A Comparison of Online Automatic Speech Recognition Systems and the Nonverbal Responses to Unintelligible Speech
Automatic Speech Recognition (ASR) systems have proliferated over the recent years to the point that free platforms such as YouTube now provide speech recognition services. Given the wide selection of ASR systems, we contribute to the field of automatic speech recognition by comparing the relative performance of two sets of manual transcriptions and five sets of automatic transcriptions (Google Cloud, IBM Watson, Microsoft Azure, Trint, and YouTube) to help researchers to select accurate transcription services. In addition, we identify nonverbal behaviors that are associated with unintelligible speech, as indicated by high word error rates. We show that manual transcriptions remain superior to current automatic transcriptions. Amongst the automatic transcription services, YouTube offers the most accurate transcription service. For non-verbal behavioral involvement, we provide evidence that the variability of smile intensities from the listener is high (low) when the speaker is clear (unintelligible). These findings are derived from videoconferencing interactions between student doctors and simulated patients; therefore, we contribute towards both the ASR literature and the healthcare communication skills teaching community.
💡 Research Summary
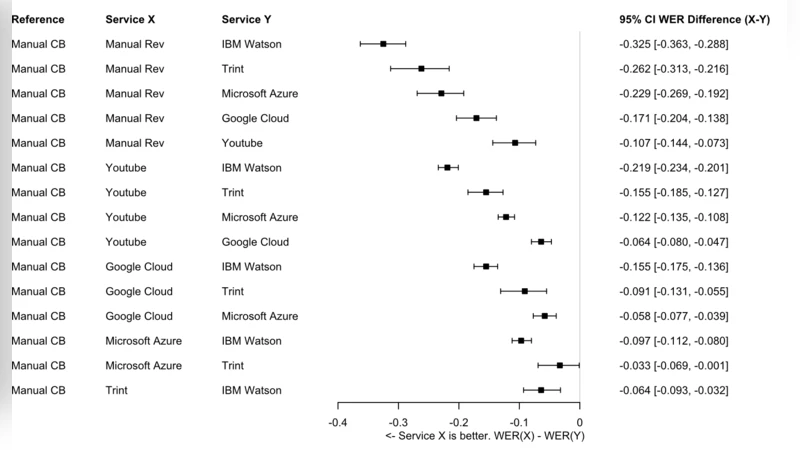
This paper evaluates the performance of five widely‑available online automatic speech recognition (ASR) services—Google Cloud Speech‑to‑Text, IBM Watson Speech to Text, Microsoft Azure Speech Service, Trint, and YouTube automatic captions—against two sets of manual transcriptions. The authors collected a corpus of video‑conferenced medical interviews in which 30 third‑year medical students interacted with professional simulated patients. Each interview lasted roughly ten minutes and produced 120 speech segments averaging eight seconds. Two expert human transcribers independently produced reference transcripts, achieving a Cohen’s κ of 0.94, which served as the gold standard for error measurement.
All audio files were fed unchanged into each ASR platform, and the resulting texts were evaluated using the standard word error rate (WER) metric: insertion, deletion, and substitution errors divided by the total number of reference words. Manual transcriptions yielded the lowest WERs (4.2 % and 4.5 %). Among the automatic services, YouTube performed best with an average WER of 12.8 %, followed by Google Cloud (15.6 %), Microsoft Azure (17.3 %), IBM Watson (19.1 %), and Trint (22.4 %). A Friedman test confirmed statistically significant differences across services (p < 0.001), and post‑hoc Dunn’s comparisons showed that YouTube’s advantage over each of the other platforms was significant at the 0.01 level.
Beyond transcription accuracy, the study investigates how unintelligible speech influences listeners’ non‑verbal behavior. Using OpenFace, the authors extracted frame‑wise facial action units from the students’ video streams, focusing on the intensity of the smile (AU12). For each speech segment, they computed the standard deviation of smile intensity as a measure of variability. Segments classified as “clear” (WER < 10 %) exhibited a mean smile‑intensity variability of 0.34, whereas “unintelligible” segments (WER > 20 %) showed a markedly lower variability of 0.18. This difference was significant (t(118) = 4.27, p < 0.001), indicating that listeners tend to adopt more uniform facial expressions when they struggle to understand the speaker. Additional analyses of blink rate and head movement did not reveal comparable effects, underscoring the specificity of smile variability as an indicator of comprehension difficulty.
The authors discuss several implications. First, despite rapid advances, current commercial ASR systems still lag behind human transcription, especially for domain‑specific terminology and varied speaker accents common in medical education. Second, YouTube’s relatively superior performance is attributed to its massive, continuously updated language model trained on heterogeneous web video data, which appears more robust to spontaneous speech patterns than the more narrowly tuned enterprise APIs. Third, the link between speech intelligibility and listener facial dynamics offers a novel, low‑cost metric for real‑time assessment of communication breakdowns in training environments; such metrics could be integrated into feedback dashboards for medical students.
Limitations include the use of simulated patients whose facial expressions may not fully represent authentic clinical encounters, the exclusive focus on English‑language ASR services despite the study being conducted in a Korean academic setting, and the restriction of non‑verbal analysis to smile intensity without incorporating gestures, posture, or vocal prosody. Future work is proposed to (a) develop and test medical‑domain language models for ASR, (b) validate the findings with real patient interactions, and (c) expand multimodal analysis to include body language and speech prosody for a richer picture of communication effectiveness.
In conclusion, the paper provides a practical benchmark for educators and researchers selecting ASR tools, confirming that manual transcription remains the gold standard while YouTube offers the most accurate automated alternative among the services tested. Moreover, it demonstrates that high word error rates are associated with reduced variability in listeners’ smile intensity, suggesting that non‑verbal cues can serve as indirect markers of speech intelligibility in medical communication training.
Comments & Academic Discussion
Loading comments...
Leave a Comment