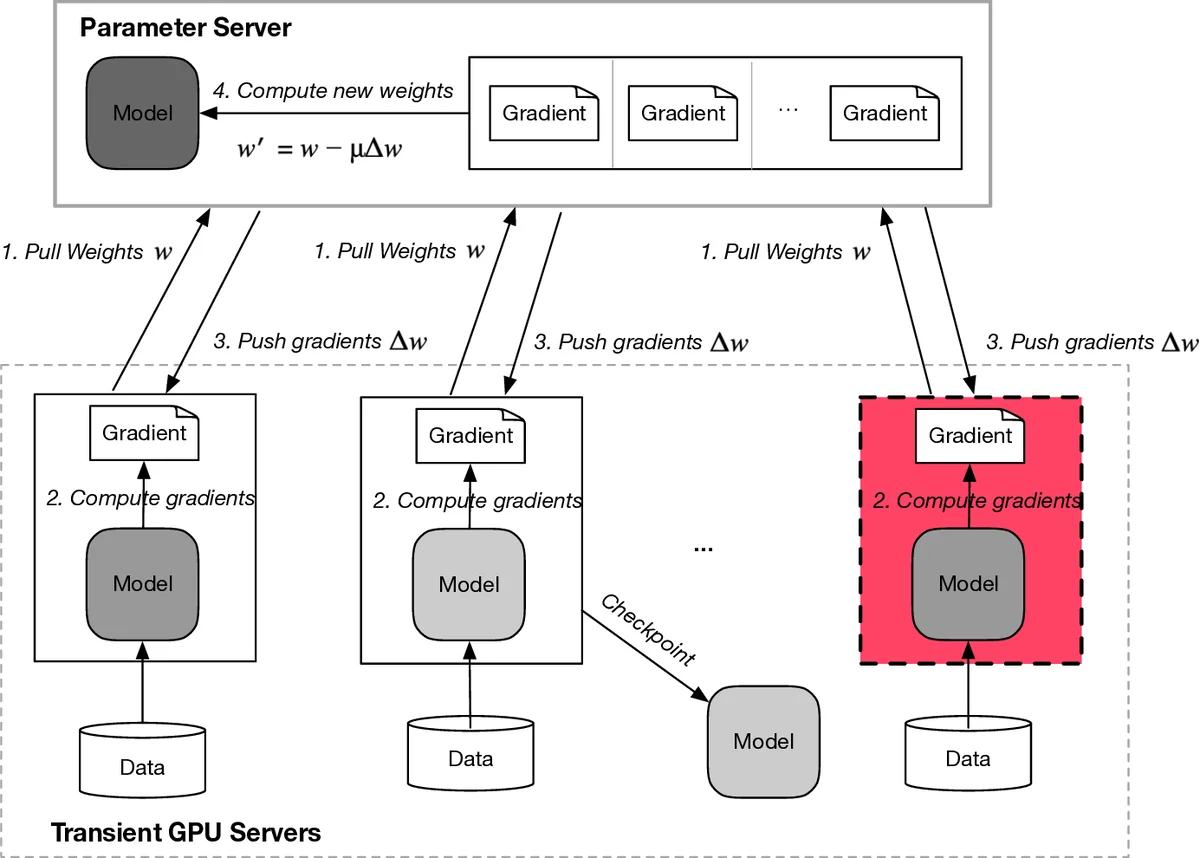
Distributed training frameworks, like TensorFlow, have been proposed as a means to reduce the training time of deep learning models by using a cluster of GPU servers. While such speedups are often desirable—e.g., for rapidly evaluating new model designs—they often come with significantly higher monetary costs due to sublinear scalability. In this paper, we investigate the feasibility of using training clusters composed of cheaper transient GPU servers to get the benefits of distributed training without the high costs. We conduct the first large-scale empirical analysis, launching more than a thousand GPU servers of various capacities, aimed at understanding the characteristics of transient GPU servers and their impact on distributed training performance. Our study demonstrates the potential of transient servers with a speedup of 7.7X with more than 62.9% monetary savings for some cluster configurations. We also identify a number of important challenges and opportunities for redesigning distributed training frameworks to be transient-aware. For example, the dynamic cost and availability characteristics of transient servers suggest the need for frameworks to dynamically change cluster configurations to best take advantage of current conditions.
💡 Research Summary
This paper, “Speeding up Deep Learning with Transient Servers,” investigates a cost-effective paradigm for distributed deep learning by leveraging cheap but revocable cloud resources known as transient servers (e.g., AWS Spot Instances, Google Preemptible VMs). The core premise is that while distributed training frameworks like TensorFlow accelerate model training using GPU clusters, the high cost of on-demand servers often limits accessibility. Transient servers offer significant discounts (up to 90%) but introduce uncertainty, as the cloud provider can revoke them at any time.
The authors conduct the first large-scale empirical analysis, launching over a thousand GPU servers on Google Compute Engine (GCE), to understand the characteristics of transient servers and their impact on training performance. The key experiment involves training a ResNet-32 model on the CIFAR-10 dataset, comparing three setups: a single on-demand K80 GPU server, a cluster of four on-demand K80s, and a cluster of four transient K80s. The results demonstrate the compelling potential of transient servers: the 4-transient-server cluster achieved an average 3.72X speedup and 62.9% monetary savings compared to the single on-demand baseline. When no revocations occurred, the performance of transient clusters was nearly identical to that of on-demand clusters.
The study provides a detailed quantification of revocation impacts. Out of 32 transient clusters launched, 21 completed with zero revocations, 8 experienced one revocation, and 2 experienced two revocations. Training time increased with the number of revocations (from 0.98 hours to 1.45 hours in the worst case), but the asynchronous parameter-server architecture prevented total training failure. The paper also analyzes the lifetime distribution of GCE preemptible VMs, finding that while most last the full 24-hour maximum, a significant portion (≈20%) are revoked within the first two hours.
Beyond performance comparisons, the paper identifies fundamental challenges and opportunities for system redesign. The dynamic cost, availability, and uncertain lifetime of transient servers expose limitations in current distributed training frameworks, which assume stable, homogeneous resources. The authors argue for new “transient-aware” frameworks capable of:
- Dynamically adjusting cluster size and composition in response to fluctuating prices and availability.
- Supporting heterogeneous clusters with servers of different types (e.g., mixing K80, P100, V100) and from different geographic regions.
- Incorporating more robust fault-tolerance mechanisms, especially for master worker failures critical for checkpointing.
- Exploring policies like selective revocation, where cloud providers could consider the training phase before revoking a server.
In conclusion, the research proves that transient servers are a viable and powerful resource for dramatically reducing the cost of distributed deep learning while maintaining performance. It shifts the focus from static, expensive clusters to dynamic, cost-optimized resource pools, calling for a significant re-architecture of training systems to fully harness this potential, thereby making large-scale model training more accessible and economically efficient.
Comments & Academic Discussion
Loading comments...
Leave a Comment