Latent Class Model with Application to Speaker Diarization
In this paper, we apply a latent class model (LCM) to the task of speaker diarization. LCM is similar to Patrick Kenny’s variational Bayes (VB) method in that it uses soft information and avoids premature hard decisions in its iterations. In contrast to the VB method, which is based on a generative model, LCM provides a framework allowing both generative and discriminative models. The discriminative property is realized through the use of i-vector (Ivec), probabilistic linear discriminative analysis (PLDA), and a support vector machine (SVM) in this work. Systems denoted as LCM-Ivec-PLDA, LCM-Ivec-SVM, and LCM-Ivec-Hybrid are introduced. In addition, three further improvements are applied to enhance its performance. 1) Adding neighbor windows to extract more speaker information for each short segment. 2) Using a hidden Markov model to avoid frequent speaker change points. 3) Using an agglomerative hierarchical cluster to do initialization and present hard and soft priors, in order to overcome the problem of initial sensitivity. Experiments on the National Institute of Standards and Technology Rich Transcription 2009 speaker diarization database, under the condition of a single distant microphone, show that the diarization error rate (DER) of the proposed methods has substantial relative improvements compared with mainstream systems. Compared to the VB method, the relative improvements of LCM-Ivec-PLDA, LCM-Ivec-SVM, and LCM-Ivec-Hybrid systems are 23.5%, 27.1%, and 43.0%, respectively. Experiments on our collected database, CALLHOME97, CALLHOME00 and SRE08 short2-summed trial conditions also show that the proposed LCM-Ivec-Hybrid system has the best overall performance.
💡 Research Summary
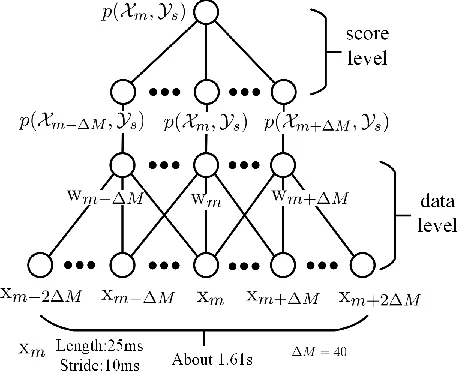
This paper introduces a latent class model (LCM) for speaker diarization, positioning it as a flexible alternative to the widely used variational Bayes (VB) approach. While VB relies on a generative model and a single objective of maximizing the overall likelihood, LCM treats the joint probability of a short audio segment (Xₘ), a latent speaker class (Yₛ), and a binary indicator (iₘₛ) as a unified framework. The authors derive an iterative optimization that alternates three steps: (1) updating the posterior qₘₛ = p(iₘₛ | Xₘ, Yₛ) using Jensen’s inequality, (2) re‑estimating the speaker representation Yₛ given qₘₛ, and (3) recomputing p(Xₘ, Yₛ | iₘₛ) to feed back into step 1. This loop mirrors the E‑M style of VB but crucially allows the term p(Xₘ, Yₛ) to be modeled discriminatively rather than generatively.
Three concrete LCM variants are built:
- LCM‑Ivec‑PLDA uses i‑vectors and probabilistic linear discriminant analysis (PLDA) scores as p(Xₘ, Yₛ).
- LCM‑Ivec‑SVM replaces PLDA with a linear support vector machine trained on i‑vectors, using the SVM decision function as the likelihood surrogate.
- LCM‑Ivec‑Hybrid combines PLDA and SVM scores via weighted averaging, aiming to capture both generative similarity and discriminative boundaries.
To mitigate three known weaknesses of VB—(i) poor handling of very short segments, (ii) sensitivity to initialization, and (iii) lack of temporal smoothing—the authors add three enhancements:
- Neighbor windows: each segment’s feature vector is augmented with its immediate temporal neighbors, providing richer contextual information.
- Hidden Markov Model (HMM) smoothing: transition probabilities between speaker states are modeled with an HMM, and Viterbi or forward‑backward decoding is applied to suppress spurious rapid speaker changes.
- Agglomerative hierarchical clustering (AHC) initialization: hard and soft priors derived from an AHC run are used to seed qₘₛ and Yₛ, reducing the algorithm’s dependence on random starts.
Experiments are conducted primarily on the NIST Rich Transcription 2009 (RT‑09) dataset under the single distant microphone (SDM) condition, with additional evaluations on CALLHOME97, CALLHOME00, and SRE08 short‑2‑summed trials. Relative diarization error rate (DER) improvements over a strong VB baseline are reported as 23.5 % for LCM‑Ivec‑PLDA, 27.1 % for LCM‑Ivec‑SVM, and a striking 43.0 % for the hybrid system. Across the CALLHOME and SRE08 conditions, the hybrid model consistently achieves the lowest DER, especially in scenarios with imbalanced speaker participation.
The paper’s contributions can be summarized as follows:
- Framework flexibility: LCM decouples the diarization objective from a purely generative model, enabling seamless integration of discriminative classifiers such as PLDA and SVM.
- Robustness to short segments: Neighbor‑window augmentation and HMM smoothing jointly address the unreliability of per‑segment likelihoods that plague VB.
- Initialization stability: Using AHC‑derived priors mitigates the well‑known sensitivity of soft‑clustering methods to random initialization.
- Empirical validation: Comprehensive experiments demonstrate that LCM‑Hybrid outperforms state‑of‑the‑art VB and other mainstream systems, delivering substantial DER reductions in both controlled (RT‑09 SDM) and more realistic (CALLHOME, SRE08) environments.
The authors discuss related work, noting that while VB already introduced soft decisions, it remains constrained by its generative nature. Their LCM approach bridges the gap between generative and discriminative paradigms, offering a more versatile tool for diarization pipelines. They also acknowledge limitations: the current study assumes the number of speakers is known a priori, and the experiments focus on single‑channel audio. Future directions include extending LCM to multi‑channel (MDM) settings, handling unknown speaker counts via Bayesian model selection, and integrating end‑to‑end deep acoustic embeddings to replace i‑vectors. Overall, the paper presents a compelling case that latent class modeling, enriched with discriminative scoring and temporal regularization, can substantially advance speaker diarization performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment