Masked Conditional Neural Networks for Environmental Sound Classification
The ConditionaL Neural Network (CLNN) exploits the nature of the temporal sequencing of the sound signal represented in a spectrogram, and its variant the Masked ConditionaL Neural Network (MCLNN) induces the network to learn in frequency bands by embedding a filterbank-like sparseness over the network’s links using a binary mask. Additionally, the masking automates the exploration of different feature combinations concurrently analogous to handcrafting the optimum combination of features for a recognition task. We have evaluated the MCLNN performance using the Urbansound8k dataset of environmental sounds. Additionally, we present a collection of manually recorded sounds for rail and road traffic, YorNoise, to investigate the confusion rates among machine generated sounds possessing low-frequency components. MCLNN has achieved competitive results without augmentation and using 12% of the trainable parameters utilized by an equivalent model based on state-of-the-art Convolutional Neural Networks on the Urbansound8k. We extended the Urbansound8k dataset with YorNoise, where experiments have shown that common tonal properties affect the classification performance.
💡 Research Summary
The paper introduces a novel deep learning architecture called the Masked Conditional Neural Network (MCLNN) for environmental sound classification. Traditional approaches such as Deep Belief Networks (DBNs) treat each spectrogram frame as an independent sample, thereby ignoring temporal continuity, while Convolutional Neural Networks (CNNs) rely on weight sharing that can diminish the locality of frequency‑specific features. To address these shortcomings, the authors first develop a Conditional Neural Network (CLNN) that extends the Conditional Restricted Boltzmann Machine (CRBM) concept. CLNN processes a sliding window of 2n + 1 frames: the central frame serves as the current output, and the n preceding and n succeeding frames are linked to the hidden layer through distinct weight matrices (or a weight tensor). This conditional wiring captures inter‑frame dependencies and reduces the number of frames passed to deeper layers by a factor of two, preserving temporal context without excessive computational cost.
MCLNN builds on CLNN by imposing a binary mask on the weight matrices, thereby emulating a filter‑bank behavior. The mask is defined by two hyper‑parameters: band width (bw) and overlap (ov). Each row of the mask contains bw consecutive ones; the start column of each subsequent row is shifted by ov positions. Elements corresponding to zeros are multiplied out (element‑wise) so that the associated weights are permanently disabled. Consequently, each hidden neuron learns from a specific frequency band, enforcing systematic sparsity, reducing the total number of trainable parameters, and preserving spatial locality in the spectrogram domain. By varying bw and ov, the network can automatically explore many different band configurations, effectively performing a form of automated feature‑combination search that would otherwise require manual engineering.
The authors evaluate MCLNN on two datasets. The first is UrbanSound8K, a widely used benchmark containing 8,732 audio clips across ten environmental sound classes. Using a two‑layer MCLNN with n = 1, bw = 5, and ov = 3, they achieve classification accuracy comparable to or slightly better than state‑of‑the‑art CNN models, while using only about 12 % of the trainable parameters of those CNNs. No data augmentation is employed, highlighting the efficiency of the architecture.
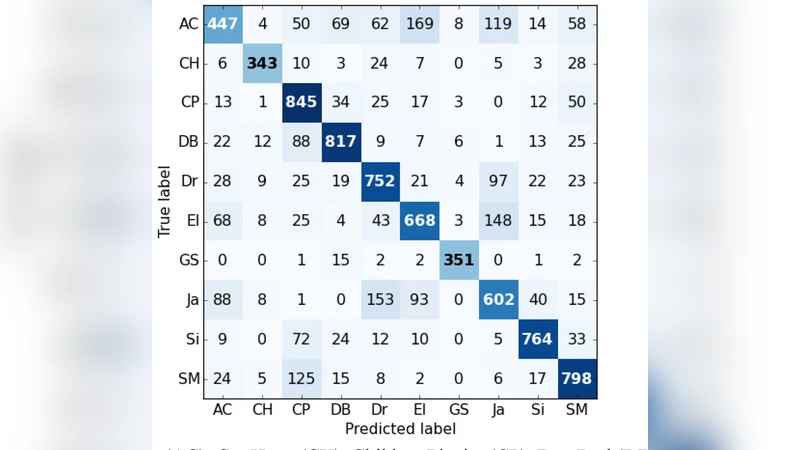
The second evaluation employs a newly recorded dataset named YorNoise, which consists of rail and road traffic sounds dominated by low‑frequency components. This dataset is designed to probe the confusion that arises when machine‑generated sounds share similar tonal characteristics. Experiments reveal that MCLNN’s band‑focused learning reduces some of the confusion caused by overlapping low‑frequency energy, yet classification errors persist when tonal similarity is high, indicating that further refinement of band selection or additional temporal modeling may be needed.
Key contributions of the work are: (1) a conditional neural network framework that explicitly models temporal dependencies in spectrograms, (2) a mask‑based mechanism that enforces filter‑bank‑like sparsity and enables automatic exploration of feature combinations, (3) a parameter‑efficient model that attains competitive performance without augmentation, and (4) the introduction of the YorNoise dataset, providing a new benchmark for low‑frequency environmental sound classification. The authors suggest future directions such as learning the mask parameters jointly with the network, employing multi‑scale masks, or integrating recurrent units to capture longer‑range temporal patterns. Overall, MCLNN demonstrates that carefully designed sparsity and temporal conditioning can yield compact yet powerful models for audio scene analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment