Meta-Sim: Learning to Generate Synthetic Datasets
Training models to high-end performance requires availability of large labeled datasets, which are expensive to get. The goal of our work is to automatically synthesize labeled datasets that are relevant for a downstream task. We propose Meta-Sim, which learns a generative model of synthetic scenes, and obtain images as well as its corresponding ground-truth via a graphics engine. We parametrize our dataset generator with a neural network, which learns to modify attributes of scene graphs obtained from probabilistic scene grammars, so as to minimize the distribution gap between its rendered outputs and target data. If the real dataset comes with a small labeled validation set, we additionally aim to optimize a meta-objective, i.e. downstream task performance. Experiments show that the proposed method can greatly improve content generation quality over a human-engineered probabilistic scene grammar, both qualitatively and quantitatively as measured by performance on a downstream task.
💡 Research Summary
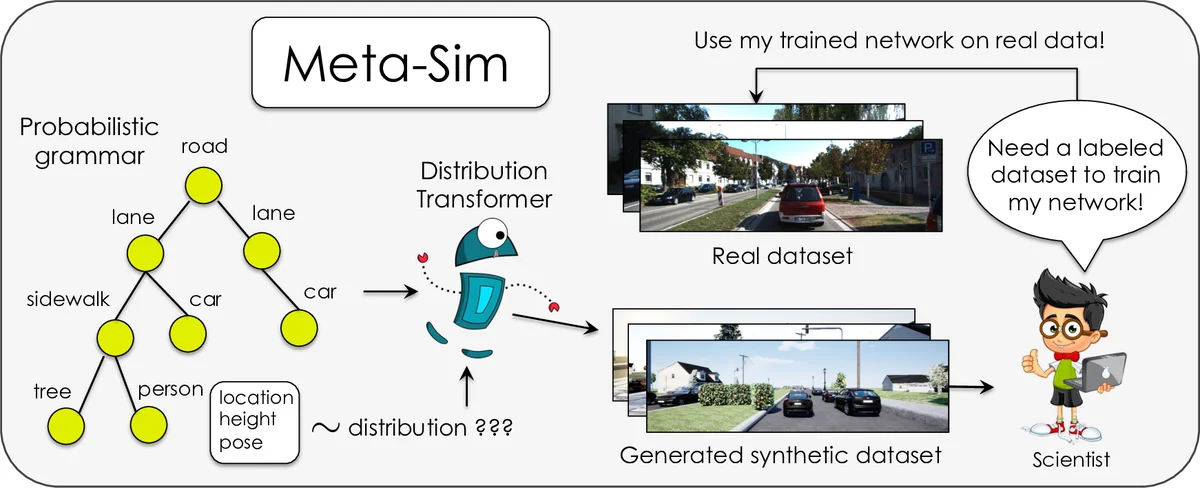
Meta‑Sim addresses the costly bottleneck of acquiring large labeled datasets by automatically generating synthetic datasets that are tailored to a downstream task. The method builds on a probabilistic scene grammar that can sample valid scene graphs (structures such as roads, cars, sidewalks, etc.). A Graph Convolutional Network, called the Distribution Transformer (Gθ), takes each sampled graph and modifies a selected subset of node attributes (e.g., object positions, orientations, colors, asset IDs) while preserving the overall graph topology. The transformed graph is then fed to a graphics engine (renderer R) which produces an image and perfect pixel‑level ground truth (segmentation masks, bounding boxes, etc.).
Training proceeds in three stages. First, an auto‑encoder loss forces Gθ to behave like an identity function, stabilizing its parameters by reconstructing the original attributes (cross‑entropy for categorical fields, L1 for continuous fields). Second, a distribution‑matching loss aligns the rendered synthetic images with real images using Maximum Mean Discrepancy (MMD) computed in the feature space of an Inception‑V3 network (i.e., the Kernel Inception Distance). MMD is chosen over adversarial losses to avoid mode collapse and to provide stable gradients despite the non‑differentiable renderer; gradient estimates are obtained via sampling‑based techniques or differentiable rendering wrappers.
When a small labeled validation set V from the real domain is available, Meta‑Sim adds a meta‑objective: it trains a downstream Task Network (TN) on the synthetic dataset D(θ) and evaluates its performance on V. The final loss is a weighted sum of the MMD term and the task loss on V, allowing the system to directly optimize for downstream performance while still reducing the content gap.
Experiments are conducted on two controlled toy simulators and on a real autonomous‑driving benchmark. In toy settings, Meta‑Sim dramatically reduces MMD and improves visual fidelity compared to the unmodified grammar. On the driving dataset, adapting a baseline SDR‑style grammar with Meta‑Sim yields a 4–6 % absolute increase in mean Average Precision for object detection and noticeable gains for lane‑estimation tasks, even when the validation set contains only a few hundred images. Qualitative user studies also report higher realism scores for scenes generated by Meta‑Sim.
Key contributions are: (1) explicit modeling and minimization of the content gap between synthetic and real data; (2) a graph‑based attribute transformer that preserves perfect ground truth while learning realistic attribute distributions; (3) integration of a meta‑learning objective that directly optimizes downstream task performance; and (4) a practical training pipeline that works with non‑differentiable renderers using MMD‑based distribution matching. The approach is orthogonal to appearance‑style adaptation methods and can be combined with them for further gains. Limitations include the computational cost of rendering large batches and the need to pre‑define which attributes are mutable, which still requires domain expertise. Future work may explore multi‑task meta‑optimization and fully differentiable rendering pipelines. Overall, Meta‑Sim demonstrates that automatically tuned synthetic data generators can close the gap to real data and substantially improve the performance of models trained on synthetic data.
Comments & Academic Discussion
Loading comments...
Leave a Comment