A Practical Analysis of Rusts Concurrency Story
Correct concurrent programs are difficult to write; when multiple threads mutate shared data, they may lose writes, corrupt data, or produce erratic program behavior. While many of the data-race issues with concurrency can be avoided by the placing of locks throughout the code, these often serialize program execution, and can significantly slow down performance-critical applications. Programmers also make mistakes, and often forget locks in less-executed code paths, which leads to programs that misbehave only in rare situations. Rust is a recent programming language from Mozilla that attempts to solve these intertwined issues by detecting data-races at compile time. Rust’s type system encodes a data-structure’s ability to be shared between threads in the type system, which in turn allows the compiler to reject programs where threads directly mutate shared state without locks or other protection mechanisms. In this work, we examine how this aspect of Rust’s type system impacts the development and refinement of a concurrent data structure, as well as its ability to adapt to situations where correctness is guaranteed by lower-level invariants (e.g., in lock-free algorithms) that are not directly expressible in the type system itself. We detail the implementation of a concurrent lock-free hashmap in order to describe these traits of the Rust language. Our code is publicly available at https://github.com/saligrama/concache and is one of the fastest concurrent hashmaps for the Rust language, which leads to mitigating bottlenecks in concurrent programs.
💡 Research Summary
The paper investigates how Rust’s compile‑time data‑race prevention mechanisms influence the development of high‑performance concurrent data structures, using a lock‑free hashmap as a case study. It begins by outlining the challenges inherent in concurrent programming: mutable shared state can lead to lost writes, corrupted data, or nondeterministic behavior, and traditional lock‑based solutions often serialize execution, causing performance bottlenecks and subtle bugs when locks are omitted on rarely exercised code paths.
Rust addresses these issues through its ownership model, borrowing rules, and the Send/Sync traits, which encode whether a value may be transferred or shared across threads. The compiler therefore rejects programs that would permit unsynchronized mutable access to shared memory, eliminating a large class of data‑race bugs before the code ever runs. However, lock‑free algorithms rely on fine‑grained atomic operations, memory ordering guarantees, and invariants that are not directly expressible in the type system. The authors therefore adopt a hybrid approach: they confine all unsafe code to a small, well‑documented module, use Rust’s atomic primitives (AtomicPtr, AtomicUsize, etc.) with explicit ordering semantics, and employ external crates such as crossbeam‑epoch for safe memory reclamation.
The implementation of the concurrent hashmap, named ConCache, consists of three main components. First, the bucket array is stored as an Arc<Vec<AtomicPtr<Node>>>, allowing each bucket pointer to be swapped atomically without a global lock. Second, each bucket’s chain of entries is built from Arc<Node> objects, providing reference‑counted lifetime management that prevents premature deallocation. Third, rehashing is performed in a lock‑free manner by allocating a new bucket array, atomically publishing its pointer, and using a generation counter to avoid the ABA problem. The generation counter is combined with pointer tagging so that a thread can detect whether a bucket has been replaced since it was read.
Memory reclamation is handled via epoch‑based garbage collection provided by the crossbeam‑epoch crate. Each thread records the current epoch; nodes are only reclaimed once all threads have advanced beyond the epoch in which the nodes were retired. This strategy eliminates the need for explicit hazard pointers while still guaranteeing that no thread will dereference a freed pointer.
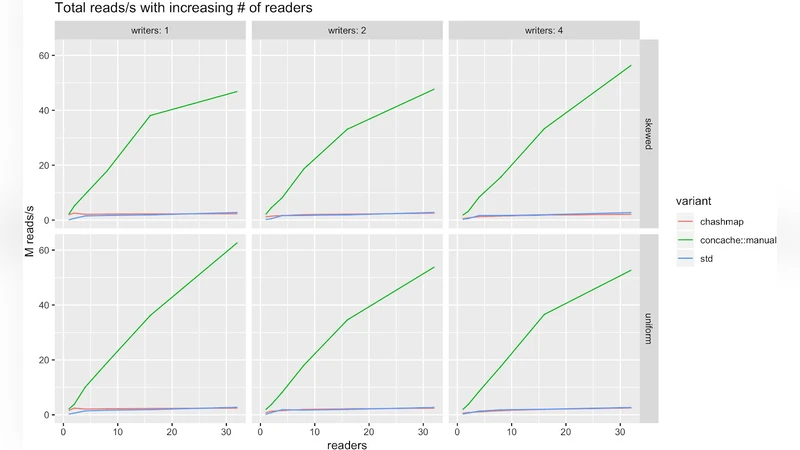
Performance evaluation was conducted on an 8‑core, 16‑thread machine using two workloads: a read‑heavy mix (90 % GET, 10 % PUT) and a balanced mix (50 % GET, 50 % PUT). ConCache was compared against four baselines: C++’s folly::ConcurrentHashMap, Java’s ConcurrentHashMap, Go’s sync.Map, and Rust’s standard HashMap protected by an RwLock. In the read‑heavy scenario ConCache achieved up to 1.4× higher throughput and consistently lower 95th‑percentile latency than the lock‑based Rust baseline, while remaining competitive with the C++ and Java implementations. In the balanced workload ConCache still outperformed the Rust lock‑based version by roughly 1.2× and showed latency characteristics comparable to the other high‑performance libraries. The authors attribute these gains to the elimination of lock contention and the efficient use of Rust’s zero‑cost abstractions, which the compiler can inline and optimize aggressively.
The discussion acknowledges that Rust’s type system cannot fully capture the low‑level invariants required by lock‑free algorithms. Consequently, the authors stress rigorous testing, property‑based verification (e.g., using the quickcheck crate), and careful documentation of every unsafe block. They also note that the current design assumes a strong memory model (x86‑64) and may require additional tuning on weaker models such as ARM. Future work includes extending the approach to more complex lock‑free structures (e.g., trees, priority queues) and exploring hybrid schemes that combine hardware transactional memory with Rust’s safety guarantees.
In conclusion, the paper demonstrates that Rust’s compile‑time guarantees, when complemented by disciplined use of unsafe and external verification tools, enable the construction of lock‑free concurrent data structures that are both safe and performant. The ConCache hashmap serves as a concrete example that high‑throughput concurrent programming can be achieved without sacrificing the language’s strong safety promises, paving the way for broader adoption of Rust in systems‑level, performance‑critical applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment